







Kiến trúc Trí tuệ nhân tạo - Mô hình Ngôn ngữ lớn trong thực tế: Xây dựng dòng chảy quyết định cho hệ thống nhận diện CAPTCHA thích ứng

Anh Tuan
Data Science Expert
09-Feb-2026

CAPTCHAs đã trở nên đa dạng và phức tạp hơn — từ các thử thách văn bản đơn giản đến các câu đố tương tác và logic rủi ro động — và các quy trình tự động hóa ngày nay đòi hỏi nhiều hơn là nhận dạng hình ảnh cơ bản. Các mô hình OCR truyền thống và CNN độc lập gặp khó khăn trong việc theo kịp các định dạng đang thay đổi và các nhiệm vụ thị giác - ngữ nghĩa kết hợp.
Trong bài viết trước, "AI-LLM: Giải pháp tương lai cho nhận dạng hình ảnh và giải CAPTCHA kiểm soát rủi ro," chúng tôi đã khám phá tại sao các mô hình ngôn ngữ lớn đang trở thành thành phần quan trọng trong hệ thống CAPTCHA hiện đại. Bài viết này tiếp nối bằng cách xem xét kiến trúc thực tế đằng sau luồng quyết định AI-LLM của CapSolver: cách các loại CAPTCHA khác nhau được định tuyến đến chiến lược giải quyết phù hợp và cách hệ thống thích ứng khi các định dạng mới xuất hiện.
Thách thức cốt lõi không chỉ là nhận dạng các pixel mà còn hiểu ý định đằng sau CAPTCHA và thích ứng theo thời gian thực. Kiến trúc AI-LLM của CapSolver kết hợp thị giác máy tính với tư duy cấp cao để đưa ra quyết định chiến lược thay vì chỉ nhận diện mẫu.
Dưới đây là tổng quan về kiến trúc đó:
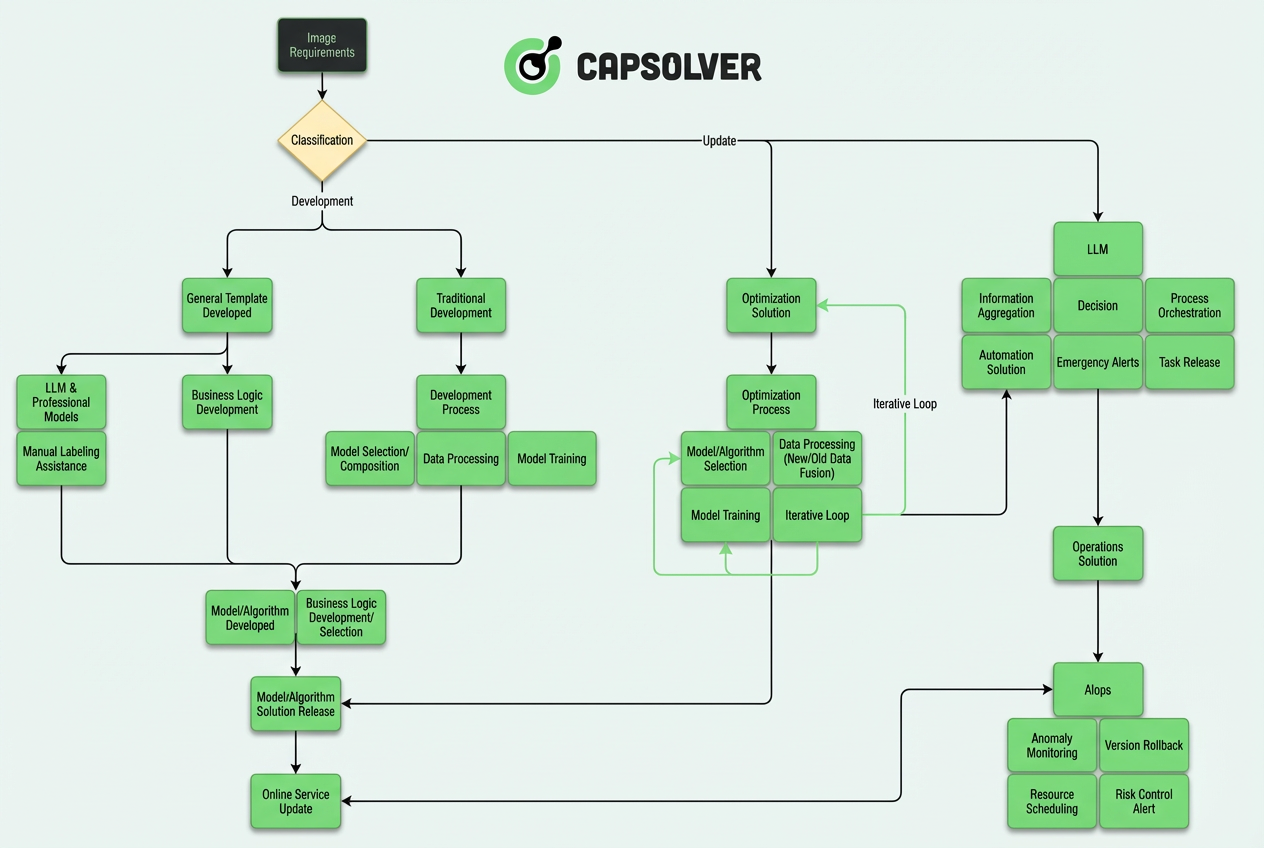
Bài viết này đi sâu vào công nghệ đằng sau hệ thống ba lớp tự động của chúng tôi, kết nối đầu vào thị giác thô và lập luận ngữ nghĩa.
Theo nghiên cứu ngành, đến năm 2026, hơn 80% doanh nghiệp sẽ triển khai các ứng dụng được hỗ trợ AI thế hệ mới trong môi trường sản xuất — nhấn mạnh sự chuyển dịch nhanh chóng sang quy trình tự động, được điều khiển bởi AI và các luồng đa chế độ.
