







なぜAIエージェントのタスクがCAPTCHAにハマるのかとその解決方法

Sora Fujimoto
AI Solutions Architect
09-Jun-2026
TL;DR
- AIエージェントのタスクがCAPTCHAで詰まるのは、エージェントがチャレンジページを通常のウェブページと扱うためである。
- 解決策は、明示的なチャレンジ検出、安定したブラウザ状態、制限されたリトライ、および解決または人間レビューへの明確なシフトである。
- CAPTCHAループは、古いトークン、セッションの変更、悪い待機ロジック、繰り返しの失敗送信からよく発生する。
- 責任あるオートメーションは、サイトの許可、レートリミット、アカウントルール、データの境界を尊重する必要がある。
イントロダクション
AIエージェントのタスクがCAPTCHAで詰まるのは、エージェントがチャレンジ状態のモデルを持っていないためである。ページを読み続け、同じボタンをクリックし、リフレッシュしたり、ブラウザツールに続けさせたりする。このような行動はループを生み、リスク信号を増加させる可能性がある。CapSolverは、CAPTCHA結果が必要な許可されたワークフローに役立つが、エージェントは依然として正しい検出、セッションの安定性、停止条件が必要である。正しい解決策は、CAPTCHAをエージェント計画の第一級の状態として扱い、予期しない視覚的障害として扱わないことである。
エージェントは本質的な状態を見ることができない
AIエージェントのタスクは、スクリーンショットやDOMテキストがしばしば曖昧であるため、CAPTCHAで詰まる。チャレンジ用のiframeが有用なテキストを公開しないこともある。reCAPTCHA v3の失敗は、バックエンド検証後にのみ表示されることがある。CloudflareはJavaScriptの実行後に変化する待機ページを表示することがある。
公式ドキュメントはこの区別の重要性を示している。GoogleはreCAPTCHA v3のスコアベースの説明をこのドキュメントで説明しており、Cloudflareはブラウザ互換性とチャレンジ動作に関する別個のリファレンスを公開している。これらは異なるトラフィック検証フローであり、1つの汎用的な「続けるをクリック」ポリシーは失敗する。
一般的なループ原因
| ループ原因 | そのようす | 解決策 |
|---|---|---|
| チャレンジ検出器がない | エージェントはCAPTCHAページを繰り返し要約する | DOM、URL、iframe、ステータスチェックを追加する |
| トークンを送信するのが遅い | フォーム送信後にCAPTCHAが再び表示される | 送信に近いところで解決する |
| セッションが変更された | プロキシまたはブラウザの再起動後にトークンが拒否される | コンテキストを保持する |
| 遅延のターゲットが間違っている | ページが準備できていない間にクリックする | チャレンジ後の要素を待つ |
| 無制限のリトライ | ブロックが頻繁に発生する | 停止条件を追加する |
エージェントはまずCAPTCHAとは何かを認識すべきである。これは通常のブラウジングとは異なる計画が必要なトラフィック検証状態である。キューのページにはQueue-it CAPTCHAのパスが必要かもしれないが、ニッチなプロバイダーにはMT Captchaワークフローが必要かもしれない。Eコマースタスクには特別な注意が必要であり、EコマースCAPTCHA処理は在庫、チェックアウト、アカウントルールと交差する可能性がある。パブリックデータエージェントはPython CAPTCHAスクレイピングガイドで使用される同じ制限を適用すべきであり、特にデータ収集に触れた場合に注意する必要がある。
CAPTCHA状態機械を設計する
AIエージェントのタスクは、ブラウザツールが単なるテキストではなく状態機械を返すことで、CAPTCHAで詰まることが少なくなる。normal_page、challenge_detected、solving、token_ready、submit_failed、blocked、needs_human_reviewなどの状態を使用する。
ブラウザアクションのタイミングでは、同じ概念がエージェントにも適用される。プランナーは、ブラウザツールがページが通常のコンテンツ、チャレンジ、レートリミット、またはハードブロックであるかどうかを分類するまで、ページに対して行動しないべきである。
CapSolverボーナスコードを取得する
瞬時にオートメーション予算を増やす!
