







एआई स्क्रैपिंग क्या है? परिभाषा, लाभ, उपयोग के मामले।

Anh Tuan
Data Science Expert
31-Dec-2025

TL;DR:
- AI स्क्रैपिंग मशीन लर्निंग और NLP का उपयोग करके डेटा निकालने की स्वचालन करता है, जो पारंपरिक नियम-आधारित विधियों की भंगुरता को दूर करता है।
- यह असंरचित डेटा के साथ अच्छा काम करता है, जटिल एंटी-बॉट उपायों को पार करता है, और हस्तक्षेप के बिना वेबसाइट लेआउट परिवर्तनों के साथ समायोजित होता है।
- मुख्य लाभ में 99.5% निकालने की सटीकता, रखरखाव लागत में कमी, और कच्चे वेब सामग्री को क्रियात्मक ज्ञान में बदलने की क्षमता शामिल है।
- आधुनिक AI स्क्रैपिंग वर्कफ़्लो में उन्नत CAPTCHAs (reCAPTCHA, Cloudflare) को हल करने के लिए विशेषज्ञ टूल्स जैसे CapSolver के एकीकरण की आवश्यकता होती है।
परिचय
डिजिटल वातावरण अप्रत्याशित गति से विकसित हो रहा है, और हमारे जानकारी एकत्र करने के तरीकों को इसके साथ बनाए रखना आवश्यक है। AI स्क्रैपिंग डेटा एकत्र करने की अगली पीढ़ी है, जो सरल स्क्रिप्ट के बजाय मानव के समान वेब को समझने वाले बुद्धिमान प्रणालियों में बढ़ गई है। 2026 में व्यापार के लिए, बड़े पैमाने पर उच्च गुणवत्ता वाले डेटा के निकालने की क्षमता अब एक विलासिता नहीं है बल्कि एक मुख्य प्रतिस्पर्धी आवश्यकता है। इस लेख में AI-संचालित निकालने के बजाय पारंपरिक विधियों के बारे में अध्ययन किया गया है, इसकी सफलता के तकनीकी यांत्रिकी, और आपके द्वारा AI एजेंट वेब स्क्रैपर बनाएं बनाएं जाने के बारे में चर्चा की गई है। आप डेटा विशेषज्ञ या व्यवसाय नेता हों या न हों, इस परिवर्तन को समझना डेटा अर्थव्यवस्था के भविष्य के लिए आवश्यक है।
AI स्क्रैपिंग क्या है?
AI स्क्रैपिंग कृत्रिम बुद्धिमता का उपयोग करके डिजिटल स्रोतों से डेटा निकालने की प्रक्रिया है, विशेष रूप से मशीन लर्निंग (ML) और प्राकृतिक भाषा प्रसंस्करण (NLP) का उपयोग करके। पारंपरिक वेब स्क्रैपिंग के विपरीत, जो निश्चित CSS सेलेक्टर या XPath अभिव्यक्तियों पर निर्भर करता है, AI स्क्रैपिंग एक पृष्ठ के दृश्य और पाठ संदर्भ को समझता है। इससे यह सुनिश्चित होता है कि वह "मूल्य" या "लेखक" की पहचान कर सके, चाहे नीचे के HTML कैसा भी संरचित हो।
विश्व वेब स्क्रैपिंग बाजार 2025 तक 12.34 बिलियन डॉलर तक पहुंच जाएगा, हाल के Market Growth Reports के अनुसार। इस वृद्धि का मुख्य कारण बड़े भाषा मॉडल (LLMs) के लिए उच्च गुणवत्ता वाले डेटा की मांग है। AI स्क्रैपिंग डेटा का एकत्रीकरण करता है; यह ज्ञान एकत्र करता है क्योंकि यह एंटिटी के बीच संबंधों को समझता है, भावना विश्लेषण करता है और वास्तविक समय में डेटा को साफ करता है।
AI स्क्रैपिंग कैसे काम करता है?