Kiến trúc cốt lõi: Hệ thống ba lớp tự động
Dựa trên thực tiễn kỹ thuật, các hệ thống nhận dạng CAPTCHA hiện đại đã phát triển từ kiến trúc "mô hình + quy tắc" đơn giản thành một hệ thống phức tạp với các lớp tự động. Toàn bộ kiến trúc có thể được chia thành ba lớp cốt lõi:
| Lớp | Modul cốt lõi | Vị trí chức năng | Ví dụ công nghệ |
|---|---|---|---|
| Lớp ra quyết định ứng dụng | Não LLM | Hiểu ngữ nghĩa, phối hợp nhiệm vụ, phân tích bất thường | GPT-4/Vision, Claude 3, Qwen3, Các tác nhân LangChain tự phát triển |
| Lớp thực thi thuật toán | Động cơ CV | Phát hiện đối tượng, mô phỏng quỹ đạo, nhận dạng hình ảnh | YOLO, ViT, blip, clip, dino |
| Lớp đảm bảo O&M | AIops | Giám sát, quay lại, phân bổ tài nguyên, kiểm soát rủi ro | Prometheus, Kubernetes, Chiến lược RL tùy chỉnh |
Ý tưởng cốt lõi của thiết kế lớp này là: LLM chịu trách nhiệm "suy nghĩ", các mô hình CV chịu trách nhiệm "thực thi", và AIops chịu trách nhiệm "đảm bảo".
Tại sao can thiệp LLM là cần thiết?
Hệ thống nhận dạng CAPTCHA truyền thống đối mặt với ba rào cản nghiêm trọng:
- Khoảng cách ngữ nghĩa: Không thể hiểu các văn bản hướng dẫn như "Vui lòng nhấp vào tất cả hình ảnh chứa xx" hoặc "Chạm vào vật thường được sử dụng cùng với vật được hiển thị," trong khi số lượng loại câu hỏi như vậy đang tăng lên.
- Thời gian phản ứng chậm: Khi các trang web mục tiêu cập nhật logic xác minh, cần phải gán nhãn và huấn luyện lại (chu kỳ kéo dài vài ngày).
- Xử lý bất thường cứng nhắc: Đối mặt với các chế độ phòng thủ mới (ví dụ: mẫu xâm nhập), các loại tương tự thường xuyên thay đổi phiên bản, và một số thậm chí tự tăng xác suất các loại có tỷ lệ vượt qua thấp. Các động cơ cũ thiếu khả năng phân tích tự động đối với các biện pháp kiểm soát rủi ro này.
