







Arsitektur AI-LLM CapSolver dalam Praktik: Membangun Pipeline Keputusan untuk Sistem Pengenalan CAPTCHA Adaptif

Ethan Collins
Pattern Recognition Specialist
10-Feb-2026

CAPTCHA semakin beragam dan kompleks — dari tantangan teks sederhana hingga teka-teki interaktif dan logika risiko dinamis — dan alur kerja otomasi saat ini membutuhkan lebih dari pengenalan gambar dasar. OCR tradisional dan model CNN mandiri kesulitan mengikuti format yang terus berkembang dan tugas visual-semantic campuran.
Dalam artikel sebelumnya, "AI-LLM: Solusi Masa Depan untuk Pengenalan Gambar Kontrol Risiko dan CAPTCHA", kami menjelajahi mengapa model bahasa besar menjadi komponen kunci dalam sistem CAPTCHA modern. Artikel ini membangunnya dengan mengeksplorasi arsitektur praktis di balik pipeline keputusan CapSolver: bagaimana jenis CAPTCHA berbeda dialihkan ke strategi penyelesaian yang tepat dan bagaimana sistem beradaptasi seiring munculnya format baru.
Tantangan intinya bukan hanya mengenali piksel tetapi memahami tujuan CAPTCHA dan beradaptasi secara real-time. Arsitektur CapSolver AI-LLM menggabungkan visi komputer dengan pemikiran tingkat tinggi untuk membuat keputusan strategis alih-alih hanya pencocokan pola.
Berikut adalah gambaran arsitektur tersebut:
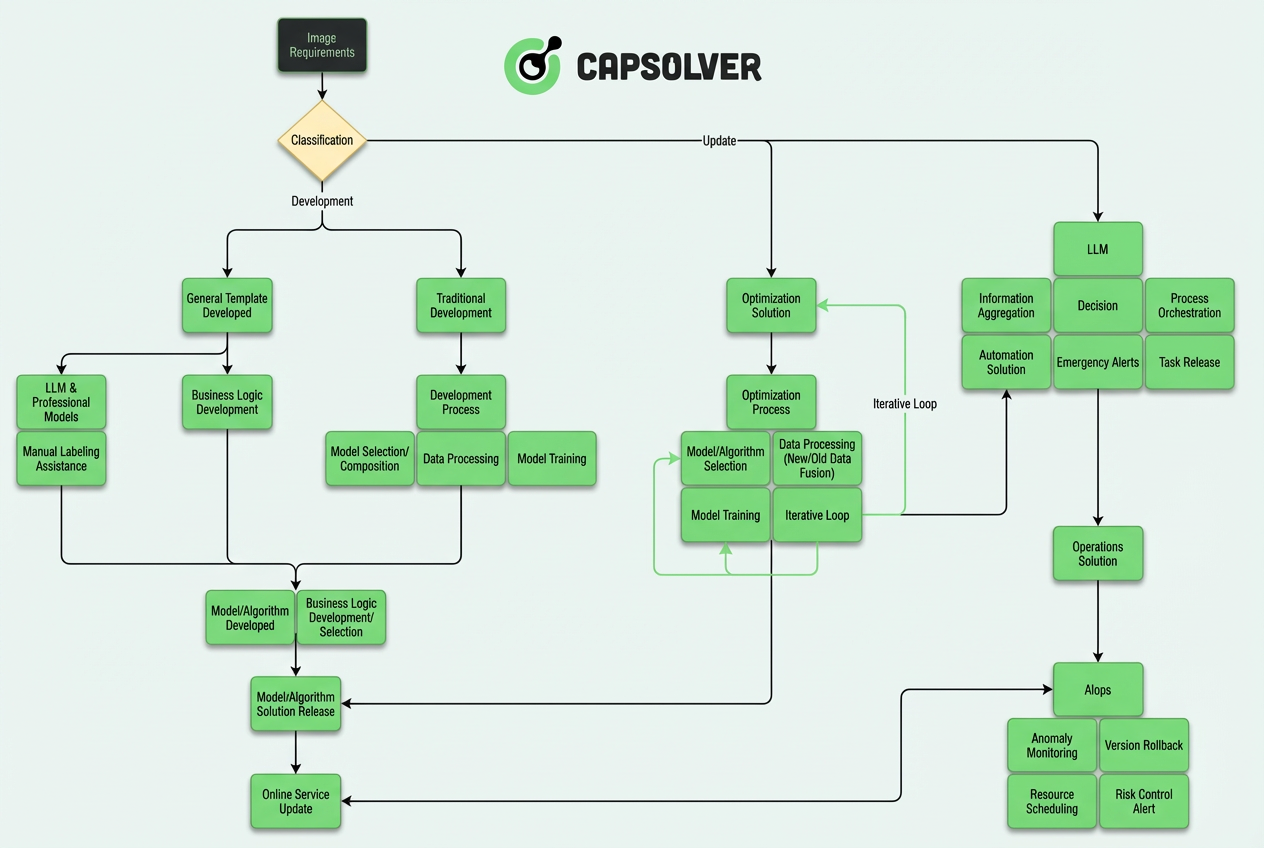
Artikel ini menyelami teknik di balik sistem tiga lapisan kami yang mandiri, menghubungkan masukan visual mentah dengan pemrosesan semantik.
Menurut penelitian industri, pada 2026 lebih dari 80% perusahaan akan menerapkan aplikasi yang didukung AI generatif di lingkungan produksi — menyoroti pergeseran cepat menuju alur kerja otomatis, pipeline multimodal, dan sistem yang didorong AI.
Arsitektur Inti: Sistem Tiga Lapisan Mandiri
Berdasarkan praktik teknik, sistem pengenalan CAPTCHA modern telah berkembang dari arsitektur monolitik "model + aturan" menjadi sistem kompleks dengan lapisan otonomi. Seluruh arsitektur dapat dibagi menjadi tiga lapisan inti:
| Lapisan | Modul Inti | Posisi Fungsional | Contoh Teknologi |
|---|---|---|---|
| Lapisan Keputusan Aplikasi | Otak LLM | Pemahaman semantik, orkestrasi tugas, analisis anomali | GPT-4/Vision, Claude 3, Qwen3, Agens LangChain Sendiri |
| Lapisan Eksekusi Algoritma | Mesin CV | Deteksi objek, simulasi trajektori, pengenalan gambar | YOLO, ViT, blip, clip, dino |
| Lapisan Jaminan O&M | AIops | Pemantauan, rollback, penjadwalan sumber daya, kontrol risiko | Prometheus, Kubernetes, Strategi RL Kustom |
Inti dari desain lapisan ini adalah: LLM bertanggung jawab untuk "berpikir", model CV bertanggung jawab untuk "menjalankan", dan AIops bertanggung jawab untuk "menjamin".
Mengapa intervensi LLM diperlukan?
Pengenalan CAPTCHA tradisional menghadapi tiga kelemahan fatal:
- Kesenjangan Semantik: Tidak mampu memahami teks instruksi seperti "Silakan klik semua gambar yang berisi xx" atau "Sentuh item yang biasanya digunakan bersama item yang ditampilkan," sementara variasi pertanyaan ini semakin meningkat.
- Keterlambatan Adaptif: Ketika situs target memperbarui logika verifikasi, diperlukan penandaan ulang dan pelatihan manual (siklus yang berlangsung beberapa hari).
- Penanganan Anomali Kaku: Menghadapi mode pertahanan baru (seperti sampel adversarial), jenis yang serupa sering beralih versi, dan beberapa bahkan secara mandiri meningkatkan probabilitas jenis dengan tingkat lulus rendah. Mesin lama tidak memiliki kemampuan analisis mandiri untuk kontrol risiko ini.
Catatan: LLM tidak menggantikan model CV tetapi menjadi "pusat saraf" dari sistem CV, memberinya kemampuan untuk memahami dan berkembang.
Mekanisme Kerja Pipeline Keputusan
Sistem keseluruhan mengikuti proses tertutup dari Persepsi-Keputusan-Eksekusi-Evolusi, yang dapat dibagi menjadi empat tahap kunci:
Tahap 1: Pengiriman Cerdas
Ketika permintaan gambar baru masuk ke sistem, pertama-tama melewati klasifikator yang didorong LLM untuk pengiriman cerdas:
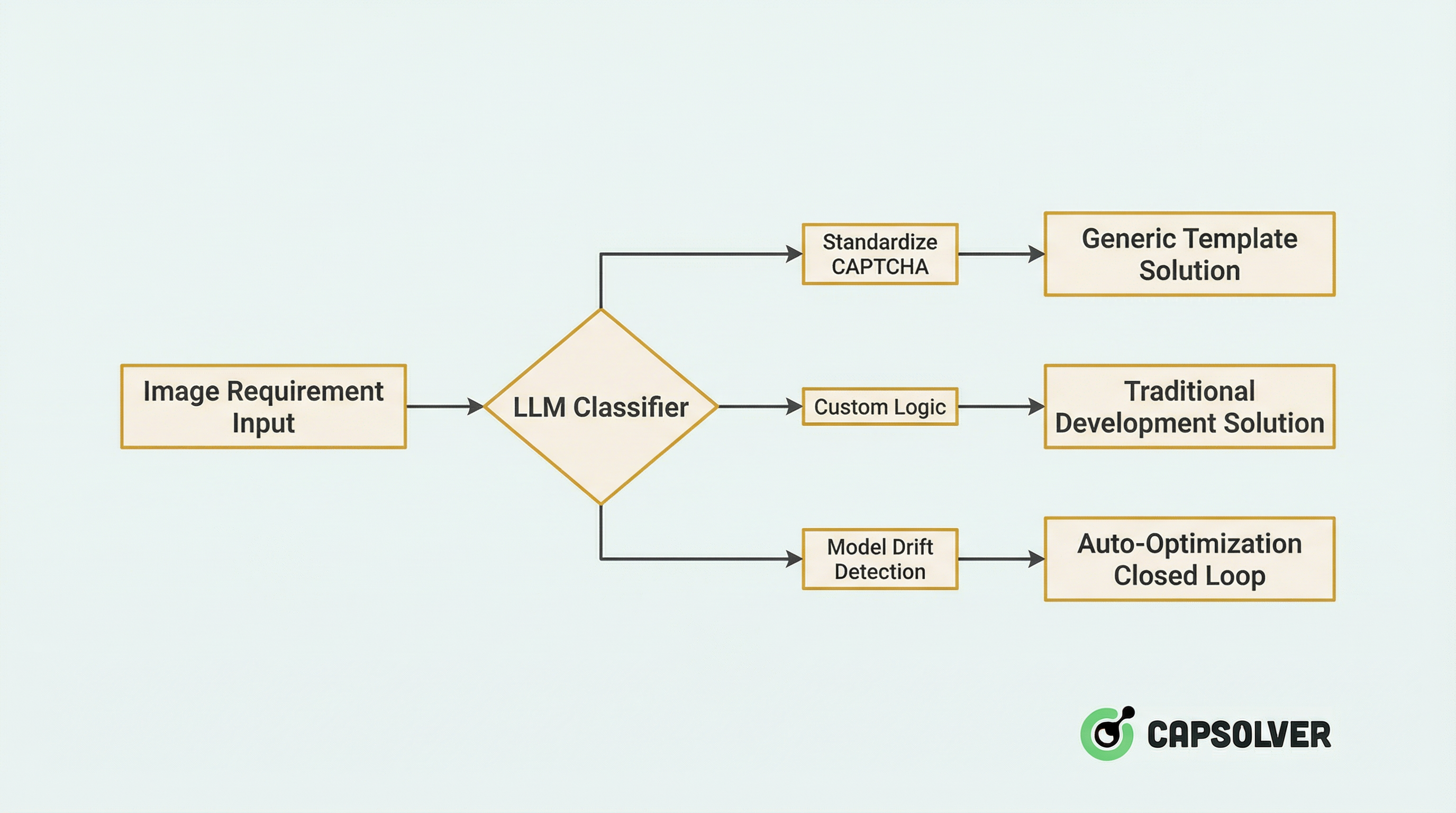
Detail Teknis:
- Klasifikasi Zero-shot: Menggunakan kemampuan pemahaman visual LLM untuk mengidentifikasi jenis CAPTCHA (slider, klik-pilih, rotasi, ReCaptcha, dll.) tanpa pelatihan.
- Penilaian Kepercayaan: Ketika kepercayaan LLM di bawah 0,8, proses tinjauan manual secara otomatis diaktifkan dan sampel tersebut dimasukkan ke dalam set pelatihan bertahap.
Data Praktis: Setelah platform mengintegrasikan sistem pengiriman ini, efisiensi alokasi sumber daya meningkat 47%, dan tingkat kesalahan klasifikasi turun dari 12% menjadi 2,1%.
Tahap 2: Pengembangan Dua Jalur
Berdasarkan hasil klasifikasi, sistem memasuki dua jalur teknis yang berbeda:
Jalur A: Jalur Low-Code (Respons Cepat melalui Template Umum)
Berlaku untuk CAPTCHA standarisasi seperti reCAPTCHA:
Perpustakaan Template Universal
language
├── Penglabelan Awal LLM: Secara otomatis menghasilkan kotak batas dan label semantik
├── Model yang Telah Dilatih: Detektor umum yang dilatih pada jutaan sampel
└── Pascaproses LLM: Koreksi semantik (misalnya, membedakan 0/O, 1/l, menghapus duplikat)Inovasi Utama — Roda Penglabelan Cerdas:
- LLM menghasilkan pseudo-label melalui pembelajaran few-shot.
- Data berkualitas tinggi yang dikoreksi melalui tinjauan manual kembali masuk ke dalam pool pelatihan.
- Biaya penglabelan berkurang 60%, sementara keragaman data meningkat 3 kali lipat.
Jalur B: Jalur Pro-Code (Pengembangan Kustomisasi Mendalam)
Mengarah pada CAPTCHA kustomisasi tingkat perusahaan (misalnya, algoritma slider khusus, logika sudut rotasi):