AI-संचालित निकालने के यांत्रिकी में एक जटिल बहु-स्तरीय दृष्टिकोण शामिल है जो मानव ब्राउज़िंग व्यवहार की नकल करता है जबकि विशाल गणना शक्ति का उपयोग करता है।
| स्तर | कार्यक्षमता | मुख्य तकनीक |
|---|---|---|
| डेटा अर्जन | वेबसाइटों का नेविगेशन, JavaScript का निपटारा, और प्रॉक्सी का प्रबंधन करता है। | Playwright, Puppeteer, हेडलेस क्रोम |
| अर्थात्मकता | संदर्भ का उपयोग करके संबंधित क्षेत्रों (शीर्षक, मूल्य, समीक्षा) की पहचान करता है। | LLMs (GPT-4, Claude), कंप्यूटर दृष्टि |
| अनुकूलन | डेटा बिंदुओं को फिर से मैप करके लेआउट परिवर्तनों के साथ स्व-स्वस्थ होता है। | पुनर्बलन शिक्षा, पैटर्न अन्वेषण |
| सुरक्षा नेविगेशन स्तर | CAPTCHAs और दर-सीमा जैसी सुरक्षा चुनौतियों को हल करता है। | CapSolver, AI-चालित ब्राउज़र फिंगरप्रिंटिंग |
एक सामान्य कार्यप्रवाह में, AI एजेंट को प्राकृतिक भाषा प्रेरणा मिलती है। फिर वह लक्ष्य URL पर जाता है, पृष्ठ व्यवस्था को "देखता" है, और NLP का उपयोग विशिष्ट जानकारी निकालने के लिए करता है। अगर यह एक बाधा से टकराता है, तो यह AI ब्राउज़रों के साथ CAPTCHA हल करने के संयोजन के माध्यम से डेटा प्रवाह को अविच्छिन्न रख सकता है।
AI स्क्रैपिंग और पारंपरिक वेब स्क्रैपिंग
पारंपरिक से AI-संचालित विधियों के लिए संक्रमण को एक कठोर एसेम्बली लाइन से एक लचीले रोबोटिक प्रणाली के समान तुलना की जाती है।
पारंपरिक स्क्रैपिंग "यदि-तो" तर्क पर बनाया गया है। अगर विकासकर्ता स्क्रिप्ट को एक विशिष्ट <div> टैग में मूल्य खोजने के लिए कहता है, और वेबसाइट के मालिक उस टैग को <span> में बदल देता है, तो स्क्रैपर टूट जाता है। इससे रखरखाव लागत में वृद्धि होती है और बार-बार बंद हो जाता है।
हालांकि, AI स्क्रैपिंग सामान्य बुद्धिमता का उपयोग करता है। यह तय करता है कि डॉलर का चिह्न और एक संख्या एक मूल्य हो सकती है, चाहे किसी भी HTML टैग का उपयोग किया जाए। इस अविनाशीता के कारण AI-संचालित उपकरणों के निकालने की गति पारंपरिक नियम सेटिंग के मुकाबले 30-40% अधिक तेज है, जैसा कि Scrapingdog की 2025 ट्रेंड रिपोर्ट में बताया गया है।
तुलना सारांश
| विशेषता | पारंपरिक वेब स्क्रैपिंग | AI स्क्रैपिंग |
|---|---|---|
| लॉजिक के आधार | कोड किए गए नियम (CSS/XPath) | सामान्य और दृश्य समझ |
| रखरखाव | उच्च (लेआउट परिवर्तन के साथ टूट जाता है) | कम (स्व-स्वस्थ क्षमता) |
| डेटा गुणवत्ता | हस्तचालित साफ करने की आवश्यकता होती है | स्वचालित सामान्यीकरण और साफ करना |
| जटिलता | डायनामिक/असंरचित डेटा में कठिनाई का सामना करता है | छवियों, PDFs और JS-भारित साइटों में अच्छा काम करता है |
| सफलता दर | मध्यम (आसानी से ब्लॉक कर दिया जाता है) | उच्च (मानव व्यवहार की नकल करता है) |
AI स्क्रैपिंग के मुख्य लाभ
अपने डेटा पाइपलाइन में AI के एकीकरण से कई रूपांतरकारी लाभ मिलते हैं जो सरल स्वचालन से अधिक हैं।