Lưu ý: LLM không thay thế các mô hình CV mà trở thành "trung tâm thần kinh" của hệ thống CV, trang bị cho nó khả năng hiểu và phát triển.
Cơ chế hoạt động của luồng quyết định
Toàn bộ hệ thống tuân theo quy trình vòng kín của Nhận thức - Quyết định - Thực thi - Tiến hóa, có thể được chia nhỏ thành bốn giai đoạn chính:
Giai đoạn 1: Định tuyến thông minh
Khi một yêu cầu hình ảnh mới vào hệ thống, nó trước tiên đi qua bộ phân loại do LLM điều khiển để định tuyến thông minh:
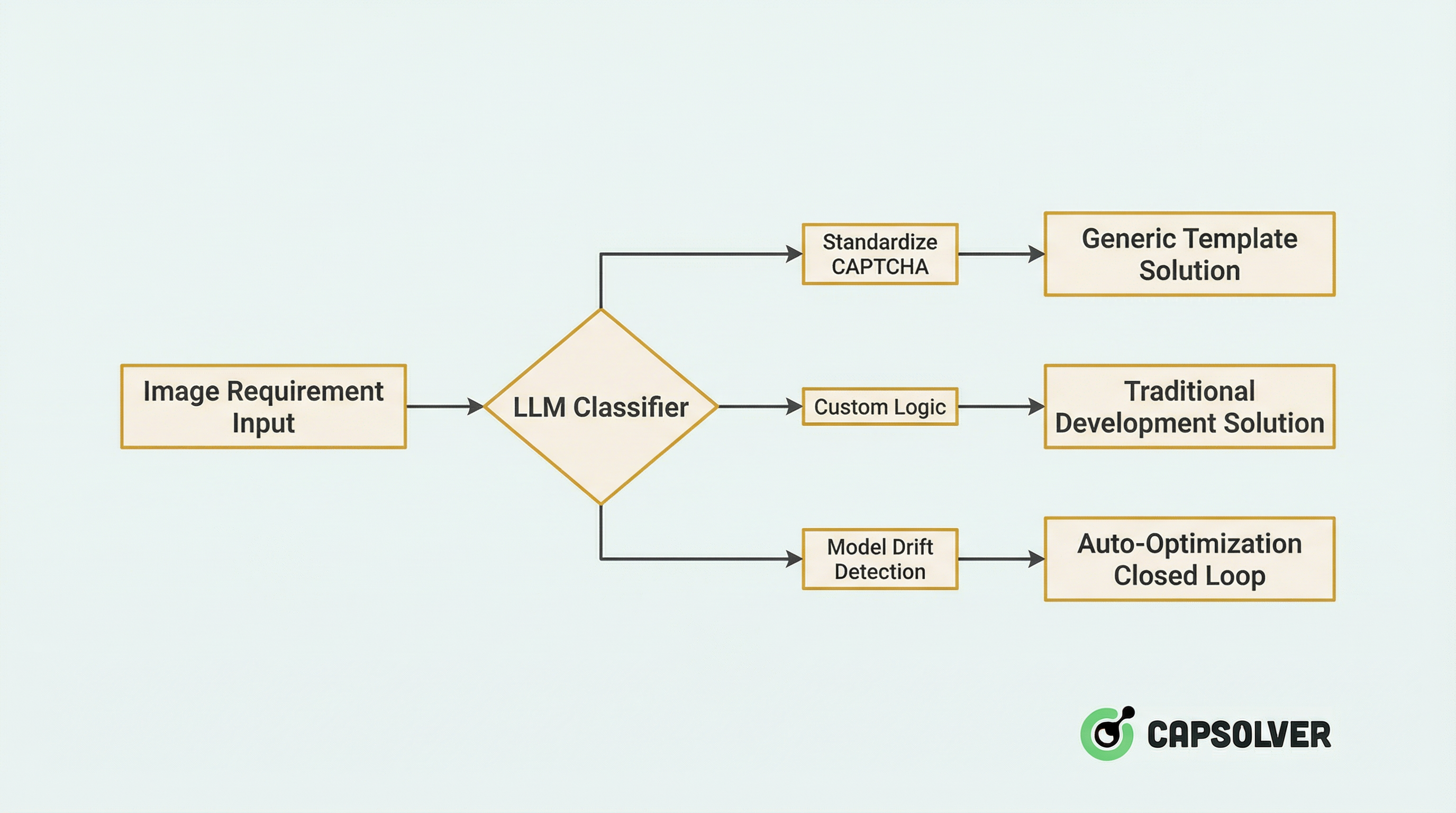
Chi tiết kỹ thuật:
- Phân loại không mẫu (Zero-shot Classification): Sử dụng khả năng hiểu thị giác của LLM để xác định loại CAPTCHA (trượt, chọn chạm, xoay, ReCaptcha, v.v.) mà không cần huấn luyện.