Pipeline Pengembangan Tradisional
language
├── Pemilihan/Perangkai Model (Deteksi + Pengenalan + Keputusan)
├── Pemrosesan Data: Pembersihan → Labeling → Generasi Sampel Adversarial (Dukungan LLM: Pengujian Akurasi dan Pemfilteran Data Baru)
└── Pelatihan Berkelanjutan: Mendukung pembelajaran bertahap dan adaptasi domainPeran LLM dalam Generasi Data:
- Generasi Gambar: Menggunakan model Diffusion untuk menghasilkan gambar latar yang beragam dan gambar target.
- Generasi Teks: LLM menghasilkan sampel teks adversarial (misalnya, font terdistorsi, kabur, gambar kecil objek nyata yang digambar secara abstrak) atau teks instruksi ("Silakan klik semua gambar yang berisi xx").
- Generasi dan Variasi Aturan: Menggabungkan teks dan informasi untuk mensimulasikan aturan kombinasi gambar dan mekanisme verifikasi kontrol risiko secara real-time melalui GANs.
- Mekanisme Verifikasi: Menggunakan model ViT untuk memverifikasi dan memfilter data, meningkatkan tingkat sampel positif.
Tahap 3: Loop Evolusi Mandiri (Inti Kerangka)
Ini adalah bagian paling revolusioner dari arsitektur. Sistem mencapai evolusi mandiri melalui pipeline AIops → Analisis LLM → Optimisasi Otomatis:
Pengembangan Model → Layanan Online → Pemantauan Anomali → Analisis Akar Penyebab LLM → Pembuatan Rencana Optimasi → Pelatihan Otomatis → Pengenalan Canary
Enam Modul Keputusan Utama LLM:
| Modul Fungsional | Peran Spesifik | Nilai Bisnis |
|---|---|---|
| Ringkasan Informasi | Mengumpulkan log kesalahan, mengidentifikasi pola kegagalan (misalnya, "tingkat pengenalan menurun di scene malam") | Mengubah log masif menjadi wawasan yang dapat tindak lanjuti |
| Keputusan Cerdas | Menentukan ambang batas untuk memicu pembaruan model (misalnya, penurunan akurasi >5% selama 1 jam) atau pemberitahuan pembaruan kontrol risiko (penurunan akurasi >30% secara instan) | Mencegah pelatihan berlebihan, menghemat biaya GPU |
| Orkestrasi Proses | Mengotomatisasi pipeline CI/CD dari pengumpulan data → labeling → pelatihan → pengujian → rilis | Memperpendek siklus iterasi dari hari ke jam |
| Solusi Otomatis | Menghasilkan strategi augmentasi data (misalnya, menggabungkan latar yang dihasilkan aturan dengan target baru yang dihasilkan atau dikumpulkan) | Persiapan data tanpa intervensi manual |
| Pemberitahuan Darurat | Mengidentifikasi pola serangan baru (misalnya, produksi massal sampel adversarial) dan memicu pembaruan kontrol risiko | Waktu respons < 5 menit |
| Distribusi Tugas | Mengalokasikan sampel sulit ke tim labeling dengan panduan labeling yang dihasilkan LLM | Meningkatkan efisiensi labeling sebesar 40% |