- अद्वितीय प्रतिरोधकता: AI स्क्रैपर बिना मानव हस्तक्षेप के छोटे वेबसाइट अपडेट के साथ समायोजित हो सकते हैं। इस "स्व-स्वस्थ" गुण के कारण आपके डेटा फीड लक्ष्य साइटों के बार-बार डिज़ाइन बदलने के बावजूद स्थिर रहते हैं।
- असंरचित डेटा का निपटान: वेब के अधिकांश मूल्यवान जानकारी असंरचित है - सोशल मीडिया टिप्पणियां, फोरम पोस्ट या वीडियो ट्रांसक्रिप्ट के बारे में सोचें। AI इस कच्चे जानकारी को विश्लेषणात्मक उपकरणों में सीधे पाइप करने के लिए MCP का नियंत्रण (मॉडल संदर्भ प्रोटोकॉल) का उपयोग कर सकता है।
- उत्कृष्ट एंटी-बॉट बाधा अतिक्रमण: आधुनिक वेबसाइट बॉट को ब्लॉक करने के लिए उन्नत व्यवहार विश्लेषण का उपयोग करते हैं। AI स्क्रैपर मानव चूषण गतियों, टाइपिंग गति और ब्राउज़िंग पैटर्न की नकल कर सकते हैं। जब चुनौती का सामना होता है, तो वे AI स्क्रैपिंग वर्कफ़्लो में CAPTCHA हल करने के संयोजन के माध्यम से 24/7 उपलब्धता सुनिश्चित करने के लिए CapSolver जैसी सेवाओं का उपयोग कर सकते हैं।
- पैमाने पर लागत-कुशलता: जबकि AI प्रणाली की शुरुआती स्थापना अधिक हो सकती है, बर्बाद ब्राउज़र के तकनीकी निर्माण में विकासकर्ता घंटों के लंबे समय में बचत करते हैं।
AI स्क्रैपिंग के सामान्य उपयोग मामले
AI स्क्रैपिंग विभिन्न उद्योगों में नवाचार और दक्षता के लिए उपयोग किया जा रहा है। बुद्धिमान निकालने की लचीलापन ऐसे डेटा चुनौतियों के सामने आने के लिए संगठनों को अब तक अपरिमेय रहे हैं।
ई-कॉमर्स बुद्धिमता और डायनामिक मूल्य निर्धारण
ऑनलाइन खरीदारी के अत्यधिक प्रतिस्पर्धात्मक विश्व में, मूल्य मिनट में बदल जाते हैं। AI स्क्रैपिंग व्यापारियों को हजारों वैश्विक दुकानों में प्रतिद्वंद्वी मूल्य, स्टॉक स्तर और ग्राहक भावना के वास्तविक समय में निरीक्षण करने की अनुमति देता है। सरल मूल्य ट्रैकिंग के बाहर, AI उत्पाद विवरण और छवियों के विश्लेषण कर सकता है ताकि प्रतिद्वंद्वी नामकरण परिप्रेक्ष्य के बावजूद तुलनाएं सटीक हों। इस सटीकता के स्तर के कारण डायनामिक मूल्य नीतियों को लाभ मार्जिन में बढ़ा सकता है।
उच्च गुणवत्ता वाला AI ट्रेनिंग डेटा
वर्तमान AI क्रांति डेटा द्वारा चालित है। अगली पीढ़ी के LLMs के लिए बड़े डेटा सेट एकत्र करने के लिए उच्च गुणवत्ता वाला डेटा आवश्यक है जो केवल AI-संचालित निकालने के द्वारा प्रदान किया जा सकता है। पारंपरिक स्क्रैपर अनावश्यक बॉइलरप्लेट सामग्री को फ़िल्टर नहीं कर सकते, जिसके कारण डेटा सेट में "शोर" शामिल हो जाता है। हालांकि, AI स्क्रैपर लेख के मुख्य सामग्री और विज्ञापन या नेविगेशन लिंक के बीच अंतर कर सकते हैं, जिससे ट्रेनिंग डेटा साफ और संदर्भ में संबंधित होता है।
वित्तीय बाजार विश्लेषण और वैकल्पिक डेटा
