







Mejores Bibliotecas de Scraping Web 2026

Aloísio Vítor
Image Processing Expert
12-Jan-2026

Puntos clave
- Python es el lenguaje líder para el scraping web debido a su facilidad de uso, bibliotecas extensas y fuerte soporte de la comunidad.
- Beautiful Soup es excelente para el análisis de HTML estático y para principiantes.
- Scrapy es un framework potente para proyectos de scraping a gran escala y complejos.
- Selenium y Playwright son esenciales para el scraping de sitios web dinámicos y con mucho JavaScript, controlando navegadores reales.
- Requests-HTML ofrece una combinación conveniente de recuperación, análisis y renderizado de JavaScript.
- Técnicas avanzadas como la resolución de CAPTCHA (usando servicios como CapSolver) y la gestión de proxies son cruciales para un scraping robusto.
- Las consideraciones éticas, incluyendo el respeto a
robots.txty los términos de servicio del sitio web, son primordiales.
Introducción
¿Sabías que el mercado global de análisis de datos se proyecta alcanzar los 655.8 mil millones de dólares para 2029, creciendo a una tasa anual compuesta del 12.9%? (Fuente: Grand View Research). Este crecimiento explosivo subraya la creciente importancia de la extracción de datos, y el scraping web en Python sigue siendo una pieza fundamental para acceder y analizar grandes cantidades de información en línea. Al mirar hacia 2026, el panorama de las bibliotecas de scraping web en Python continúa evolucionando, ofreciendo a los desarrolladores herramientas cada vez más potentes, eficientes y fáciles de usar.
Elegir la biblioteca adecuada puede tener un impacto significativo en el éxito de sus proyectos de scraping, afectando desde el tiempo de desarrollo hasta la robustez de sus raspadores. Esta guía explorará las principales bibliotecas de scraping web en Python que debe considerar en 2026, examinando sus fortalezas, debilidades y casos de uso ideales. Cubriremos desde opciones amigables para principiantes hasta marcos avanzados, asegurándonos de que tenga el conocimiento necesario para seleccionar la herramienta perfecta para sus necesidades de extracción de datos.
¿Por qué Python para el scraping web?
La dominancia de Python en el scraping web no es casual. Varios factores clave contribuyen a su popularidad:
- Simplicidad y legibilidad: La sintaxis clara de Python lo hace relativamente fácil de aprender y escribir, incluso para quienes no tienen experiencia en programación. Esto se traduce en ciclos de desarrollo más rápidos para proyectos de scraping.
- Bibliotecas y frameworks extensos: El ecosistema de Python es rico en bibliotecas específicamente diseñadas para el scraping web, manipulación de datos y análisis (por ejemplo, NumPy, Pandas). Esto significa que a menudo no necesita construir funcionalidades complejas desde cero.
- Comunidad grande y activa: Una gran comunidad significa recursos, tutoriales y soporte abundantes. Si se encuentra con un problema, es probable que alguien más ya lo haya resuelto y compartido la solución.
- Versatilidad: Python se puede usar para una amplia gama de tareas más allá del scraping, como análisis de datos, aprendizaje automático y desarrollo web, lo que lo convierte en una habilidad valiosa para profesionales de los datos.
Consideraciones clave al elegir una biblioteca de scraping web
Antes de adentrarse en bibliotecas específicas, es crucial comprender los factores que las diferencian:
1. Facilidad de uso
¿Qué tan rápido puede comenzar? Las bibliotecas con APIs más simples y documentación clara son ideales para principiantes o proyectos con plazos ajustados. Para proyectos complejos que requieren lógica intrincada, una biblioteca con más funcionalidades, aunque con una curva de aprendizaje más pronunciada, podría ser aceptable.
2. Funcionalidades y características
¿La biblioteca maneja contenido dinámico (páginas renderizadas con JavaScript)? ¿Soporta el manejo de CAPTCHAS o proxies? ¿Ofrece capacidades asíncronas para un scraping más rápido? Las características que necesite dependerán en gran medida de los sitios web que intente raspar.
3. Rendimiento y escalabilidad