Kasus Nyata: Ketika klien e-commerce memperbarui algoritma deteksi celah CAPTCHA slider-nya, sistem tradisional membutuhkan 3-5 hari adaptasi manual. Sistem berbasis LLM menyelesaikan deteksi anomali, analisis akar penyebab, generasi data, dan penyesuaian model dalam 30 menit, segera memulihkan akurasi pengenalan dari 34% menjadi 96,8%.
Tahap 4: Eksekusi Multimodal (Ekspansi Bisnis)
Pengenalan CAPTCHA tidak lagi menjadi tugas gambar murni tetapi proses pengambilan keputusan komprehensif yang mengintegrasikan visi, semantik, dan perilaku. Ekspansi ke jenis baru tidak lagi memiliki batasan waktu dan biaya.
| Jenis CAPTCHA | Solusi Visual | Titik Peningkatan LLM |
|---|---|---|
| CAPTCHA Slider | Deteksi celah (YOLO) + Perbandingan gambar + Simulasi trajektori | LLM menganalisis fitur tekstur celah untuk menghasilkan trajektori geser yang mirip manusia (menghindari gerakan linear kecepatan konstan yang diidentifikasi sebagai bot) |
| CAPTCHA Klik-Pilih | Deteksi objek + Posisi koordinat | LLM memahami instruksi semantik (misalnya, "Sentuh item yang biasanya digunakan bersama item yang ditampilkan"), membuat penalaran kontekstual dalam skenario ambigu |
| CAPTCHA Rotasi | Prediksi regresi sudut | LLM membantu menilai standar penyesuaian visual dan menangani skenario penutupan sebagian |
| ReCaptcha v3 | Analisis biometrik perilaku | LLM menyintesiskan trajektori mouse, interval klik, dan pola scroll halaman untuk menilai manusia-bot |
AIops: Sistem Kekebalan Sistem Otonom
Tanpa jaminan O&M yang andal, bahkan pipeline keputusan yang paling cerdas tidak dapat diterapkan. Lapisan AIops memastikan stabilitas sistem melalui empat kemampuan inti:
1. Deteksi Anomali
- Pemantauan Perubahan Model: Membandingkan distribusi data input dengan distribusi set pelatihan secara real-time (uji KS), memberi peringatan ketika perubahan melebihi ambang batas.
- Pemantauan Penurunan Kinerja: Memantau metrik tiga dimensi tingkat keberhasilan, latensi respons, dan penggunaan GPU.
2. Rollback Cerdas
Ketika versi model baru berkinerja tidak normal, sistem tidak hanya secara otomatis rollback ke versi stabil tetapi juga menghasilkan laporan diagnosis kesalahan melalui analisis LLM, menunjukkan kemungkinan penyebab (misalnya, "overexposure karena proporsi tinggi gambar malam dalam sampel baru").
3. Penjadwalan Sumber Daya Elastis
Pengaturan otomatis berdasarkan prediksi lalu lintas:
- Waktu Puncak (misalnya, Black Friday): Secara otomatis meningkatkan hingga 50 instans GPU.
- Waktu Rendah: Menurunkan hingga 5 instans, memigrasikan data dingin ke penyimpanan objek.
- Penghematan biaya mencapai 65% sambil memastikan ketersediaan 99,99%.
4. Kontrol Risiko dan Pertahanan Adversarial
- Deteksi Sampel Adversarial: Mengidentifikasi gambar CAPTCHA dengan gangguan adversarial (serangan FGSM, PGD).
