







Como Usar o Selenium Driverless para Web Scraping Eficiente

Emma Foster
Machine Learning Engineer
14-Jan-2026

A raspagem de web é uma ferramenta essencial para extração e análise de dados. O Selenium, uma ferramenta popular de automação de navegadores, é frequentemente usado para raspagem de web por sua capacidade de interagir com sites com JavaScript pesado. No entanto, um dos desafios do uso do Selenium é a necessidade de um driver de navegador, que pode ser trabalhoso de instalar e gerenciar. Neste post de blog, exploraremos como usar o Selenium para raspagem de web sem um WebDriver tradicional, aproveitando a biblioteca selenium-driverless, tornando o processo mais simplificado e eficiente.
Por que usar o Selenium-Driverless?
Usar a biblioteca selenium-driverless oferece vários benefícios:
- Simplicidade: Não é necessário instalar e gerenciar drivers de navegador tradicionais.
- Portabilidade: Mais fácil de configurar e executar em diferentes sistemas.
- Velocidade: Configuração e execução mais rápidas para suas tarefas de raspagem.
Estressado com a falha repetida em resolver completamente o irritante captcha?
Resgate seu código promocional do CapSolver
Aumente seu orçamento de automação instantaneamente!
Use o código promocional CAPN ao recarregar sua conta do CapSolver para obter um bônus extra de 5% em cada recarga — sem limites.
Resgate-o agora em seu Painel do CapSolver
.
Configurando seu Ambiente
Para começar, você precisará instalar o Selenium e a biblioteca selenium-driverless. Você pode fazer isso facilmente usando pip:
sh
pip install selenium-driverlessEscrevendo seu Primeiro Script com Selenium-Driverless
Aqui está um exemplo simples de como usar selenium-driverless para raspar uma página da web:
python
from selenium_driverless import webdriver
from selenium_driverless.types.by import By
import asyncio
async def main():
options = webdriver.ChromeOptions()
async with webdriver.Chrome(options=options) as driver:
await driver.get('http://nowsecure.nl#relax', wait_load=True)
await driver.sleep(0.5)
await driver.wait_for_cdp("Page.domContentEventFired", timeout=15)
# esperar 10s para o elemento existir
elem = await driver.find_element(By.XPATH, '/html/body/div[2]/div/main/p[2]/a', timeout=10)
await elem.click(move_to=True)
alert = await driver.switch_to.alert
print(alert.text)
await alert.accept()
print(await driver.title)
asyncio.run(main())Boas Práticas
Ao usar o Selenium para raspagem de web, mantenha as seguintes práticas em mente:
- Respeite as políticas do site: Sempre verifique os termos de serviço e o arquivo robots.txt do site para garantir que você tenha permissão para raspar seu conteúdo.
- Use timeouts e atrasos: Evite sobrecarregar o servidor usando timeouts e atrasos entre as solicitações.
- Trate exceções: Implemente tratamento de erros para gerenciar problemas inesperados durante a raspagem.
Conclusão
Usar a biblioteca selenium-driverless simplifica a configuração e a execução de tarefas de raspagem de web. Ao aproveitar esta biblioteca, você pode evitar o transtorno de gerenciar drivers de navegador tradicionais, enquanto ainda aproveita o poder total do Selenium para interagir com sites modernos e com JavaScript pesado. Boa raspagem!
Perguntas Frequentes
1. Qual é a diferença entre Selenium e selenium-driverless?
O Selenium tradicional depende de drivers de navegador externos (como ChromeDriver ou GeckoDriver) para controlar navegadores, que frequentemente exigem instalação manual e gerenciamento de versões. selenium-driverless remove essa dependência ao se comunicar diretamente com o navegador por meio do Protocolo de Ferramentas de Desenvolvimento do Chrome (CDP), resultando em configuração mais simples, melhor portabilidade e menos problemas de compatibilidade.
2. O selenium-driverless é adequado para raspagem em larga escala?
selenium-driverless funciona bem para tarefas de raspagem pequenas a médias, especialmente ao interagir com sites com JavaScript pesado. Para raspagem em larga escala, considerações de desempenho como concorrência, rotação de proxies, limitação de taxa e resolução de CAPTCHA tornam-se críticas. Combinar o selenium-driverless com execução assíncrona, proxies e serviços de resolução automática de CAPTCHA, como o CapSolver, pode melhorar significativamente a escalabilidade.
3. O selenium-driverless consegue contornar sistemas de detecção de robôs e CAPTCHA?
Embora o selenium-driverless reduza alguns traços de automação em comparação com o Selenium tradicional, ele não contorna automaticamente sistemas avançados de detecção de robôs ou CAPTCHAS. Os sites ainda podem detectar padrões de comportamento incomuns. Para melhorar as taxas de sucesso, é recomendado usar tempos de interação realistas, cabeçalhos apropriados, rotação de proxies e soluções dedicadas de resolução de CAPTCHA quando necessário.
Declaração de Conformidade: As informações fornecidas neste blog são apenas para fins informativos. A CapSolver está comprometida em cumprir todas as leis e regulamentos aplicáveis. O uso da rede CapSolver para atividades ilegais, fraudulentas ou abusivas é estritamente proibido e será investigado. Nossas soluções de resolução de captcha melhoram a experiência do usuário enquanto garantem 100% de conformidade ao ajudar a resolver dificuldades de captcha durante a coleta de dados públicos. Incentivamos o uso responsável de nossos serviços. Para mais informações, visite nossos Termos de Serviço e Política de Privacidade.
Mais
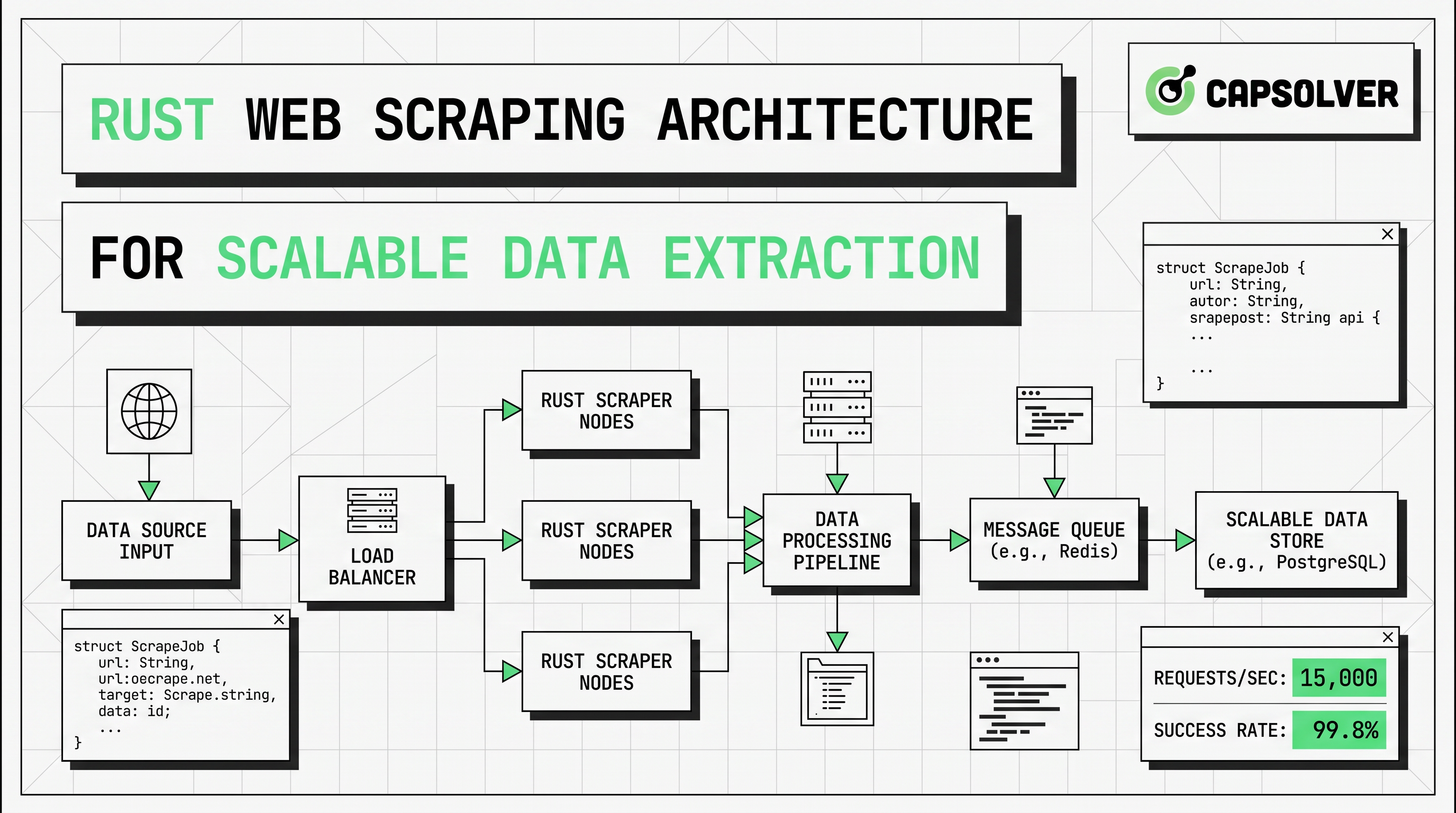
Arquitetura de Web Scraping em Rust para Extração de Dados Escalável
Aprenda arquitetura de raspagem web escalável em Rust com reqwest, scraper, raspagem assíncrona, raspagem de navegador headless, rotação de proxies e tratamento de CAPTCHA compatível.