CapSolverアカウントにチャージする際にボーナスコード CAP26 を使用すると、すべてのチャージで 5%のボーナス を受け取れる(制限なし)。
CapSolverダッシュボードで今すぐ取得してください

停止条件は重要である
AIエージェントのタスクは、成功をあまりにも広く定義しているためにCAPTCHAで詰まる。保護されたページでは「完了するまで続ける」は安全ではない。最大試行回数、最大時間、終了エラーを定義する。ページがハードブロックを返すか、ワークフローに認証がない場合は停止する。
機密データのログを避ける。診断に必要なフィールドのみを保持する: チャレンジタイプ、URLパターン、リトライ回数、ネットワークルート、高レベルのエラー。生のトークン、パスワード、または個人アカウントデータは保存しない。
LLMプランニングがCAPTCHAループを悪化させる理由
AIエージェントのタスクは、LLMプランナーがタスクの完了を最適化しやすい傾向があるため、CAPTCHAで詰まる。指示が「ログインしてレポートをダウンロードする」であれば、エージェントはすべての障害を一時的なUIの問題と解釈するかもしれない。CAPTCHAは異なる。これはサイトが挿入したリスク管理状態であり、正しい行動は待つこと、承認された統合を通じて解決すること、人間レビューを依頼すること、または停止することかもしれない。
したがって、ブラウザツールはプランナーが安全でない行動を improvising することを防すべきである。「チェックボックスが見える」と返す代わりに、プロバイダー、信頼度、および許可された次のアクションを含むchallenge_detectedを返す。エージェントは独自に新しいアカウントを作成したり、アイデンティティを切り替えたり、リクエスト量を増やしたりしないべきである。NIST AIリスク管理フレームワークはCAPTCHAマニュアルではないが、有用なガバナンスの参照である: オートメーションは測定され、監視され、制限されるべきである。
広範なエージェントワークフローでは、ソルバーが存在するかどうかではなく、タスクが許可されているかどうか、およびブラウザ状態が一貫しているかどうかが正しい質問である。AIウェブスクレイピングとCAPTCHAの解決ワークフローは、ドメインの範囲、リトライ制限、データの境界を定義すべきである。タスクがパブリックスクレイピングであれば、スクレイピング中にCAPTCHAを解決する3つの方法が回復パスを示し、ウェブスクレイピングとは何かがワークフローのカテゴリを明確にする。CAPTCHA解決サービスを比較するチームは、信頼性、コンプライアンスの適合性、統合の明確さを評価すべきであり、解決を普遍的な許可層として扱わないべきである。
回復プレイブックを追加する
AIエージェントのタスクは、すべてのチャレンジに回復プレイブックがあることで、CAPTCHAで詰まることが少なくなる。プレイブックは5つの質問に答えなければならない。どのチャレンジタイプが存在するか?タスクは許可されているか?解決に必要な十分なチャレンジコンテキストがあるか?ブラウザセッションは安定しているか?最大リトライ予算は何か?いずれかの答えが不明であれば、エージェントは一時停止し、診断情報を返すべきである。
可視画像のCAPTCHAでは、ソルバーまたは人間レビューにルーティングする。reCAPTCHA v3では、アクション名とトークンの新鮮さをチェックする。Cloudflare Turnstileでは、ウィジェットパラメータとブラウザ状態を一致させる。ハード403ページでは停止する。レートリミットページでは、遅くするか再スケジュールする。この分類は、エージェントがすべての保護メカニズムに同じ行動を適用しないようにする。
ブラウザツールを状態ではなくスクリーンショットで設計する
スクリーンショットは人間のデバッグに役立つが、エージェントにとっての弱い主要インターフェースである。AIエージェントのタスクは、プランナーがピクセルを見ているが、背後にある状態を見ていなため、CAPTCHAで詰まる。より良いブラウザツールは、スクリーンショットと構造化されたシグナルの両方を返す: URL、タイトル、利用可能なステータスコード、iframeドメイン、表示されるプロバイダ文字列、フォーム状態、最近のナビゲーションイベント。
