







将Crawlab与CapSolver集成:用于分布式爬虫的自动验证码解决

Emma Foster
Machine Learning Engineer
09-Jan-2026

大规模管理网络爬虫需要能够处理现代反机器人挑战的稳健基础设施。Crawlab 是一个强大的分布式网络爬虫管理平台,CapSolver 是一个基于人工智能的验证码解决服务。它们共同构建了可以自动绕过验证码挑战的企业级爬虫系统。
本指南提供了将CapSolver集成到Crawlab爬虫中的完整、可直接使用的代码示例。
你将学到的内容
- 使用Selenium解决reCAPTCHA v2
- 解决Cloudflare Turnstile
- Scrapy中间件集成
- Node.js/Puppeteer集成
- 大规模验证码处理的最佳实践
什么是Crawlab?
Crawlab 是一个分布式网络爬虫管理平台,旨在跨多种编程语言管理爬虫。
关键功能
- 语言无关性:支持Python、Node.js、Go、Java和PHP
- 框架灵活性:适用于Scrapy、Selenium、Puppeteer、Playwright
- 分布式架构:通过主节点/工作节点实现水平扩展
- 管理UI:用于爬虫管理和调度的网页界面
安装
bash
# 使用Docker Compose
git clone https://github.com/crawlab-team/crawlab.git
cd crawlab
docker-compose up -d在 http://localhost:8080 访问UI(默认用户名:admin/密码:admin)。
什么是CapSolver?
CapSolver 是一个基于人工智能的验证码解决服务,为各种验证码类型提供快速可靠的解决方案。
支持的验证码类型
- reCAPTCHA:v2、v3和企业版
- Cloudflare:Turnstile和Challenge
- AWS WAF:防护绕过
- 以及更多
API工作流程
- 提交验证码参数(类型、siteKey、URL)
- 接收任务ID
- 轮询解决方案
- 将令牌注入页面
前提条件
- Python 3.8+ 或 Node.js 16+
- CapSolver API密钥 - 立即注册
- Chrome/Chromium浏览器
bash
# Python依赖
pip install selenium requests使用Selenium解决reCAPTCHA v2
解决reCAPTCHA v2的完整Python脚本:
python
"""
Crawlab + CapSolver: reCAPTCHA v2 解决器
使用Selenium解决reCAPTCHA v2挑战的完整脚本
"""
import os
import time
import json
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 配置
CAPSOLVER_API_KEY = os.getenv('CAPSOLVER_API_KEY', 'YOUR_CAPSOLVER_API_KEY')
CAPSOLVER_API = 'https://api.capsolver.com'
class CapsolverClient:
"""CapSolver API客户端用于reCAPTCHA v2"""
def __init__(self, api_key: str):
self.api_key = api_key
self.session = requests.Session()
def create_task(self, task: dict) -> str:
"""创建验证码解决任务"""
payload = {
"clientKey": self.api_key,
"task": task
}
response = self.session.post(
f"{CAPSOLVER_API}/createTask",
json=payload
)
result = response.json()
if result.get('errorId', 0) != 0:
raise Exception(f"CapSolver错误: {result.get('errorDescription')}")
return result['taskId']
def get_task_result(self, task_id: str, timeout: int = 120) -> dict:
"""轮询任务结果"""
for _ in range(timeout):
payload = {
"clientKey": self.api_key,
"taskId": task_id
}
response = self.session.post(
f"{CAPSOLVER_API}/getTaskResult",
json=payload
)
result = response.json()
if result.get('status') == 'ready':
return result['solution']
if result.get('status') == 'failed':
raise Exception("验证码解决失败")
time.sleep(1)
raise Exception("等待解决方案超时")
def solve_recaptcha_v2(self, website_url: str, site_key: str) -> str:
"""解决reCAPTCHA v2并返回令牌"""
task = {
"type": "ReCaptchaV2TaskProxyLess",
"websiteURL": website_url,
"websiteKey": site_key
}
print(f"为 {website_url} 创建任务...")
task_id = self.create_task(task)
print(f"任务已创建: {task_id}")
print("等待解决方案...")