Adélia Cruz
22-Apr-2026

Selenium vs Puppeteer para Resolução de CAPTCHA: Comparação de Desempenho e Caso de Uso
Compare o Selenium vs Puppeteer para resolver CAPTCHA. Descubra benchmarks de desempenho, notas de estabilidade e como integrar o CapSolver para o máximo de sucesso.

Ethan Collins
08-Apr-2026

Dados como Serviço (DaaS): O que é e por que importa em 2026
Entenda Dados como Serviço (DaaS) em 2026. Descubra seus benefícios, casos de uso e como transforma os negócios com visões em tempo real e escalabilidade.
Ethan Collins
12-Feb-2026

Como corrigir erros comuns de raspagem da web em 2026
Dominar a correção de diversos erros de raspagem de web, como 400, 401, 402, 403, 429, 5xx e 1001 do Cloudflare em 2026. Aprenda estratégias avançadas para rotação de IPs, cabeçalhos e limitação de taxa adaptativa com o CapSolver.

Rajinder Singh
05-Feb-2026

Como resolver Captcha no RoxyBrowser com integração do CapSolver
Integre o CapSolver com o RoxyBrowser para automatizar tarefas do navegador e contornar o reCAPTCHA, o Turnstile e outros CAPTCHAS.
Adélia Cruz
04-Feb-2026

Como resolver Captcha no EasySpider com integração do CapSolver
EasySpider é uma ferramenta de raspagem de web e automação do navegador visual e sem código, e quando combinado com o CapSolver, pode resolver de forma confiável CAPTCHAs como reCAPTCHA v2 e Cloudflare Turnstile, permitindo a extração de dados automatizada sem interrupções em sites.
Adélia Cruz
04-Feb-2026