Playwrightのロケータガイドは、脆い座標ではなく意味のある要素を選択することを促すための有用なパターンである。LangChainのLangGraphプラットフォームドキュメントも、エージェントシステムを構築する際の明示的なワークフローステートの重要性を反映している。同じデザイン原則はここにも適用される: CAPTCHA処理をスクリーンショットパズルではなく状態遷移としてモデル化する。
ポリシーにコンプライアンスを組み込む
ポリシーレイヤーは明確であるべきである。AIエージェントのタスクは、QA、パブリックモニタリング、内部管理オートメーションなどの無害なワークフローでCAPTCHAで詰まる。それらは、続くべきでないワークフローでも発生する。エージェントは両方のルールが必要である。タスクが認証されていないアクセス、プライベートデータ、資格の乱用、スパム、チェックアウトの乱用、または承認された範囲外のすべてのアクションを要求する場合、停止する。
タスクコンテキストに短いポリシーオブジェクトを追加する: 許可されたドメイン、許可されたアカウント、レートリミット、データカテゴリ、エスカレーションパス。ブラウザツールは、チャレンジが表示されたときにより安全な決定を下せる。ターゲットドメインが許可されていない場合、解決する前にポリシーエラーを返す。ワークフローが許可されているが高リスクであれば、1回の失敗後に人間の承認を求める。
ループ率を製品メトリクスとして測定する
CAPTCHAループを信頼性メトリクスとして扱う。どのタスクがchallenge_detectedに入り、どのタスクが回復し、どのタスクがポリシーで停止し、どのタスクが同じチャレンジを繰り返すかを追跡する。高いループ率は、弱いブラウザ状態、悪いプロキシの品質、曖昧なエージェントプロンプト、または検出カバーの欠如を示す可能性がある。これらの根本原因を修正することで、タスクの完了率が向上し、不要なトラフィックが減少する。
最高のAIエージェントのCAPTCHA処理は退屈である: 検出、決定、一度の行動、ブロック時にクリーンに停止する。目標はエージェントをより頑なにすることではなく、より正確で責任あるものにすることである。
プロンプトとツールの説明を確認する
AIエージェントのタスクは、ブラウザツールをどのウェブサイトタスクでも完了できると説明することで、CAPTCHAで詰まる。ツールの説明を書き直して、保護されたページで何が起こるかを示す。たとえば、ブラウザツールはパブリックページをブラウズし、許可されたフォームを入力し、チャレンジ状態を報告できる。トラフィック検証を通じたアクセスの保証、新しいアイデンティティの作成、ハード拒否後の継続はできない。明確なツールの説明は、プランナーがCAPTCHAを小さなUI要素として扱う可能性を減らす。
タスクプロンプトも許容される結果を定義すべきである。「承認されたアカウントがアクセスできる場合、レポートをダウンロードする」は「何があってもレポートをダウンロードする」よりも安全である。「ページごとに最大1回のリクエストでパブリック価格を収集する」は「サイト全体をスクレイピングする」よりも安全である。これらの小さなプロンプトの違いは、エージェントがCAPTCHAに遭遇したときの反応を形作る。目標は成功した完了だけでなく、許可された境界内で成功した完了である。
実際に役立つ人間レビューを追加する
人間レビューは曖昧な逃避手段であってはならない。特定の決定に使用する: 認証の確認、ポリシーが許可されている場合のチャレンジの完了、レートリミット後のリトライの承認、タスクを停止すべきかどうかの決定。エージェントは、ターゲットドメイン、タスクの目的、チャレンジタイプ、リトライ回数、許可された場合のサニタイズされたスクリーンショットを含む簡潔なパケットをリビューに送る。生の資格情報、トークン、またはプライベートページデータは送らない。
このレビュー経路は特に新しいドメインで役立つ。チームがサイトのルールと許可されたオートメーションパターンを理解した後、ワークフローはポリシーにエンコードされる。それまでは、人間のチェックポイントはエージェントが繰り返しの失敗を通じて誤った行動を学ぶのを防ぐ。
結論
AIエージェントのタスクは、自動化スタックにチャレンジ認識が欠如しているため、CAPTCHAで詰まる。検出、状態遷移、安定したセッション、制限されたリトライ、責任ある停止条件を追加する。許可されたワークフローでソルバーが適切な場合、CapSolverはCAPTCHA処理ステップを提供し、エージェントはコンテキストとコンプライアンスを管理する。
FAQ
AIエージェントがなぜCAPTCHAページを繰り返しリフレッシュするのですか?