Para operaciones de scraping a gran escala, el rendimiento es fundamental. Las bibliotecas que pueden manejar muchas solicitudes simultáneamente o procesar grandes cantidades de datos de manera eficiente serán más adecuadas. La programación asíncrona y la gestión eficiente de la memoria son clave aquí.
4. Soporte de la comunidad y documentación
Una buena documentación y una comunidad activa son invaluable. Proporcionan ayuda cuando se queda atascado y aseguran que la biblioteca esté mantenida y actualizada.
5. Manejo de medidas anti-scraping
Muchos sitios web emplean medidas para bloquear a los raspadores. Su biblioteca elegida debería ofrecer características o integrarse bien con herramientas que puedan ayudar a evitar estas restricciones, como la rotación de proxies, el spoofing de agentes de usuario y servicios de resolución de CAPTCHA.
Las principales bibliotecas de scraping web en Python para 2026
Exploraremos los principales contendientes que están destinados a dominar la escena del scraping web en 2026.
1. Beautiful Soup
Beautiful Soup es probablemente la biblioteca más popular y ampliamente utilizada en Python para analizar documentos HTML y XML. Crea un árbol de análisis a partir del código fuente de la página que se puede usar para extraer datos de manera jerárquica y legible.
- Fortalezas:
- Extremadamente fácil de aprender y usar: Su API es intuitiva, lo que la hace perfecta para principiantes.
- Maneja HTML mal formado de manera elegante: Puede analizar HTML desordenado o inválido que otros analizadores podrían tener dificultades para procesar.
- Excelente para contenido estático: Si los datos que necesita están presentes en el código fuente HTML inicial, Beautiful Soup es una excelente opción.
- Se integra bien con otras bibliotecas: A menudo se usa en conjunto con
requestspara recuperar páginas web.
- Debilidades:
- No ejecuta JavaScript: No puede renderizar páginas que dependan en gran medida de JavaScript para cargar contenido. Para sitios web dinámicos, deberá combinarlo con otras herramientas.
- Puede ser lento para conjuntos de datos muy grandes: En comparación con bibliotecas más especializadas o de nivel inferior, podría no ser la opción más rápida para tareas de scraping masivas.
- Casos de uso ideales: Scraping de sitios web estáticos, extracción de datos específicos de documentos HTML, aprender los fundamentos del scraping web.
Ejemplo (usando requests):
python
import requests
from bs4 import BeautifulSoup
url = 'http://example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# Encontrar todas las etiquetas de párrafo
paragraphs = soup.find_all('p')
for p in paragraphs:
print(p.text)2. Scrapy
Scrapy es un framework potente y de código abierto para el rastreo web. Está diseñado para proyectos de scraping a gran escala, ofreciendo un conjunto completo de herramientas para recuperar, procesar y almacenar datos. Scrapy opera con una arquitectura basada en componentes, permitiendo flexibilidad y extensibilidad.
- Fortalezas:
- Asincrónico y rápido: Construido con Twisted, Scrapy es altamente eficiente y puede manejar miles de solicitudes simultáneas.
- Marco robusto: Proporciona soporte integrado para rastreo, extracción de datos, tuberías de elementos, middleware, entre otros.
- Escalable: Excelente para proyectos de extracción de datos a gran escala.
- Extensible: Puede personalizar casi todos los aspectos del proceso de rastreo.
- Maneja lógica de rastreo compleja: Ideal para navegar sitios web con estructuras complejas y seguir enlaces.
- Debilidades:
- Curva de aprendizaje más pronunciada: Más complejo que Beautiful Soup, requiriendo un mejor entendimiento de Python y conceptos de rastreo web.
- Excesivo para tareas simples: Para el scraping básico de páginas estáticas, Scrapy podría ser demasiado.
- Casos de uso ideales: Extracción de datos a gran escala, operaciones de rastreo complejas, construcción de raspadores robustos y escalables, proyectos que requieren un manejo eficiente de muchas páginas.
Documentación oficial de Scrapy: Proyecto Scrapy
3. Selenium
Selenium es principalmente conocido como una herramienta para automatizar navegadores web para propósitos de prueba. Sin embargo, su capacidad para controlar una instancia de navegador real lo hace increíblemente poderoso para el scraping web, especialmente cuando se trata de sitios web con mucho JavaScript.