solution = self.get_task_result(task_id)
return solution['gRecaptchaResponse']
def get_balance(self) -> float:
"""获取账户余额"""
response = self.session.post(
f"{CAPSOLVER_API}/getBalance",
json={"clientKey": self.api_key}
)
return response.json().get('balance', 0)
class RecaptchaV2Crawler:
"""支持reCAPTCHA v2的Selenium爬虫"""
def __init__(self, headless: bool = True):
self.headless = headless
self.driver = None
self.capsolver = CapsolverClient(CAPSOLVER_API_KEY)
def start(self):
"""初始化浏览器"""
options = Options()
if self.headless:
options.add_argument("--headless=new")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--window-size=1920,1080")
self.driver = webdriver.Chrome(options=options)
print("浏览器已启动")
def stop(self):
"""关闭浏览器"""
if self.driver:
self.driver.quit()
print("浏览器已关闭")
def detect_recaptcha(self) -> str:
"""检测reCAPTCHA并返回site key"""
try:
element = self.driver.find_element(By.CLASS_NAME, "g-recaptcha")
return element.get_attribute("data-sitekey")
except:
return None
def inject_token(self, token: str):
"""将解决的令牌注入页面"""
self.driver.execute_script(f"""
// 设置g-recaptcha-response文本区域
var responseField = document.getElementById('g-recaptcha-response');
if (responseField) {{
responseField.style.display = 'block';
responseField.value = '{token}';
}}
// 设置所有隐藏的响应字段
var textareas = document.querySelectorAll('textarea[name="g-recaptcha-response"]');
for (var i = 0; i < textareas.length; i++) {{
textareas[i].value = '{token}';
}}
""")
print("令牌已注入")
def submit_form(self):
"""提交表单"""
try:
submit = self.driver.find_element(
By.CSS_SELECTOR,
'button[type="submit"], input[type="submit"]'
)
submit.click()
print("表单已提交")
except Exception as e:
print(f"无法提交表单: {e}")
def crawl(self, url: str) -> dict:
"""处理reCAPTCHA v2的爬虫"""
result = {
'url': url,
'success': False,
'captcha_solved': False
}
try:
print(f"导航到: {url}")
self.driver.get(url)
time.sleep(2)
# 检测reCAPTCHA
site_key = self.detect_recaptcha()
if site_key:
print(f"检测到reCAPTCHA v2! Site key: {site_key}")
# 解决验证码
token = self.capsolver.solve_recaptcha_v2(url, site_key)
print(f"收到令牌: {token[:50]}...")
# 注入令牌
self.inject_token(token)
result['captcha_solved'] = True
# 提交表单
self.submit_form()
time.sleep(2)
result['success'] = True
result['title'] = self.driver.title
except Exception as e:
result['error'] = str(e)
print(f"错误: {e}")
return result
def main():
"""主入口"""
# 检查余额
client = CapsolverClient(CAPSOLVER_API_KEY)
print(f"CapSolver余额: ${client.get_balance():.2f}")
# 创建爬虫
crawler = RecaptchaV2Crawler(headless=True)
try:
crawler.start()
# 爬取目标URL(替换为你的目标)
result = crawler.crawl("https://example.com/protected-page")
print("\n" + "=" * 50)
print("RESULT:")
print(json.dumps(result, indent=2))
finally:
crawler.stop()
if __name__ == "__main__":
main()解决Cloudflare Turnstile
解决Cloudflare Turnstile的完整Python脚本:
python
"""
Crawlab + Capsolver: Cloudflare Turnstile 解决器
解决Turnstile挑战的完整脚本
"""
import os
import time
import json
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import NoSuchElementException
# 配置
CAPSOLVER_API_KEY = os.getenv('CAPSOLVER_API_KEY', 'YOUR_CAPSOLVER_API_KEY')
CAPSOLVER_API = 'https://api.capsolver.com'
class TurnstileSolver:
"""用于Turnstile的CapSolver客户端"""
def __init__(self, api_key: str):
self.api_key = api_key
self.session = requests.Session()
def solve(self, website_url: str, site_key: str) -> str:
"""解决Turnstile验证码"""
print(f"解决 {website_url} 的Turnstile")
print(f"Site key: {site_key}")
# 创建任务
task_data = {
"clientKey": self.api_key,
"task": {
"type": "AntiTurnstileTaskProxyLess",
"websiteURL": website_url,
"websiteKey": site_key
}
}
response = self.session.post(f"{CAPSOLVER_API}/createTask", json=task_data)
result = response.json()
if result.get('errorId', 0) != 0:
raise Exception(f"CapSolver错误: {result.get('errorDescription')}")
task_id = result['taskId']
print(f"任务已创建: {task_id}")
# 轮询结果
for i in range(120):
result_data = {
"clientKey": self.api_key,
"taskId": task_id
}
response = self.session.post(f"{CAPSOLVER_API}/getTaskResult", json=result_data)
result = response.json()
if result.get('status') == 'ready':
token = result['solution']['token']
print("Turnstile已解决!")