- Đánh giá độ tin cậy: Khi độ tin cậy của LLM dưới 0.8, nó tự động kích hoạt quy trình kiểm tra thủ công và tích hợp mẫu vào tập huấn luyện tăng cường.
Dữ liệu thực tế: Sau khi nền tảng tích hợp hệ thống định tuyến này, hiệu quả phân bổ tài nguyên tăng 47%, và tỷ lệ phân loại sai giảm từ 12% xuống 2.1%.
Giai đoạn 2: Phát triển hai hướng
Dựa trên kết quả phân loại, hệ thống bước vào hai hướng kỹ thuật khác nhau:
Hướng A: Hướng ít mã (Phản hồi nhanh qua mẫu chung)
Áp dụng cho CAPTCHA chuẩn như reCAPTCHA:
Thư viện mẫu chung
language
├── Gán nhãn ban đầu bằng LLM: Tự động tạo hộp giới hạn và nhãn ngữ nghĩa
├── Mô hình đã huấn luyện trước: Bộ phát hiện tổng quát được huấn luyện trên hàng triệu mẫu
└── Xử lý hậu LLM: Sửa lỗi ngữ nghĩa (ví dụ: phân biệt 0/O, 1/l, xóa trùng lặp)Đột phá chính — Vòng quay gán nhãn thông minh:
- LLM tạo nhãn giả thông qua học ít mẫu.
- Dữ liệu chất lượng cao được kiểm tra thủ công chảy ngược vào tập huấn luyện.
- Chi phí gán nhãn giảm 60%, trong khi tính đa dạng dữ liệu tăng 3 lần.
Hướng B: Hướng mã cao (Phát triển tùy chỉnh sâu)
Nhắm đến CAPTCHA tùy chỉnh cấp doanh nghiệp (ví dụ: thuật toán trượt cụ thể, logic góc xoay):
Quy trình phát triển truyền thống
language
├── Chọn lựa/Thành phần mô hình (Phát hiện + Nhận dạng + Quyết định)
├── Xử lý dữ liệu: Làm sạch → Gán nhãn → Tạo mẫu xâm nhập (Hỗ trợ LLM: Kiểm tra độ chính xác và lọc dữ liệu mới)
└── Huấn luyện liên tục: Hỗ trợ học tăng cường và thích ứng miềnVai trò của LLM trong việc tạo dữ liệu:
- Tạo hình ảnh: Sử dụng mô hình phân tán để tạo ra các hình nền đa dạng và hình ảnh mục tiêu.
- Tạo văn bản: LLM tạo mẫu văn bản xâm nhập (ví dụ: chữ bị biến dạng, mờ, hình ảnh nhỏ của các vật thể thực tế được vẽ trừu tượng) hoặc văn bản hướng dẫn ("Vui lòng nhấp vào tất cả hình ảnh chứa xx").
- Tạo quy tắc và biến thể: Kết hợp văn bản và thông tin để mô phỏng các quy tắc kết hợp hình ảnh và cơ chế xác minh kiểm soát rủi ro theo thời gian thực thông qua GANs.
- Cơ chế xác minh: Sử dụng các mô hình liên quan đến ViT để xác minh và lọc dữ liệu, cải thiện tỷ lệ mẫu tích cực.