- Fortalezas:
- Maneja contenido dinámico perfectamente: Al controlar un navegador, puede ejecutar JavaScript e interactuar con elementos como lo haría un usuario humano.
- Simula interacciones de usuario: Puede hacer clic en botones, completar formularios, desplazar páginas, entre otras acciones.
- Compatibilidad cruzada con navegadores: Soporta navegadores principales como Chrome, Firefox, Edge y Safari.
- Útil para escenarios complejos: Útil para raspar datos que solo aparecen después de interacciones de usuario o llamadas AJAX.
- Debilidades:
- Lento: Ejecutar un navegador completo es intensivo en recursos y significativamente más lento que las solicitudes HTTP directas.
- Intensivo en recursos: Requiere más memoria y potencia de procesamiento.
- Puede ser frágil: Los cambios en la estructura del sitio web o las actualizaciones del navegador pueden romper los scripts.
- Casos de uso ideales: Scraping de sitios web que dependen en gran medida de JavaScript, automatización de interacciones de usuario para extraer datos, pruebas de aplicaciones web.
4. Requests-HTML
Requests-HTML es una biblioteca que busca ofrecer una experiencia más amigable para el scraping web, combinando la facilidad de requests con algunas de las capacidades de análisis de Beautiful Soup y la capacidad de renderizar JavaScript.
- Fortalezas:
- Combina recuperación y análisis: Simplifica el flujo de trabajo al manejar tanto solicitudes HTTP como análisis de HTML.
- Renderizado de JavaScript: Puede renderizar JavaScript usando una instancia de Chrome headless, lo que lo hace adecuado para contenido dinámico.
- Selectores CSS: Soporta selectores CSS para seleccionar elementos de manera más fácil, similar a Beautiful Soup.
- Análisis de JSON integrado: Conveniente para APIs.
- Debilidades:
- Menos madura que Beautiful Soup o Scrapy: Aunque poderosa, no es tan ampliamente adoptada o probada en el campo.
- El renderizado de JavaScript puede ser lento: Similar a Selenium, el renderizado de JavaScript agrega sobrecarga.
- Casos de uso ideales: Scraping de sitios web dinámicos sin la complejidad completa de Scrapy, proyectos donde se necesite manejar tanto contenido estático como dinámico, desarrolladores que prefieran selectores CSS.
5. Playwright
Desarrollado por Microsoft, Playwright es una biblioteca de automatización más nueva pero en rápido crecimiento que permite pruebas confiables de extremo a extremo y scraping web. Ofrece una API robusta para controlar navegadores Chromium, Firefox y WebKit.
- Fortalezas:
- Rápido y confiable: Conocido por su velocidad y estabilidad en comparación con otras herramientas de automatización de navegadores.
- Soporte para navegadores cruzados: Funciona con Chromium, Firefox y WebKit.
- Auto-waits: Espera inteligentemente a que los elementos estén listos, reduciendo la fragilidad.
- Manejo de aplicaciones web modernas: Excelente para SPAs complejos y contenido dinámico.
- Intercepción de red: Permite un control avanzado sobre las solicitudes de red.
- Debilidades:
- Más nuevo que Selenium: La comunidad está creciendo, pero aún es más pequeña que la de Selenium.
- Puede ser intensivo en recursos: Como otras herramientas de automatización de navegadores.
- Casos de uso ideales: Scraping de aplicaciones web modernas complejas; proyectos que requieran alta confiabilidad y velocidad en la automatización de navegadores; desarrolladores que busquen una alternativa moderna a Selenium.
Documentación de Playwright: Playwright
6. Puppeteer (a través de pyppeteer)
Puppeteer es una biblioteca de Node.js desarrollada por Google para controlar Chrome o Chromium. La biblioteca pyppeteer es un puerto para Python que le permite usar las capacidades de Puppeteer dentro de Python.
- Fortalezas:
- Excelente para renderizado de JavaScript: Diseñado para controlar Chrome headless, excela en renderizar contenido dinámico.
- API poderosa: Ofrece control detallado sobre las acciones del navegador.
- Buena para tareas de automatización: Puede usarse más allá del scraping, como generar PDFs o capturas de pantalla.
- Debilidades:
- Calidad del puerto para Python:
pyppeteeres un puerto de terceros y podría no estar siempre tan actualizado o estable como la biblioteca original de Node.js. - Intensivo en recursos: Requiere una instancia de navegador.
- Menor integración directa con Python: Comparado con bibliotecas construidas nativamente para Python.
- Calidad del puerto para Python:
- Casos de uso ideales: Scraping de sitios web que dependen en gran medida de JavaScript, generación de informes automatizados o capturas de pantalla, cuando se desee un flujo de control similar a Node.js dentro de Python.
Técnicas avanzadas y herramientas para el scraping web
Más allá de las bibliotecas principales, varias técnicas avanzadas y herramientas pueden mejorar sus capacidades de scraping:
1. Manejo de CAPTCHAS
Los CAPTCHAS están diseñados para prevenir el acceso automatizado. Para necesidades legítimas de scraping (por ejemplo, investigación de mercado), podría necesitar resolverlos. Servicios como CapSolver ofrecen APIs que pueden resolver diversos tipos de CAPTCHAS de forma programática. Integrar estos servicios con sus raspadores puede mejorar significativamente las tasas de éxito en sitios que emplean estas medidas.
- CapSolver: Una opción popular conocida por su eficiencia y soporte para diversos tipos de CAPTCHA, incluyendo reCAPTCHA, hCaptcha y CAPTCHAS de imágenes. Integrar CapSolver puede automatizar el proceso de evitar estos desafíos de seguridad, permitiendo que su raspador continúe sin intervención manual. Aprende más en CapSolver.
2. Gestión de proxies
Para evitar bloqueos de IP y distribuir sus solicitudes, usar proxies es esencial para el scraping a gran escala. Las bibliotecas como requests y Scrapy admiten el uso de proxies. Puede usar servicios de proxies rotativos para gestionar un conjunto de direcciones IP.
3. Rotación de agentes de usuario
Los sitios web a menudo verifican el encabezado User-Agent para identificar bots. Rotar a través de una lista de agentes de usuario comunes puede ayudar a que su raspador parezca un usuario legítimo.
4. Límites de velocidad y retrasos
Respetar los términos de servicio del sitio web y evitar sobrecargar los servidores es crucial. Implementar retrasos (time.sleep() en Python) entre solicitudes o usar las funciones integradas de límites de velocidad de Scrapy es una buena práctica.
5. Navegadores headless
Como se discutió con Selenium, Playwright y Puppeteer, los navegadores headless (navegadores que funcionan sin una interfaz gráfica) son esenciales para el scraping de contenido dinámico. Ejecutan JavaScript y renderizan páginas como un navegador regular.
Elegir la biblioteca adecuada para su proyecto
Aquí hay un árbol de decisiones rápido para ayudarle a seleccionar la mejor biblioteca:
- ¿Es principiante y está raspando sitios web estáticos? Comience con Beautiful Soup +
requests. - ¿Necesita raspar contenido dinámico (renderizado con JavaScript)? Considere Selenium, Playwright o Requests-HTML.
- ¿Está construyendo un proyecto de scraping a gran escala y complejo? Scrapy es probablemente su mejor opción.
- ¿Necesita la automatización de navegadores más confiable y rápida para aplicaciones web modernas? Playwright es un fuerte contendiente.
- ¿Necesitas automatizar interacciones dentro de un navegador para pruebas o raspado de web? Selenium o Playwright son excelentes opciones.
Consideraciones éticas en el raspado de web
Aunque es poderoso, el raspado de web conlleva responsabilidades éticas. Siempre:
- Verifique el archivo
robots.txt: Este archivo en un sitio web indica qué partes del sitio están permitidas o prohibidas para que los bots accedan. - Respete los Términos de Servicio: Muchos sitios web prohíben explícitamente el raspado en sus Términos de Servicio.
- Evite sobrecargar los servidores: Raspado responsable implementando retrasos y limitando la tasa de solicitudes.
- No raspée datos privados: Evite recopilar información personal o sensible sin consentimiento.
- Identifíquese: Use una cadena de User-Agent descriptiva para que los administradores de sitios web sepan quién está accediendo su sitio (aunque a veces puede ser una espada de doble filo).