return token
if result.get('status') == 'failed':
raise Exception("Turnstile解决失败")
time.sleep(1)
raise Exception("等待解决方案超时")
class TurnstileCrawler:
"""支持Turnstile的Selenium爬虫"""
def __init__(self, headless: bool = True):
self.headless = headless
self.driver = None
self.solver = TurnstileSolver(CAPSOLVER_API_KEY)
def start(self):
"""初始化浏览器"""
options = Options()
if self.headless:
options.add_argument("--headless=new")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
self.driver = webdriver.Chrome(options=options)
def stop(self):
"""关闭浏览器"""
if self.driver:
self.driver.quit()
def detect_turnstile(self) -> str:
"""检测Turnstile并返回site key"""
try:
turnstile = self.driver.find_element(By.CLASS_NAME, "cf-turnstile")
return turnstile.get_attribute("data-sitekey")
except NoSuchElementException:
return None
def inject_token(self, token: str):
"""注入Turnstile令牌"""
self.driver.execute_script(f"""
var token = '{token}';
// 查找cf-turnstile-response字段
var field = document.querySelector('[name="cf-turnstile-response"]');
if (field) {{
field.value = token;
}}
// 查找所有Turnstile输入
var inputs = document.querySelectorAll('input[name*="turnstile"]');
for (var i = 0; i < inputs.length; i++) {{
inputs[i].value = token;
}}
""")
print("令牌已注入!")
def crawl(self, url: str) -> dict:
"""处理Turnstile的爬虫"""
result = {
'url': url,
'success': False,
'captcha_solved': False,
'captcha_type': None
}
try:
print(f"导航到: {url}")
self.driver.get(url)
time.sleep(3)
# 检测Turnstile
site_key = self.detect_turnstile()
if site_key:
result['captcha_type'] = 'turnstile'
print(f"检测到Turnstile! Site key: {site_key}")
# 解决
token = self.solver.solve(url, site_key)
# 注入
self.inject_token(token)
result['captcha_solved'] = True
time.sleep(2)
result['success'] = True
result['title'] = self.driver.title
except Exception as e:
print(f"错误: {e}")
result['error'] = str(e)
return result
def main():
"""主入口"""
crawler = TurnstileCrawler(headless=True)
try:
crawler.start()
# 爬取目标(替换为你的目标URL)
result = crawler.crawl("https://example.com/turnstile-protected")
print("\n" + "=" * 50)
print("RESULT:")
print(json.dumps(result, indent=2))
finally:
crawler.stop()
if __name__ == "__main__":
main()Scrapy集成
包含CapSolver中间件的完整Scrapy爬虫:
python
"""
Crawlab + Capsolver: Scrapy爬虫
包含CAPTCHA解决中间件的完整Scrapy爬虫
"""
import scrapy
import requests
import time
import os
CAPSOLVER_API_KEY = os.getenv('CAPSOLVER_API_KEY', 'YOUR_CAPSOLVER_API_KEY')
CAPSOLVER_API = 'https://api.capsolver.com'
class CapsolverMiddleware:
"""CAPTCHA解决的Scrapy中间件"""
def __init__(self):
self.api_key = CAPSOLVER_API_KEY
def solve_recaptcha_v2(self, url: str, site_key: str) -> str:
"""解决reCAPTCHA v2"""创建任务
response = requests.post(
f"{CAPSOLVER_API}/createTask",
json={
"clientKey": self.api_key,
"task": {
"type": "ReCaptchaV2TaskProxyLess",
"websiteURL": url,
"websiteKey": site_key
}
}
)
task_id = response.json()['taskId']
# 轮询结果
for _ in range(120):
result = requests.post(
f"{CAPSOLVER_API}/getTaskResult",
json={"clientKey": self.api_key, "taskId": task_id}
).json()
if result.get('status') == 'ready':
return result['solution']['gRecaptchaResponse']
time.sleep(1)
raise Exception("超时")class CaptchaSpider(scrapy.Spider):
"""带有CAPTCHA处理的Spider"""
name = "captcha_spider"
start_urls = ["https://example.com/protected"]
custom_settings = {
'DOWNLOAD_DELAY': 2,
'CONCURRENT_REQUESTS': 1,
}
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.capsolver = CapsolverMiddleware()
def parse(self, response):
# 检测reCAPTCHA
site_key = response.css('.g-recaptcha::attr(data-sitekey)').get()
if site_key:
self.logger.info(f"检测到reCAPTCHA: {site_key}")
# 解决CAPTCHA
token = self.capsolver.solve_recaptcha_v2(response.url, site_key)
# 提交表单
yield scrapy.FormRequest.from_response(
response,
formdata={'g-recaptcha-response': token},
callback=self.after_captcha
)
else:
yield from self.extract_data(response)
def after_captcha(self, response):
"""CAPTCHA处理后的页面处理"""
yield from self.extract_data(response)
def extract_data(self, response):
"""页面数据提取"""
yield {
'title': response.css('title::text').get(),
'url': response.url,
}Scrapy设置 (settings.py)
"""
BOT_NAME = 'captcha_crawler'
SPIDER_MODULES = ['spiders']
Capsolver
CAPSOLVER_API_KEY = 'YOUR_CAPSOLVER_API_KEY'
速率限制
DOWNLOAD_DELAY = 2
CONCURRENT_REQUESTS = 1
ROBOTSTXT_OBEY = True
"""
---
## Node.js/Puppeteer集成
完整的Node.js脚本:
```javascript
/**
* Crawlab + Capsolver: Puppeteer爬虫
* 完整的Node.js脚本用于CAPTCHA解决
*/
const puppeteer = require('puppeteer');
const CAPSOLVER_API_KEY = process.env.CAPSOLVER_API_KEY || 'YOUR_CAPSOLVER_API_KEY';
const CAPSOLVER_API = 'https://api.capsolver.com';
/**
* Capsolver客户端
*/
class Capsolver {
constructor(apiKey) {
this.apiKey = apiKey;
}
async createTask(task) {
const response = await fetch(`${CAPSOLVER_API}/createTask`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
clientKey: this.apiKey,
task: task
})
});
const result = await response.json();
if (result.errorId !== 0) {
throw new Error(result.errorDescription);
}
return result.taskId;