- Kontrol Risiko Perilaku: Memantau pola permintaan yang tidak biasa (misalnya, permintaan tinggi dari satu IP), secara otomatis memicu verifikasi manusia-bot atau pemblokiran IP.
Jalur Implementasi: Dari POC ke Produksi
Rekomendasi implementasi berdasarkan arsitektur ini dibagi menjadi empat fase:
| Fase | Durasi | Titik Kunci | Metrik Kesuksesan |
|---|---|---|---|
| Fase 1: Infrastruktur | 1-2 Bulan | Membangun dasar pemantauan AIops, mencapai observabilitas seluruh link | MTTR (Rata-rata Waktu Perbaikan) < 15 menit |
| Fase 2: Integrasi | 2-3 Bulan | LLM terintegrasi dalam analisis kesalahan, mencapai laporan diagnosis otomatis | Beban kerja analisis manual berkurang 70% |
| Fase 3: Otomatisasi | 3-4 Bulan | Membangun pipeline pelatihan sepenuhnya otomatis (AutoML + LLM) | Siklus iterasi model < 4 jam |
| Fase 4: Otonomi | 6-12 Bulan | Mencapai loop optimasi mandiri yang didorong LLM | Frekuensi intervensi manual < 1 kali/minggu |
Tantangan dan Strategi Mitigasi
Tantangan 1: Keputusan Salah Akibat Hallusinasi LLM
Solusi:
- Mengadopsi arsitektur RAG (Retrieval-Augmented Generation), mengunci dasar keputusan dalam perpustakaan kasus historis nyata.
- Menyusun node persetujuan manual: Operasi berisiko tinggi seperti rollback model atau penghapusan data memerlukan konfirmasi manual.
Tantangan 2: Biaya di Luar Kendali
Biaya analisis gambar GPT-4V 50-100 kali lebih tinggi dari model CV tradisional.
Solusi:
- Pemrosesan Berlapis: Gunakan model CV ringan (blip, clip, dino, dll.) untuk skenario sederhana, hanya mengirim sampel sulit ke LLM.
- Manajemen Anggaran Token: Menetapkan token maksimum per permintaan untuk menghindari lonjakan biaya dari input yang tidak biasa.
Tantangan 3: Skenario Latensi yang Sensitif
Pengenalan CAPTCHA biasanya membutuhkan respons < 2 detik.
Solusi:
- Analisis Asinkron: Saran optimasi LLM dihasilkan melalui proses asinkron, bukan mengganggu jalur pengenalan real-time.
- Penggunaan di Edge: Menempatkan LLM ringan (misalnya, Qwen3-8b, Llama-3-8B) di node edge, dengan waktu pemrosesan < 500ms.
Kesimpulan: Evolusi dari Alat ke Mitra
Arsitektur AI-LLM CapSolver mewakili perubahan paradigma dalam bidang pengenalan CAPTCHA dari alat statis menjadi agen dinamis. Nilainya tidak hanya terletak pada peningkatan akurasi pengenalan tetapi juga dalam membangun ekosistem teknis yang berkembang sendiri:
- Respons Cepat: Template umum mencapai penyesuaian dalam hitungan menit.
- Kustomisasi Mendalam: Pengembangan tradisional mendukung logika bisnis kompleks.
- Evolusi Berkelanjutan: Loop tertutup yang didorong LLM memastikan sistem tetap up-to-date.
"Sistem AI masa depan tidak akan dipelihara oleh manusia, tetapi akan menjadi mitra digital yang bekerja sama dengan manusia dan berkembang secara otomatis."