Según un estudio de la Universidad de Washington, las prácticas de raspado responsables son cruciales para mantener el acceso a datos públicos y evitar consecuencias legales. (Fuente: Universidad de Washington, Computer Science & Engineering).
Conclusión
Al avanzar hacia 2026, el ecosistema de raspado de web en Python sigue ofreciendo una diversa gama de herramientas poderosas. Ya sea que sea un principiante que busca extraer datos de páginas estáticas simples o un desarrollador experimentado que aborda sitios web complejos y dinámicos, existe una biblioteca de Python adecuada para sus necesidades. Beautiful Soup sigue siendo la opción predilecta para la simplicidad, Scrapy para proyectos a gran escala y Selenium, Playwright y Requests-HTML son indispensables para manejar contenido dinámico. Al comprender las fortalezas y debilidades de cada una, y al raspar responsablemente, puede aprovechar eficazmente el poder del raspado de web para recopilar datos valiosos.
Preguntas frecuentes (FAQs)
P1: ¿Cuál es la biblioteca de raspado de web más fácil de Python?
R1: Para principiantes, Beautiful Soup combinado con la biblioteca requests generalmente se considera el más fácil de aprender y usar. Tiene una API sencilla para analizar documentos HTML y XML.
P2: ¿Cuál es la biblioteca de Python mejor para raspado de sitios web con mucho JavaScript?
R2: Las bibliotecas que pueden controlar un navegador web son las mejores para sitios con mucho JavaScript. Selenium, Playwright y Requests-HTML (con sus capacidades de renderizado de JavaScript) son excelentes opciones. Playwright suele elogiarse por su velocidad y fiabilidad.
P3: ¿Puedo usar bibliotecas de raspado de web de Python para raspado de datos de cualquier sitio web?
R3: Aunque las bibliotecas de Python son muy poderosas, siempre debe verificar el archivo robots.txt y los Términos de Servicio de un sitio web. Algunos sitios web prohíben el raspado, y intentar raspado puede llevar a problemas legales o bloqueos de IP. Además, algunos sitios usan técnicas avanzadas de anti-raspado que pueden ser difíciles de superar.
P4: ¿Cómo manejo CAPTCHAs al raspado de web con Python?
R4: Los CAPTCHAs están diseñados para detener scripts automatizados. Para necesidades legítimas de raspado, puede integrarse con servicios de resolución de CAPTCHA de terceros como CapSolver. Estos servicios proporcionan APIs que pueden resolver varios tipos de CAPTCHA de forma programática, permitiendo que su raspador continúe.
P5: ¿Es adecuado Scrapy para tareas de raspado pequeñas y simples?
R5: Aunque Scrapy es increíblemente poderoso y escalable, podría ser excesivo para tareas de raspado muy simples. Para extracción básica de unas pocas páginas estáticas, Beautiful Soup y requests serían más eficientes de configurar y ejecutar.
P6: ¿Cuáles son las pautas éticas para el raspado de web?
R6: Las pautas éticas clave incluyen: siempre verificar y respetar robots.txt, cumplir con los Términos de Servicio del sitio web, evitar sobrecargar los servidores del sitio con demasiadas solicitudes (implementar retrasos) y nunca raspée datos privados o sensibles de usuarios sin consentimiento explícito. El raspado responsable garantiza la disponibilidad continua de datos en línea.
Aviso de Cumplimiento: La información proporcionada en este blog es solo para fines informativos. CapSolver se compromete a cumplir con todas las leyes y regulaciones aplicables. El uso de la red de CapSolver para actividades ilegales, fraudulentas o abusivas está estrictamente prohibido y será investigado. Nuestras soluciones para la resolución de captcha mejoran la experiencia del usuario mientras garantizan un 100% de cumplimiento al ayudar a resolver las dificultades de captcha durante el rastreo de datos públicos. Fomentamos el uso responsable de nuestros servicios. Para obtener más información, visite nuestros Términos de Servicio y Política de Privacidad.
Máse
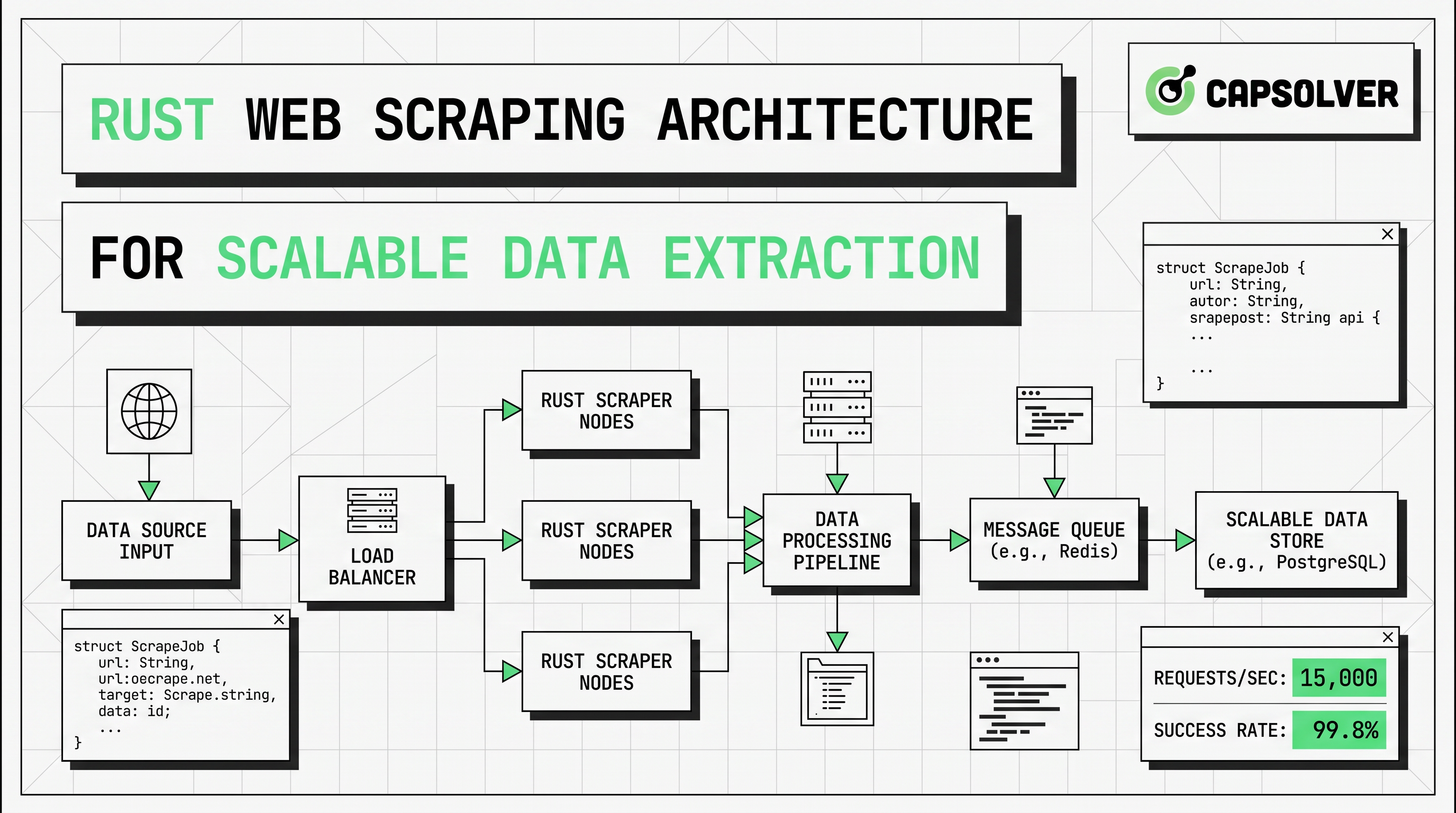
Arquitectura de raspado de web para extracción de datos escalable
Aprende una arquitectura de raspado web escalable en Rust con reqwest, scraper, raspado asíncrono, raspado con navegador sin cabeza, rotación de proxies y manejo de CAPTCHA conforme.
Aloísio Vítor
22-Apr-2026