Giai đoạn 3: Vòng lặp tự phát triển (Lõi khung)
Đây là phần cách mạng nhất của kiến trúc. Hệ thống đạt được sự phát triển tự động thông qua luồng AIops → Phân tích LLM → Tối ưu hóa tự động:
Mô hình phát hành → Dịch vụ trực tuyến → Giám sát bất thường → Phân tích nguyên nhân gốc của LLM → Tạo kế hoạch tối ưu hóa → Huấn luyện lại tự động → Phát hành canary
Sáu mô-đun quyết định chính của LLM:
| Module chức năng | Vai trò cụ thể | Giá trị kinh doanh |
|---|---|---|
| Tóm tắt thông tin | Tổng hợp nhật ký lỗi, xác định các mô hình thất bại (ví dụ: "tỷ lệ nhận dạng giảm trong các cảnh ban đêm") | Biến đổi nhật ký khối lượng lớn thành thông tin hành động |
| Quyết định thông minh | Xác định ngưỡng kích hoạt cập nhật mô hình (ví dụ: độ chính xác giảm >5% trong 1 giờ) hoặc thông báo cập nhật kiểm soát rủi ro (độ chính xác giảm >30% tức thì) | Tránh huấn luyện quá mức, tiết kiệm chi phí GPU |
| Tổ chức quy trình | Tự động tổ chức luồng CI/CD từ thu thập dữ liệu → gán nhãn → huấn luyện → kiểm tra → phát hành | Ngắn gọn chu kỳ phát triển từ ngày xuống giờ |
| Giải pháp tự động | Tạo chiến lược tăng cường dữ liệu (ví dụ: kết hợp nền do quy tắc tạo ra với mục tiêu mới được tạo hoặc thu thập) | Chuẩn bị dữ liệu không can thiệp thủ công |
| Thông báo khẩn cấp | Nhận diện các mô hình tấn công mới (ví dụ: sản xuất hàng loạt mẫu xâm nhập) và kích hoạt cập nhật kiểm soát rủi ro | Thời gian phản hồi < 5 phút |
| Phân công nhiệm vụ | Tự động gán các mẫu khó cho các nhóm gán nhãn với hướng dẫn gán nhãn do LLM tạo ra | Tăng hiệu quả gán nhãn lên 40% |
Trường hợp thực tế: Khi một khách hàng thương mại điện tử cập nhật thuật toán phát hiện khoảng trống của CAPTCHA trượt của họ, các hệ thống truyền thống cần 3-5 ngày để thích ứng thủ công. Hệ thống vòng kín dựa trên LLM hoàn thành phát hiện bất thường, phân tích nguyên nhân gốc, tạo dữ liệu và tinh chỉnh mô hình trong 30 phút, nhanh chóng khôi phục độ chính xác nhận dạng từ 34% lên 96,8%.
Giai đoạn 4: Thực thi đa chế độ (Mở rộng kinh doanh)
Nhận dạng CAPTCHA không còn là nhiệm vụ hình ảnh thuần túy mà là quá trình ra quyết định toàn diện tích hợp thị giác, ngữ nghĩa và hành vi. Việc mở rộng sang các loại mới không còn bị giới hạn về thời gian và chi phí.
| Loại CAPTCHA | Giải pháp thị giác | Điểm tăng cường LLM |
|---|---|---|
| CAPTCHA trượt | Phát hiện khoảng trống (YOLO) + So sánh hình ảnh + Mô phỏng quỹ đạo | LLM phân tích đặc điểm bề mặt khoảng trống để tạo quỹ đạo trượt giống người (tránh chuyển động tuyến tính tốc độ hằng số được nhận diện là bot) |
| CAPTCHA chọn chạm | Phát hiện đối tượng + Vị trí tọa độ | LLM hiểu hướng dẫn ngữ nghĩa (ví dụ: "Chạm vào vật thường được sử dụng cùng với vật được hiển thị"), thực hiện lập luận ngữ cảnh trong các tình huống mơ hồ |
| CAPTCHA xoay | Dự đoán góc quay | LLM hỗ trợ đánh giá tiêu chuẩn căn chỉnh thị giác và xử lý các tình huống bị che khuất một phần |
| ReCaptcha v3 | Phân tích sinh trắc học hành vi | LLM tổng hợp quỹ đạo chuột, khoảng cách nhấp chuột và mô hình cuộn trang để đánh giá người-bot |
AIops: Hệ miễn dịch của hệ thống tự động
Không có đảm bảo O&M đáng tin cậy, ngay cả luồng quyết định thông minh nhất cũng không thể triển khai vào sản xuất. Lớp AIops đảm bảo sự ổn định của hệ thống thông qua bốn khả năng cốt lõi:
1. Phát hiện bất thường
- Giám sát sự dịch chuyển mô hình: So sánh thời gian thực phân phối dữ liệu đầu vào với phân phối tập huấn luyện (kiểm tra KS), cảnh báo khi sự dịch chuyển vượt quá ngưỡng.