हेज फंड और वित्तीय संस्थान बाजार के लाभ के लिए वैकल्पिक डेटा के उपयोग में बढ़ते हुए हैं। इसमें खबर साइटों, नियामक फ़ाइलिंग, सोशल मीडिया ट्रेंड और यहां तक कि तालिकाओं में प्रस्तुत सैटेलाइट छवि डेटा शामिल है। AI स्क्रैपिंग इन विविध स्रोतों के साथ समानांतर रूप से प्रक्रिया कर सकता है, जो मुख्यधारा में आने से पहले उभरते बाजार ट्रेंड की पहचान करता है। वित्तीय समाचार पर वास्तविक समय में भावना विश्लेषण करके AI एजेंट व्यापारियों को सेकंड में कार्यात्मक अंतर्दृष्टि प्रदान कर सकते हैं।
अच्छी गुणवत्ता वाली डेटा ट्रेनिंग के लिए वास्तविक अच्छी गुणवत्ता वाला डेटा
वास्तविक अच्छी गुणवत्ता वाला डेटा वर्तमान AI क्रांति को बल देता है। अगली पीढ़ी के LLMs के लिए बड़े डेटा संग्रह के लिए उच्च गुणवत्ता वाला डेटा आवश्यक है जो केवल AI-संचालित निकालने के द्वारा प्रदान किया जा सकता है। पारंपरिक स्क्रैपर अक्सर असंबंधित बॉइलरप्लेट सामग्री को फ़िल्टर करने में असमर्थ होते हैं, जिसके कारण डेटा सेट में "शोर" शामिल हो जाता है। AI स्क्रैपर लेख के मुख्य सामग्री और विज्ञापन या नेविगेशन लिंक के बीच अंतर कर सकते हैं, जिससे ट्रेनिंग डेटा साफ और संदर्भ में संबंधित होता है।
वास्तविक अच्छी गुणवत्ता वाला डेटा
अच्छी गुणवत्ता वाला डेटा वर्तमान AI क्रांति को बल देता है। अगली पीढ़ी के LLMs के लिए बड़े डेटा सेट एकत्र करने के लिए उच्च गुणवत्ता वाला डेटा आवश्यक है जो केवल AI-संचालित निकालने के द्वारा प्रदान किया जा सकता है। पारंपरिक स्क्रैपर अक्सर असंबंधित बॉइलरप्लेट सामग्री को फ़िल्टर करने में असमर्थ होते हैं, जिसके कारण डेटा सेट में "शोर" शामिल हो जाता है। AI स्क्रैपर लेख के मुख्य सामग्री और विज्ञापन या नेविगेशन लिंक के बीच अंतर कर सकते हैं, जिससे ट्रेनिंग डेटा साफ और संदर्भ में संबंधित होता है।
वित्तीय बाजार विश्लेषण और वैकल्पिक डेटा
हेज फंड और वित्तीय संस्थान बाजार में लाभ प्राप्त करने के लिए वैकल्पिक डेटा के उपयोग में बढ़ रहे हैं। इसमें खबर साइटों, नियामक फ़ाइलिंग, सोशल मीडिया ट्रेंड और यहां तक कि तालिकाओं में प्रस्तुत सैटेलाइट छवि डेटा शामिल है। AI स्क्रैपिंग इन विविध स्रोतों के साथ समानांतर रूप से प्रक्रिया कर सकता है, जो मुख्यधारा में आने से पहले उभरते बाजार ट्रेंड की पहचान करता है। वित्तीय समाचार पर वास्तविक समय में भावना विश्लेषण करके AI एजेंट व्यापारियों को सेकंड में कार्यात्मक अंतर्दृष्टि प्रदान कर सकते हैं।
संपत्ति और अनुसंधान नेतृत्व
रियल एस्टेट उद्योग विभिन्न प्लेटफॉर्म से अद्यतन सूची के आधार पर भारी रूप से निर्भर करता है। AI स्क्रैपिंग इन सूचियों के संग्रह कर सकता है, डेटा को सामान्यीकृत कर सकता है (उदाहरण के लिए, वर्ग फुटेज या मुद्रा के रूपांतरण), और अपने आप अपमूल्यांकित संपत्ति की पहचान कर सकता है। समान रूप से, B2B बिक्री के लिए, AI व्यावसायिक नेटवर्क और कंपनी डायरेक्टरी से संभावित अनुसंधान नेतृत्व की पहचान और गुणवत्ता विश्लेषण जैसे कार्य कर सकता है, जैसे कि नौकरी के उपाधि, कंपनी वृद्धि पैटर्न और हाल के समाचार उल्लेख, जो एक बहुत लक्षित बिक्री पाइपलाइन बनाता है।