Dengan evolusi terus-menerus dari model besar multimodal (seperti GPT-4o, Gemini 1.5 Pro), kita memiliki alasan untuk percaya bahwa pengenalan CAPTCHA tidak lagi menjadi konfrontasi teknis melelahkan, tetapi proses negosiasi otomatis yang efisien, aman, dan dapat dipercaya antara sistem AI.
Coba sendiri! Gunakan kode
CAP26saat mendaftar di CapSolver untuk mendapatkan kredit bonus!
Pertanyaan yang Sering Diajukan (FAQ)
Q1: Apakah penambahan LLM meningkatkan latensi pengenalan?
A: Melalui desain arsitektur berlapis, jalur pengenalan real-time masih ditangani oleh model CV yang dioptimalkan (latensi < 200ms). LLM terutama bertanggung jawab untuk analisis offline dan optimasi strategi. Untuk skenario kompleks yang memerlukan pemahaman semantik, LLM ringan yang ditempatkan di edge (latensi < 500ms) atau mode pemrosesan asinkron dapat digunakan.
Q2: Bagaimana cara mengatasi keputusan salah oleh LLM?
A: Implementasikan mekanisme Human-in-the-loop: Operasi berisiko tinggi (misalnya, rollback model penuh, penghapusan sumber data) memerlukan persetujuan manual. Di sisi lain, bangun lingkungan pengujian sandbox di mana semua rencana optimasi yang dihasilkan LLM harus diverifikasi melalui pengujian A/B sebelum diterapkan secara penuh.
Q3: Apakah arsitektur ini cocok untuk tim kecil?
A: Ya. Disarankan penerapan bertahap: Awalnya, gunakan hanya API LLM berbasis awan (misalnya, Claude 3 Haiku) untuk analisis anomali tanpa membangun model besar; gunakan alat open-source (LangChain, MLflow) untuk membangun pipeline. Saat bisnis berkembang, secara bertahap tambahkan penyebaran pribadi dan otomatisasi AIops.
Q4: Bagaimana perbandingan biayanya dibanding solusi CV murni tradisional?
A: Investasi awal meningkat sekitar 30-40% (terutama untuk panggilan API LLM dan transformasi teknis), tetapi pengurangan biaya O&M manual melalui otomatisasi biasanya mengimbangi investasi tambahan dalam 3-6 bulan. Dalam jangka panjang, karena efisiensi iterasi model yang ditingkatkan dan tingkat otomatisasi yang lebih tinggi, Biaya Total Pemilikan (TCO) dapat dikurangi lebih dari 50%.
Pernyataan Kepatuhan: Informasi yang diberikan di blog ini hanya untuk tujuan informasi. CapSolver berkomitmen untuk mematuhi semua hukum dan peraturan yang berlaku. Penggunaan jaringan CapSolver untuk kegiatan ilegal, penipuan, atau penyalahgunaan sangat dilarang dan akan diselidiki. Solusi penyelesaian captcha kami meningkatkan pengalaman pengguna sambil memastikan kepatuhan 100% dalam membantu menyelesaikan kesulitan captcha selama pengambilan data publik. Kami mendorong penggunaan layanan kami secara bertanggung jawab. Untuk informasi lebih lanjut, silakan kunjungi Syarat Layanan dan Kebijakan Privasi.
Lebih lanjut