- Theo dõi suy giảm hiệu suất: Giám sát ba chỉ số: tỷ lệ thành công, độ trễ phản hồi và tỷ lệ sử dụng GPU.
2. Hoàn tác thông minh
Khi phiên bản mô hình mới hoạt động bất thường, hệ thống không chỉ tự động hoàn tác về phiên bản ổn định mà còn tạo báo cáo chẩn đoán lỗi thông qua phân tích LLM, chỉ ra các nguyên nhân có thể (ví dụ: "quá phơi sáng do tỷ lệ hình ảnh ban đêm cao trong các mẫu mới").
3. Phân bổ tài nguyên linh hoạt
Tự động mở rộng theo dự đoán lưu lượng:
- Thời điểm cao điểm (ví dụ: Black Friday): Tự động mở rộng lên 50 phiên bản GPU.
- Thời điểm ít khách: Thu gọn xuống 5 phiên bản, di chuyển dữ liệu lạnh đến lưu trữ đối tượng.
- Tiết kiệm chi phí đạt 65% trong khi đảm bảo 99,99% khả dụng.
4. Kiểm soát rủi ro và phòng thủ xâm nhập
- Phát hiện mẫu xâm nhập: Nhận diện các hình ảnh CAPTCHA có nhiễu xâm nhập (tấn công FGSM, PGD).
- Kiểm soát rủi ro hành vi: Giám sát các mô hình yêu cầu bất thường (ví dụ: yêu cầu tần suất cao từ một IP), tự động kích hoạt xác minh người-máy hoặc chặn IP.
Đường đi triển khai: Từ POC đến sản xuất
Các khuyến nghị triển khai dựa trên kiến trúc này được chia thành bốn giai đoạn:
| Giai đoạn | Thời gian | Mốc quan trọng | Chỉ số thành công |
|---|---|---|---|
| Giai đoạn 1: Cơ sở hạ tầng | 1-2 Tháng | Xây dựng cơ sở giám sát AIops, đạt được khả năng quan sát toàn chuỗi | MTTR (Thời gian sửa chữa trung bình) < 15 phút |
| Giai đoạn 2: Tích hợp | 2-3 Tháng | Tích hợp LLM vào phân tích lỗi, đạt được báo cáo chẩn đoán tự động | Năng suất phân tích thủ công giảm 70% |
| Giai đoạn 3: Tự động hóa | 3-4 Tháng | Xây dựng luồng huấn luyện tự động hoàn toàn (AutoML + LLM) | Chu kỳ cập nhật mô hình < 4 giờ |
| Giai đoạn 4: Tự chủ | 6-12 Tháng | Đạt được vòng lặp tối ưu hóa tự động do LLM điều khiển | Tần suất can thiệp thủ công < 1 lần/tuần |
Thách thức và chiến lược giảm thiểu
Thách thức 1: Quyết định sai do ảo tưởng của LLM
Giải pháp:
- Áp dụng kiến trúc RAG (Tăng cường truy xuất), gắn cơ sở quyết định vào thư viện các trường hợp thực tế lịch sử.
- Thiết lập nút phê duyệt thủ công: Các thao tác rủi ro cao như hoàn tác mô hình hoặc xóa dữ liệu yêu cầu xác nhận thủ công.
Thách thức 2: Chi phí vượt kiểm soát
Chi phí phân tích hình ảnh của GPT-4V cao gấp 50-100 lần so với các mô hình CV truyền thống.
Giải pháp:
- Xử lý theo lớp: Sử dụng các mô hình CV nhẹ (blip, clip, dino, v.v.) cho các tình huống đơn giản, chỉ gửi các mẫu khó đến LLM.