तकनीकी कार्यान्वयन: एक प्रतिरोधक पाइपलाइन बनाना
AI स्क्रैपिंग के लाभ को वास्तव में ले जाने के लिए, आपको एक प्रतिरोधक डेटा पाइपलाइन की वास्तु को समझना आवश्यक है। यह लक्ष्य URL के आयाम में बढ़ते समय के साथ ऊर्ध्वाधर रूप से स्केल करने वाले कंटेनराइज्ड समाधान के चयन से शुरू होता है।
हेडलेस ब्राउज़र की भूमिका
Playwright और Puppeteer जैसे उपकरण अर्जन स्तर के कार्यकर्ता हैं। वे AI एजेंट को वेबसाइटों के साथ मानव के समान अंतर करने की अनुमति देते हैं - बटन क्लिक करना, अनंत फीड के स्क्रॉल करना, और असिंक्रोनस JavaScript लोड होने के लिए प्रतीक्षा करना। हालांकि, इन ब्राउज़र को पैमाने पर चलाना संसाधन-गहन होता है। AI अनुकूलन उन पृष्ठों के लिए सहायता कर सकता है जिनके लिए पूर्ण ब्राउज़र रेंडरिंग आवश्यक है और जिनके लिए तेज, हल्के HTTP अनुरोध द्वारा प्राप्त किया जा सकता है।
किनारे पर बुद्धिमता के एकीकरण
सबसे उन्नत AI स्क्रैपिंग सेटअप डेटा निकालने और साफ करने के "किनारे" पर करते हैं। इसका अर्थ यह है कि बजाय कच्चे HTML को केंद्रीय सर्वर पर प्रसंस्करण के लिए भेजने के, AI एजेंट स्थानीय रूप से निकालने का कार्य करता है। इससे लेटेंसी और बैंडविड्थ लागत कम हो जाती है। हल्के LLMs या विशेषज्ञ NLP मॉडल का उपयोग करके इन एजेंट ब्राउज़र वातावरण से सीधे संरचित JSON डेटा प्रदान कर सकते हैं।
सुरक्षा चुनौतियों का प्रबंधन
जैसा कि पहले बताया गया है, "सुरक्षा नेविगेशन स्तर" महत्वपूर्ण है। एक पाइपलाइन केवल अपने कमजोर बिंदु के समान होती है। अगर आपका AI एजेंट Cloudflare चुनौती से ब्लॉक हो जाता है, तो पूरा कार्यप्रवाह रुक जाता है। इसलिए, CapSolver जैसी सेवा के साथ एक मजबूत एकीकरण अनिवार्य है। यह आपके AI एजेंट के लिए सुरक्षा जांच चैकपॉइंट पार करने के लिए आवश्यक "प्रमाणपत्र" प्रदान करता है। शीर्ष अभ्यास में उपयोगकर्ता एजेंट के चक्र को घूमाना, सत्र कुकीज को बुद्धिमानी से प्रबंधित करना, और एक उच्च गुणवत्ता वाले निवासी प्रॉक्सी का उपयोग करना शामिल है जो स्क्रैपर के चिह्न को छिपाता है।
CapSolver के साथ सुरक्षा बाधाओं का एक अवरोध करना
AI स्क्रैपिंग में सबसे बड़ी चुनौती बॉट रक्षा के बढ़ते स्तर है। वेबसाइट अब reCAPTCHA v3, Cloudflare Turnstile और AWS WAF का उपयोग अपने डेटा की रक्षा करने के लिए करते हैं। इस चुनौती के सामने एक विशेषज्ञ समाधान जैसे CapSolver अनिवार्य हो जाता है। इसके माध्यम से, CapSolver एक AI-संचालित API प्रदान करता है जो कुछ मिलीसेकंड में इन चुनौतियों को हल करता है। इसके साथ CAPTCHA हल करने के लिए AI-LLM के एकीकरण आपके स्वचालित एजेंट को कभी भी "Verify you are human" दीवार के पीछे फंसे नहीं रहने देता।
CapSolver पर पंजीकरण करते समय कोड
CAP26का उपयोग करें!