}
async getTaskResult(taskId, timeout = 120) {
for (let i = 0; i < timeout; i++) {
const response = await fetch(`${CAPSOLVER_API}/getTaskResult`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
clientKey: this.apiKey,
taskId: taskId
})
});
const result = await response.json();
if (result.status === 'ready') {
return result.solution;
}
if (result.status === 'failed') {
throw new Error('任务失败');
}
await new Promise(r => setTimeout(r, 1000));
}
throw new Error('超时');
}
async solveRecaptchaV2(url, siteKey) {
const taskId = await this.createTask({
type: 'ReCaptchaV2TaskProxyLess',
websiteURL: url,
websiteKey: siteKey
});
const solution = await this.getTaskResult(taskId);
return solution.gRecaptchaResponse;
}
async solveTurnstile(url, siteKey) {
const taskId = await this.createTask({
type: 'AntiTurnstileTaskProxyLess',
websiteURL: url,
websiteKey: siteKey
});
const solution = await this.getTaskResult(taskId);
return solution.token;
}
}
/**
* 主爬虫函数
*/
async function crawlWithCaptcha(url) {
const capsolver = new Capsolver(CAPSOLVER_API_KEY);
const browser = await puppeteer.launch({
headless: true,
args: ['--no-sandbox', '--disable-setuid-sandbox']
});
const page = await browser.newPage();
try {
console.log(`爬取: ${url}`);
await page.goto(url, { waitUntil: 'networkidle2' });
// 检测CAPTCHA类型
const captchaInfo = await page.evaluate(() => {
const recaptcha = document.querySelector('.g-recaptcha');
if (recaptcha) {
return {
type: 'recaptcha',
siteKey: recaptcha.dataset.sitekey
};
}
const turnstile = document.querySelector('.cf-turnstile');
if (turnstile) {
return {
type: 'turnstile',
siteKey: turnstile.dataset.sitekey
};
}
return null;
});
if (captchaInfo) {
console.log(`${captchaInfo.type}检测到!`);
let token;
if (captchaInfo.type === 'recaptcha') {
token = await capsolver.solveRecaptchaV2(url, captchaInfo.siteKey);
// 注入令牌
await page.evaluate((t) => {
const field = document.getElementById('g-recaptcha-response');
if (field) field.value = t;
document.querySelectorAll('textarea[name="g-recaptcha-response"]')
.forEach(el => el.value = t);
}, token);
} else if (captchaInfo.type === 'turnstile') {
token = await capsolver.solveTurnstile(url, captchaInfo.siteKey);
// 注入令牌
await page.evaluate((t) => {
const field = document.querySelector('[name="cf-turnstile-response"]');
if (field) field.value = t;
}, token);
}
console.log('CAPTCHA已解决并注入!');
}
// 提取数据
const data = await page.evaluate(() => ({
title: document.title,
url: window.location.href