エージェントはおそらくページを終端または特別なチャレンジ状態として認識していません。明示的なチャレンジ検出とリトライ制限を追加してください。
LLMは独自に視覚的なCAPTCHAを解決できますか?
これは信頼性やコンプライアンスのデフォルトとして扱ってはなりません。タスクが許可されている場合、承認されたワークフロー、人間レビュー、または専用のサービスを使用してください。
CAPTCHAループを診断するのに役立つログはありますか?
チャレンジタイプ、URL、リトライ回数、ブラウザコンテキストID、プロキシ地域、最終エラーをログに記録してください。シークレットや個人データは避けてください。
エージェントはいつ停止すべきですか?
制限されたリトライ後、ハード403応答、認証の欠如、繰り返しのトークン拒否、または保護されたデータ境界で停止してください。
コンプライアンス免責事項: このブログで提供される情報は、情報提供のみを目的としています。CapSolverは、すべての適用される法律および規制の遵守に努めています。CapSolverネットワークの不法、詐欺、または悪用の目的での使用は厳格に禁止され、調査されます。私たちのキャプチャ解決ソリューションは、公共データのクローリング中にキャプチャの問題を解決する際に100%のコンプライアンスを確保しながら、ユーザーエクスペリエンスを向上させます。私たちは、サービスの責任ある使用を奨励します。詳細については、サービス利用規約およびプライバシーポリシーをご覧ください。
もっと見る
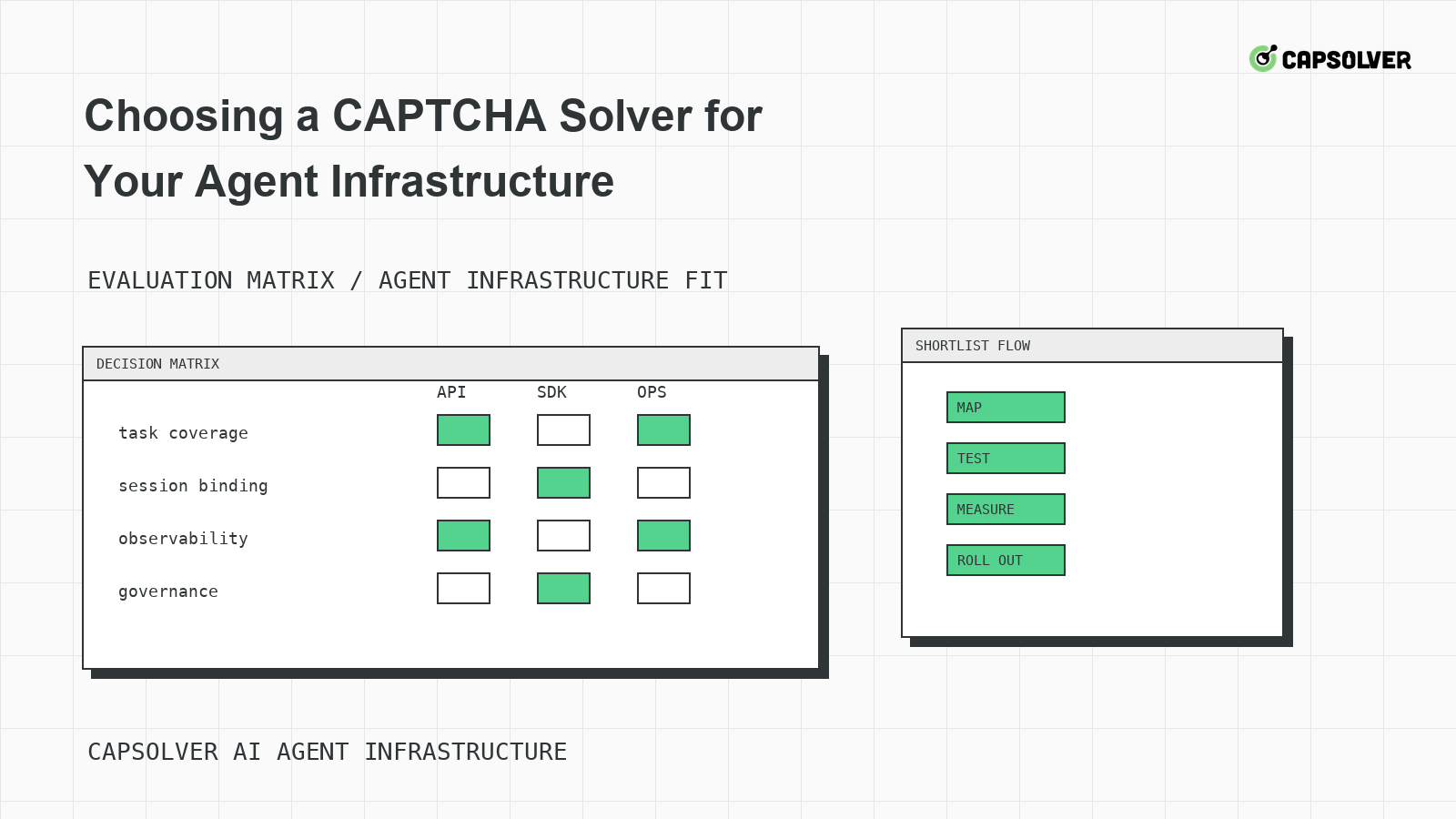
CAPTCHAソルバーの選定: あなたのエージェントインフラストラクチャに最適なものを選ぶ