निष्कर्ष
AI स्क्रैपिंग केवल एक ट्रेंड नहीं है; यह हमारे वेब डेटा के साथ अंतर करने के तरीके की अपरिहार्य विकास है। LLMs के सामान्य शक्ति के साथ CapSolver जैसे उपकरणों के भरोसे से, संगठन अब तक के तेज, बुद्धिमान और अधिक प्रतिरोधक डेटा पाइपलाइन बना सकते हैं। 2026 में आगे बढ़ते रहने के साथ, पारंपरिक स्क्रिप्ट का उपयोग करने वालों और AI का उपयोग करने वालों के बीच अंतर बढ़ता रहेगा। अब अपने बुनियादी ढांचा अपग्रेड करें और बुद्धिमान डेटा निकालने के भविष्य के साथ समायोजित हो जाएं।
अक्सर पूछे जाने वाले प्रश्न
1. AI स्क्रैपिंग कानूनी है?
वेब स्क्रैपिंग सार्वजनिक रूप से उपलब्ध डेटा के लिए आमतौर पर कानूनी है, लेकिन वेबसाइट की उपयोगकर्ता सेवा की शर्तों और डेटा गोपनीयता कानूनों जैसे GDPR के पालन करना आवश्यक है। हाल के निर्णय, जैसे कि Meta vs. Bright Data 2024 मामला, AI अनुबंधात्मक सीमाओं के महत्व के महत्व को बल देते हैं।
2. AI स्क्रैपिंग CAPTCHAs के साथ कैसे निपटता है?
AI स्क्रैपर अक्सर CapSolver जैसे तीसरे पक्ष एपीआई के साथ एकीकृत होते हैं, जो मशीन लर्निंग मॉडल का उपयोग करके reCAPTCHA और Cloudflare Turnstile जैसी जटिल चुनौतियों को स्वचालित रूप से हल करते हैं।
3. क्या AI स्क्रैपिंग के उपयोग के लिए आपको कोडिंग करने की आवश्यकता होती है?
कोडिंग के कुछ तकनीकी ज्ञान मदद करता है, लेकिन बहुत से आधुनिक AI स्क्रैपिंग उपकरणों में प्राकृतिक भाषा में अपन आवश्यकताओं के वर्णन करने के लिए नो-कोड या लो-कोड इंटरफ़ेस होते हैं।
4. क्रॉलर और स्क्रैपर के बीच मुख्य अंतर क्या है?