}));
return data;
} finally {
await browser.close();
}
}
// 主执行
const targetUrl = process.argv[2] || 'https://example.com';
crawlWithCaptcha(targetUrl)
.then(result => {
console.log('\n结果:');
console.log(JSON.stringify(result, null, 2));
})
.catch(console.error);最佳实践
1. 带重试的错误处理
python
def solve_with_retry(solver, url, site_key, max_retries=3):
"""带重试逻辑的CAPTCHA解决"""
for attempt in range(max_retries):
try:
return solver.solve(url, site_key)
except Exception as e:
if attempt == max_retries - 1:
raise
print(f"尝试 {attempt + 1} 失败: {e}")
time.sleep(2 ** attempt) # 指数退避2. 成本管理
- 检测后再解决:仅在检测到CAPTCHA时调用Capsolver
- 缓存令牌:reCAPTCHA令牌有效期约2分钟
- 监控余额:批量任务前检查余额
3. 速率限制
python
# Scrapy设置
DOWNLOAD_DELAY = 3
CONCURRENT_REQUESTS_PER_DOMAIN = 14. 环境变量
bash
export CAPSOLVER_API_KEY="your-api-key-here"故障排除
| 错误 | 原因 | 解决方案 |
|---|---|---|
ERROR_ZERO_BALANCE |
余额不足 | 充值Capsolver账户 |
ERROR_CAPTCHA_UNSOLVABLE |
参数无效 | 验证站点密钥提取 |
TimeoutError |
网络问题 | 增加超时时间,添加重试 |
WebDriverException |
浏览器崩溃 | 添加 --no-sandbox 标志 |
常见问题
Q: CAPTCHA令牌的有效期是多久?
A: reCAPTCHA令牌:约2分钟。Turnstile:根据网站而定。
Q: 平均解决时间是多少?
A: reCAPTCHA v2: 5-15秒,Turnstile: 1-10秒。
Q: 可以使用自己的代理吗?
A: 可以,使用不带"ProxyLess"后缀的任务类型并提供代理配置。
结论
将Capsolver与Crawlab集成可为您的分布式爬虫基础设施提供强大的CAPTCHA处理能力。上述完整脚本可直接复制到您的Crawlab爬虫中。
准备好了吗? 注册Capsolver 并加速您的爬虫!
💡 Crawlab集成用户的独家优惠:
为庆祝此次集成,我们为通过本教程注册的Capsolver用户提供6%的优惠码 — Crawlab。在仪表板中充值时输入该代码即可立即获得额外6%的信用额度。
13. 文档
- 13.1. Crawlab文档
- 13.2. Crawlab GitHub
- 13.3. Capsolver文档
- 13.4. Capsolver API参考
合规声明: 本博客提供的信息仅供参考。CapSolver 致力于遵守所有适用的法律和法规。严禁以非法、欺诈或滥用活动使用 CapSolver 网络,任何此类行为将受到调查。我们的验证码解决方案在确保 100% 合规的同时,帮助解决公共数据爬取过程中的验证码难题。我们鼓励负责任地使用我们的服务。如需更多信息,请访问我们的服务条款和隐私政策。
更多
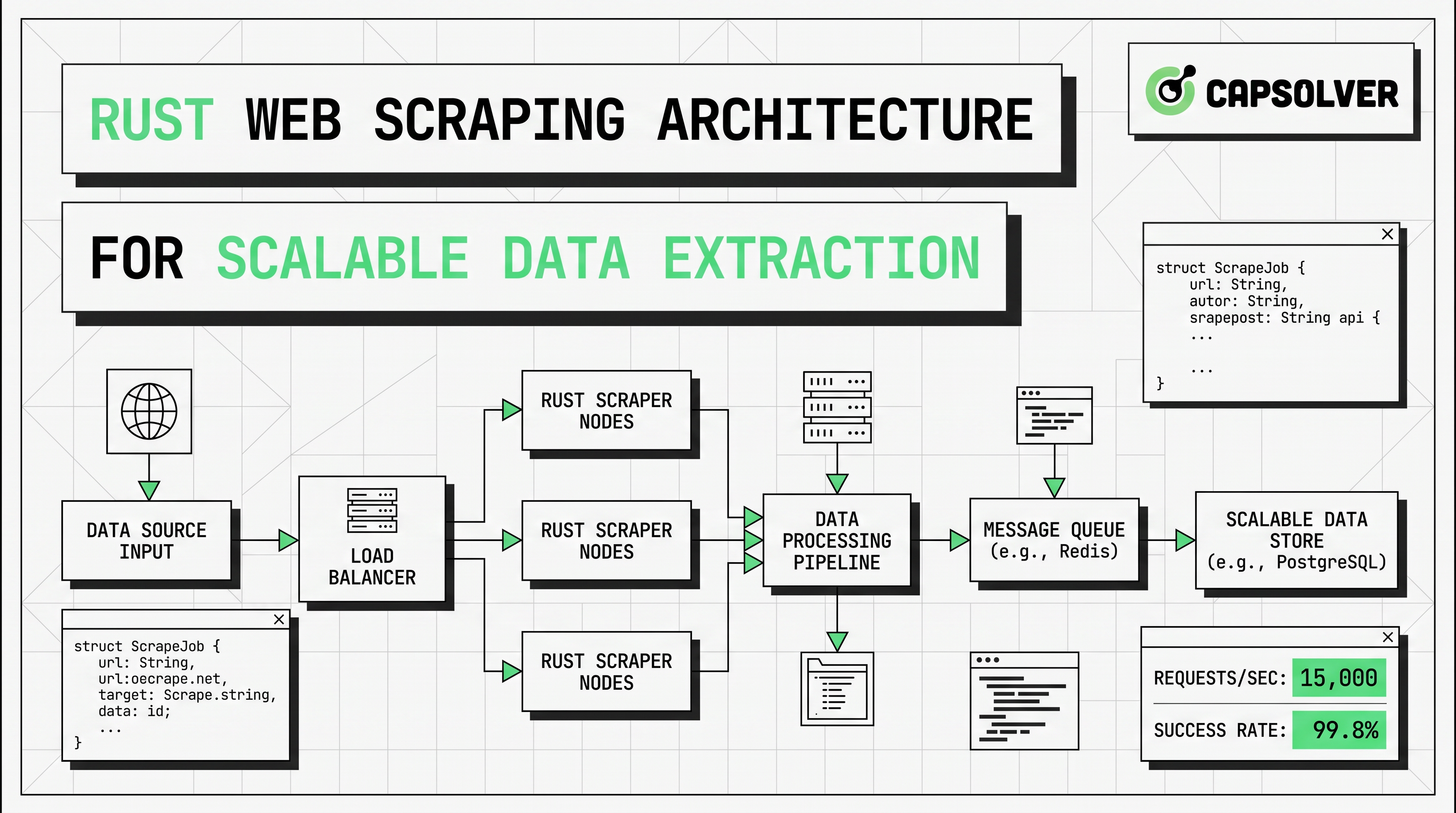
Rust网络爬虫架构:可扩展的数据提取
学习可扩展的Rust网络爬虫架构,包括reqwest、scraper、异步爬取、无头浏览器爬取、代理轮换以及符合规范的验证码处理。

Ethan Collins
22-Apr-2026

面向开发者的浏览器自动化:2026年掌握Selenium与验证码
通过这份2026年指南,掌握浏览器自动化开发。学习Selenium WebDriver Java、Actions接口以及如何使用CapSolver解决验证码。

Sora Fujimoto
02-Mar-2026

如何在Nanobot中使用CapSolver解决验证码
使用 Nanobot 和 CapSolver 自动化验证码解决。使用 Playwright 自主解决 reCAPTCHA 和 Cloudflare。

Anh Tuan
26-Feb-2026

数据即服务(DaaS):它是什么以及为何在2026年重要
了解2026年的数据即服务(DaaS)。探索其优势、应用场景以及如何通过实时洞察和可扩展性改变企业。

Rajinder Singh
12-Feb-2026

如何在RoxyBrowser中通过CapSolver集成解决验证码
将 CapSolver 与 RoxyBrowser 集成,以自动化浏览器任务并绕过 reCAPTCHA、Turnstile 及其他验证码。
Ethan Collins
04-Feb-2026
在 Node.js 中进行网页爬虫:使用 Node Unblocker 和 CapSolver
掌握Node.js中的网络爬虫技术,利用Node Unblocker绕过限制,并使用CapSolver解决CAPTCHAs。本指南提供高效且可靠的数据提取进阶策略。

Lucas Mitchell
04-Feb-2026