エージェントインフラストラクチャのCAPTCHAソルバーを選択するための意思決定フレームワークで、チャレンジマッピング、セッションバインディング、観測性、レート制御、および責任ある使用に焦点を当てています。
Sora Fujimoto
18-Jun-2026
2026年のAIエージェント向け最適なCAPTCHA API
2026年向けのAIエージェント用CAPTCHA API選択のための実用的評価ガイド、ドキュメントされたタスクカバレッジ、ポーリング契約、トークン検証、および運用制御を中心に
Sora Fujimoto
18-Jun-2026
エージェンティックブラウザ自動化レイヤーの内部
エージェント型ブラウザ自動化レイヤーの実行時レベルのビュー、DOMに基づく基盤、計画状態、Playwrightスタイルのトレース、課題の処理、および停止ルールに焦点を当てたものです。
Sora Fujimoto
18-Jun-2026
AIエージェント向けのウェブ自動化インフラスタック
AIエージェントによるウェブオートメーションを実行するためのレイヤードインフラストラクチャガイド、ブラウザプール、身分状態、レートリミット、観測性、およびチャレンジ処理に焦点を当てた
Sora Fujimoto
18-Jun-2026
CAPTCHAを解くインフラ for AIエージェント向け
AIエージェント向けCAPTCHAを解くインフラのシステムアーキテクチャガイド、フォーム状態の引き継ぎ、ソルバーのキュー、クールダウン、および監査可能性に焦点を当てたものです。
Sora Fujimoto
18-Jun-2026
AIエージェントにおけるボット保護検出の修正
AIエージェントにおけるボット検出のためのシグナル整合性ガイド、ブラウザファイngerprint、TLSとヘッダー、インタラクションタイミング、コホートテスト、およびストップルールに焦点を当てた
Sora Fujimoto
17-Jun-2026