एक क्रॉलर (जैसे Googlebot) वेब के अनुक्रमण के लिए नेविगेशन करता है, जबकि स्क्रैपर उन पृष्ठों से विशिष्ट डेटा निकालता है। AI दोनों को अधिक "मानव-जैसा" बनाता है।
**5. क्या AI स्क्रैपिंग छवियों और PDFs के साथ काम कर सकता है?
हां, AI स्क्रैपर कंप्यूटर दृष्टि और OCR (ऑप्टिकल चरित्र पहचान) का उपयोग करके गैर-पाठ रूपों से पाठ और डेटा निकाल सकते हैं, जो पारंपरिक स्क्रैपर नहीं कर सकते हैं।
अनुपालन अस्वीकरण: इस ब्लॉग पर प्रदान की गई जानकारी केवल सूचनात्मक उद्देश्यों के लिए है। CapSolver सभी लागू कानूनों और विनियमों का पालन करने के लिए प्रतिबद्ध है। CapSolver नेटवर्क का उपयोग अवैध, धोखाधड़ी या दुरुपयोग करने वाली गतिविधियों के लिए करना सख्त वर्जित है और इसकी जांच की जाएगी। हमारे कैप्चा समाधान उपयोगकर्ता अनुभव को बेहतर बनाने के साथ-साथ सार्वजनिक डेटा क्रॉलिंग के दौरान कैप्चा कठिनाइयों को हल करने में 100% अनुपालन सुनिश्चित करते हैं। हम अपनी सेवाओं के जिम्मेदार उपयोग की प्रोत्साहना करते हैं। अधिक जानकारी के लिए, कृपया हमारी सेवा की शर्तें और गोपनीयता नीति पर जाएं।
अधिक
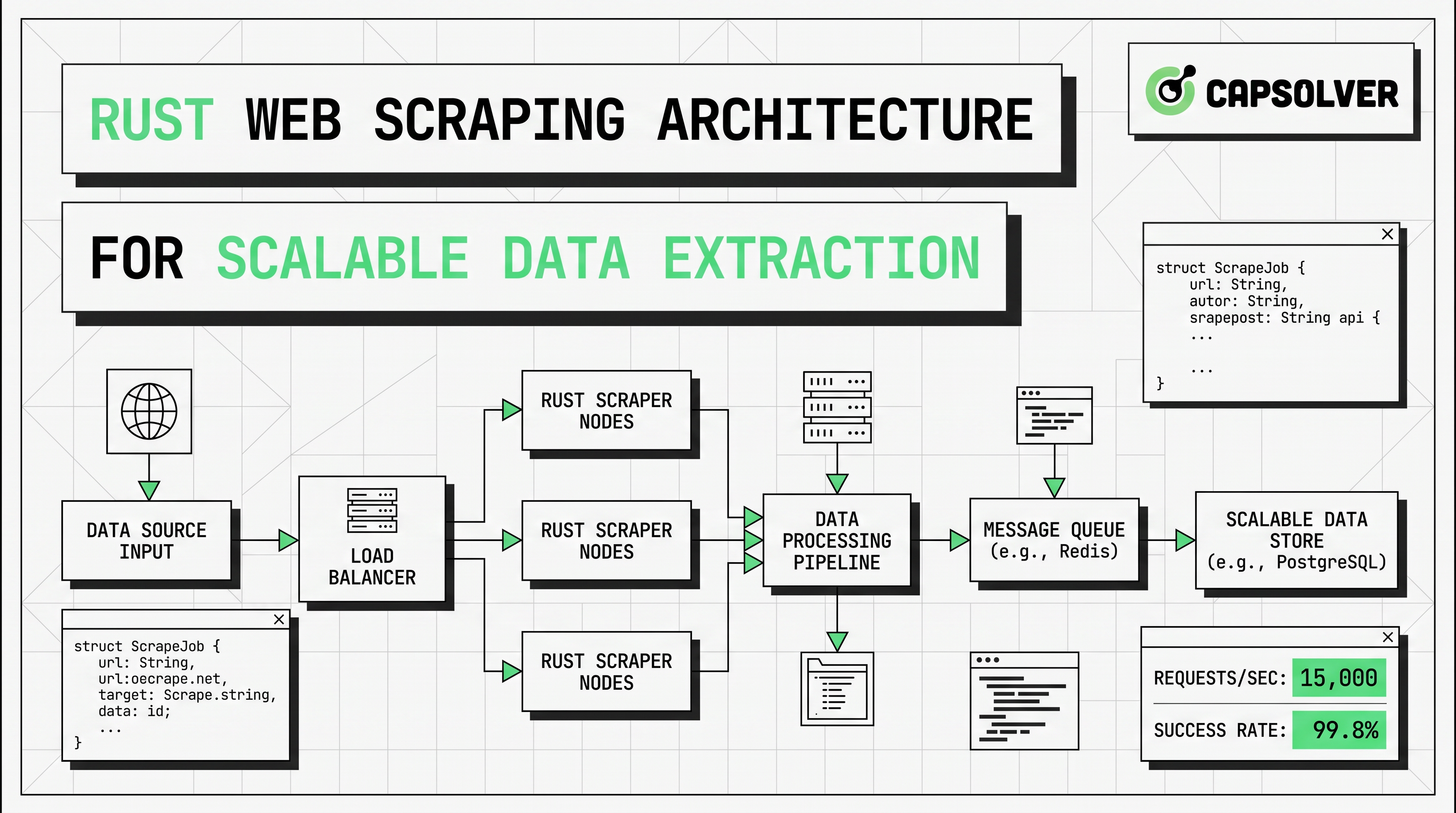
रस्ट वेब स्क्रैपिंग आर्किटेक्चर लिए स्केलेबल डेटा निष्कर्षण
Rust में वेब स्क्रैपिंग के स्केलेबल आर्किटेक्चर सीखें, reqwest, scraper, असिंक्रोनस स्क्रैपिंग, हेडलेस ब्राउज़र स्क्रैपिंग, प्रॉक्सी रोटेशन, और संगत CAPTCHA का निपटारा।

Rajinder Singh
22-Apr-2026

रॉक्सीब्राउज़र में कैप्चा हल करना कैपसॉल्वर एकीकरण के साथ