- Quản lý ngân sách token: Đặt số token tối đa mỗi yêu cầu để tránh tăng chi phí do đầu vào bất thường.
Thách thức 3: Các tình huống có độ trễ nhạy cảm
Nhận dạng CAPTCHA thường yêu cầu phản hồi < 2 giây.
Giải pháp:
- Phân tích bất đồng bộ: Các gợi ý tối ưu hóa của LLM được tạo qua quy trình bất đồng bộ, không chặn đường nhận dạng thời gian thực.
- Triển khai tại biên: Triển khai các mô hình LLM nhẹ (ví dụ: Qwen3-8b, Llama-3-8B) tại nút biên, thời gian xử lý < 500ms.
Kết luận: Sự phát triển từ công cụ đến đối tác
Kiến trúc AI-LLM của CapSolver đại diện cho sự thay đổi mô hình trong lĩnh vực nhận dạng CAPTCHA từ công cụ tĩnh sang đại diện động. Giá trị của nó không chỉ nằm ở việc cải thiện độ chính xác nhận dạng mà còn xây dựng một hệ sinh thái kỹ thuật tự phát triển:
- Phản hồi nhanh hơn: Các mẫu chung đạt thích ứng cấp phút.
- Tùy chỉnh sâu hơn: Phát triển truyền thống hỗ trợ logic kinh doanh phức tạp.
- Tiếp tục phát triển: Các vòng kín do LLM điều khiển đảm bảo hệ thống luôn cập nhật.
"Các hệ thống AI tương lai sẽ không được bảo trì bởi con người, mà sẽ là các đối tác số hợp tác với con người và phát triển tự động."
Với sự phát triển liên tục của các mô hình lớn đa chế độ (như GPT-4o, Gemini 1.5 Pro), chúng tôi có lý do để tin rằng nhận dạng CAPTCHA sẽ không còn là cuộc đối đầu kỹ thuật nhàm chán, mà là quá trình đàm phán tự động hiệu quả, an toàn và đáng tin cậy giữa các hệ thống AI.
Thử nghiệm ngay! Sử dụng mã
CAP26khi đăng ký tại CapSolver để nhận thêm tín dụng!
Các Câu Hỏi Thường Gặp (FAQ)
Câu 1: Việc thêm LLM có làm tăng độ trễ nhận diện không?
Trả lời: Nhờ thiết kế kiến trúc tầng, đường dẫn nhận diện thời gian thực vẫn được xử lý bởi các mô hình CV được tối ưu hóa (độ trễ < 200ms). LLM chủ yếu đảm nhận phân tích ngoại tuyến và tối ưu hóa chiến lược. Đối với các tình huống phức tạp yêu cầu hiểu biết ngữ nghĩa, có thể sử dụng các mô hình LLM nhẹ được triển khai tại biên (độ trễ < 500ms) hoặc chế độ xử lý bất đồng bộ.
Câu 2: Làm thế nào để xử lý các quyết định sai của LLM?
Trả lời: Triển khai cơ chế Con người trong vòng lặp: Các thao tác rủi ro cao (ví dụ: hoàn tác toàn bộ mô hình, xóa nguồn dữ liệu) yêu cầu sự phê duyệt thủ công. Đồng thời, xây dựng môi trường kiểm thử sandbox nơi tất cả các kế hoạch tối ưu do LLM tạo ra phải được kiểm chứng thông qua kiểm thử A/B trước khi triển khai toàn diện.
Câu 3: Kiến trúc này có phù hợp với các nhóm nhỏ không?
Trả lời: Có. Nên triển khai dần dần: Ban đầu, chỉ sử dụng API LLM dựa trên đám mây (ví dụ: Claude 3 Haiku) để phân tích bất thường mà không cần xây dựng các mô hình lớn; sử dụng các công cụ mã nguồn mở (LangChain, MLflow) để xây dựng luồng công việc. Khi doanh nghiệp phát triển, dần dần giới thiệu triển khai riêng và tự động hóa AIops.
Câu 4: Chi phí so với các giải pháp CV thuần túy truyền thống như thế nào?