Cómo resolver Captcha en Nanobot con CapSolver
Automatiza la resolución de CAPTCHA con Nanobot y CapSolver. Utiliza Playwright para resolver reCAPTCHA y Cloudflare autónomamente.

Adélia Cruz
26-Feb-2026

Datos como Servicio (DaaS): ¿Qué es y por qué es importante en 2026
Comprender Datos como Servicio (DaaS) en 2026. Explora sus beneficios, casos de uso y cómo transforma los negocios con insights en tiempo real y escalabilidad.

Sora Fujimoto
12-Feb-2026

Cómo arreglar errores comunes de raspado de web en 2026
Dominar la resolución de diversos errores de scrapers web como 400, 401, 402, 403, 429, 5xx y Cloudflare 1001 en 2026. Aprender estrategias avanzadas para la rotación de IPs, encabezados y limitación de tasa adaptativa con CapSolver.

Emma Foster
05-Feb-2026

Cómo resolver un Captcha en RoxyBrowser con la integración de CapSolver
Integrar CapSolver con RoxyBrowser para automatizar tareas del navegador y evadir reCAPTCHA, Turnstile y otros CAPTCHAs.
Emma Foster
04-Feb-2026

Cómo resolver captcha en EasySpider con la integración de CapSolver
EasySpider es una herramienta visual de scraping web y automatización de navegadores, y cuando se combina con CapSolver, puede resolver de manera confiable los CAPTCHAs como reCAPTCHA v2 y Cloudflare Turnstile, facilitando la extracción de datos automatizada sin interrupciones en todo tipo de sitios web.
Adélia Cruz
04-Feb-2026