CapSolver के साथ RoxyBrowser के एकीकरण करें ताकि ब्राउज़र के कार्यों को स्वचालित किया जा सके और reCAPTCHA, Turnstile और अन्य CAPTCHAs को बायपास किया जा सके।
Rajinder Singh
04-Feb-2026

ईजीस्पाइडर में कैप्चा हल करें कैपसॉल्वर एकीकरण के साथ
ईज़ीस्पाइडर एक दृश्य, नो-कोड वेब स्क्रैपिंग और ब्राउज़र ऑटोमेशन टूल है, जबकि कैपसॉल्वर के साथ जुड़ा हुआ है, तो यह reCAPTCHA v2 और Cloudflare Turnstile जैसे CAPTCHA को विश्वसनीय रूप से हल कर सकता है, जो वेबसाइटों पर सुचारू रूप से स्वचालित डेटा निकालने की अनुमति देता है।
Rajinder Singh
04-Feb-2026

रीकैपचा वी२ कैसे हल करें रीलेवेंस एआई में कैपसॉल्वर एकीकरण के साथ
रिलेवेंस एआई उपकरण बनाएं जो reCAPTCHA v2 को CapSolver के उपयोग से हल करे। ब्राउजर ऑटोमेशन के बिना एपीआई के माध्यम से फॉर्म जमाकर स्वचालित करें।
Rajinder Singh
03-Feb-2026

2026 में IP बैन: उनके काम करने का तरीका और उन्हें पार करने के व्यावहारिक तरीके
2026 में आईपी बैन बायपास करने के तरीके सीखें हमारे विस्तृत गाइड के साथ। आधुनिक आईपी ब्लॉकिंग तकनीकों और रिजिडेंशियल प्रॉक्सी और कैप्चा सॉल्वर्स जैसे व्यावहारिक समाधानों की खोज करें।

Nikolai Smirnov
26-Jan-2026

कैप्चा कैसे हल करें ब्राउज़र4 में कैपसॉल्वर इंटीग्रेशन के साथ
उच्च बहुतायत ब्राउज़र4 स्वचालन के साथ संयोजित करें, जो बड़े पैमाने पर वेब डेटा निकास में CAPTCHA चुनौतियों का निपटारा करने के लिए CapSolver का उपयोग करता है।
Rajinder Singh
21-Jan-2026