Trả lời: Đầu tư ban đầu tăng khoảng 30-40% (chủ yếu là chi phí API LLM và chuyển đổi kỹ thuật), nhưng việc giảm chi phí vận hành thủ công nhờ tự động hóa thường bù đắp cho khoản đầu tư tăng thêm trong vòng 3-6 tháng. Về lâu dài, do hiệu quả cải thiện trong việc cập nhật mô hình và tỷ lệ tự động hóa cao hơn, Tổng Chi phí Sở hữu (TCO) có thể giảm hơn 50%.
Tuyên bố Tuân thủ: Thông tin được cung cấp trên blog này chỉ mang tính chất tham khảo. CapSolver cam kết tuân thủ tất cả các luật và quy định hiện hành. Việc sử dụng mạng lưới CapSolver cho các hoạt động bất hợp pháp, gian lận hoặc lạm dụng là hoàn toàn bị cấm và sẽ bị điều tra. Các giải pháp giải captcha của chúng tôi nâng cao trải nghiệm người dùng trong khi đảm bảo tuân thủ 100% trong việc giúp giải quyết các khó khăn về captcha trong quá trình thu thập dữ liệu công khai. Chúng tôi khuyến khích việc sử dụng dịch vụ của chúng tôi một cách có trách nhiệm. Để biết thêm thông tin, vui lòng truy cập Điều khoản Dịch vụ và Chính sách Quyền riêng tư.
Thêm

Nâng cao Tự động hóa Doanh nghiệp: Cơ sở hạ tầng Dựa trên Mô hình Ngôn ngữ Lớn (LLM) cho Nhận dạng CAPTCHA Mượt mà & Hiệu quả Hoạt động
Khám phá cách cơ sở hạ tầng tự động hóa AI được cung cấp bởi Mô hình Ngôn ngữ lớn (LLM) đột phá trong việc nhận diện CAPTCHA, nâng cao hiệu quả quy trình kinh doanh và giảm thiểu sự can thiệp thủ công. Tối ưu hóa các quy trình tự động của bạn với các giải pháp xác minh tiên tiến.
Anh Tuan
30-Mar-2026

Mở rộng thu thập dữ liệu cho huấn luyện LLM: Giải quyết CAPTCHAs ở quy mô lớn
Hãy học cách mở rộng thu thập dữ liệu cho việc huấn luyện mô hình LLM bằng cách giải CAPTCHAs quy mô lớn. Khám phá các chiến lược tự động để xây dựng các bộ dữ liệu chất lượng cao cho các mô hình AI.

Ethan Collins
27-Mar-2026

Làm thế nào để giải CAPTCHA trong OpenBrowser bằng cách sử dụng CapSolver (Hướng dẫn tự động hóa AI Agent)
Giải CAPTCHA trong OpenBrowser bằng CapSolver. Tự động hóa reCAPTCHA, Turnstile và hơn thế nữa cho các tác nhân AI một cách dễ dàng.
Anh Tuan
26-Mar-2026

Cách giải CAPTCHA bất kỳ trong HyperBrowser bằng CapSolver (Hướng dẫn cài đặt đầy đủ)
Giải bất kỳ CAPTCHA nào trong HyperBrowser bằng CapSolver. Tự động hóa reCAPTCHA, Turnstile, AWS WAF và nhiều thứ khác một cách dễ dàng.
Anh Tuan
26-Mar-2026

Giải quyết CAPTCHA cho các tác nhân AI theo dõi giá: Hướng dẫn từng bước
Học cách giải quyết hiệu quả CAPTCHAs cho các trợ lý AI theo dõi giá cả với CapSolver. Hướng dẫn từng bước này đảm bảo thu thập dữ liệu không gián đoạn và nhìn nhận thị trường được cải thiện.

Rajinder Singh
24-Mar-2026

Cách giải CAPTCHA bằng TinyFish AgentQL – Hướng dẫn từng bước sử dụng CapSolver
Học cách tích hợp CapSolver với TinyFish AgentQL để giải CAPTCHA tự động như reCAPTCHA và Cloudflare Turnstile. Hướng dẫn từng bước với các ví dụ SDK Python và JavaScript để tự động hóa web dựa trên AI liền mạch.

Nikolai Smirnov
23-Mar-2026