Meningkatkan Otomatisasi Perusahaan: Infrastruktur Berbasis LLM untuk Pengenalan CAPTCHA yang Mulus & Efisiensi Operasional
Ketahui bagaimana Infrastruktur Otomatisasi AI yang didukung LLM mengubah pengenalan CAPTCHA, meningkatkan efisiensi proses bisnis dan mengurangi intervensi manual. Optimalkan operasi otomatis Anda dengan solusi verifikasi canggih.

Adélia Cruz
30-Mar-2026

Memperluas Pengumpulan Data untuk Pelatihan LLM: Menyelesaikan CAPTCHA Secara Skala
Pelajari cara meningkatkan pengumpulan data untuk pelatihan LLM dengan menyelesaikan CAPTCHA dalam jumlah besar. Temukan strategi otomatis untuk membangun dataset berkualitas tinggi untuk model AI.

Nikolai Smirnov
27-Mar-2026

Cara Menyelesaikan CAPTCHA di OpenBrowser Menggunakan CapSolver (Panduan Otomatisasi Agen AI)
Selesaikan CAPTCHA di OpenBrowser dengan CapSolver. Otomatisasi reCAPTCHA, Turnstile, dan lainnya untuk agen AI dengan mudah.

Aloísio Vítor
26-Mar-2026

Cara Menyelesaikan CAPTCHA Apa pun di HyperBrowser Menggunakan CapSolver (Panduan Pemasangan Lengkap)
Selesaikan CAPTCHA apa pun di HyperBrowser dengan CapSolver. Otomatiskan reCAPTCHA, Turnstile, AWS WAF, dan lainnya dengan lebih mudah.

Emma Foster
26-Mar-2026

Menyelesaikan Captcha untuk Agen AI Pemantauan Harga: Panduan Langkah demi Langkah
Pelajari cara menyelesaikan CAPTCHA secara efektif untuk agen AI pemantauan harga dengan CapSolver. Panduan langkah demi langkah ini menjamin pengumpulan data yang tidak terputus dan wawasan pasar yang ditingkatkan.

Lucas Mitchell
25-Mar-2026

Cara Memecahkan CAPTCHA Secara Otomatis dengan NanoClaw dan CapSolver
Panduan langkah demi langkah untuk menggunakan CapSolver dengan NanoClaw untuk menyelesaikan secara otomatis reCAPTCHA, Turnstile, AWS WAF, dan CAPTCHA lainnya. Bekerja dengan agen Claude AI, tanpa kode, dan banyak browser.
Nikolai Smirnov
20-Mar-2026