







Arquitectura de IA-MLLE en la práctica: Construyendo una cadena de decisión para sistemas de reconocimiento de CAPTCHA adaptativos

Adélia Cruz
Neural Network Developer
10-Feb-2026

Los CAPTCHAs han crecido cada vez más variados y complejos: desde desafíos de texto simples hasta rompecabezas interactivos y lógica de riesgo dinámica, y los flujos de automatización actuales requieren más que reconocimiento de imágenes básico. Los OCR tradicionales y los modelos CNN independientes tienen dificultades para mantenerse al día con los formatos en evolución y las tareas visuales y semánticas mixtas.
En nuestro artículo anterior, "AI-LLM: La solución futura para el reconocimiento de imágenes y resolución de CAPTCHA con control de riesgos", exploramos por qué los modelos de lenguaje a gran escala (LLM) se están convirtiendo en un componente clave en los sistemas de CAPTCHA modernos. Este artículo se basa en ese análisis para examinar la arquitectura práctica detrás de la cadena de decisiones de CapSolver: cómo los diferentes tipos de CAPTCHA se redirigen a la estrategia correcta de resolución y cómo el sistema se adapta a medida que surgen nuevos formatos.
El desafío principal no es solo reconocer píxeles, sino entender la intención detrás de un CAPTCHA y adaptarse en tiempo real. La arquitectura de CapSolver AI-LLM combina visión por computadora con razonamiento de alto nivel para tomar decisiones estratégicas en lugar de solo coincidencias de patrones.
A continuación, una visión general de esa arquitectura:
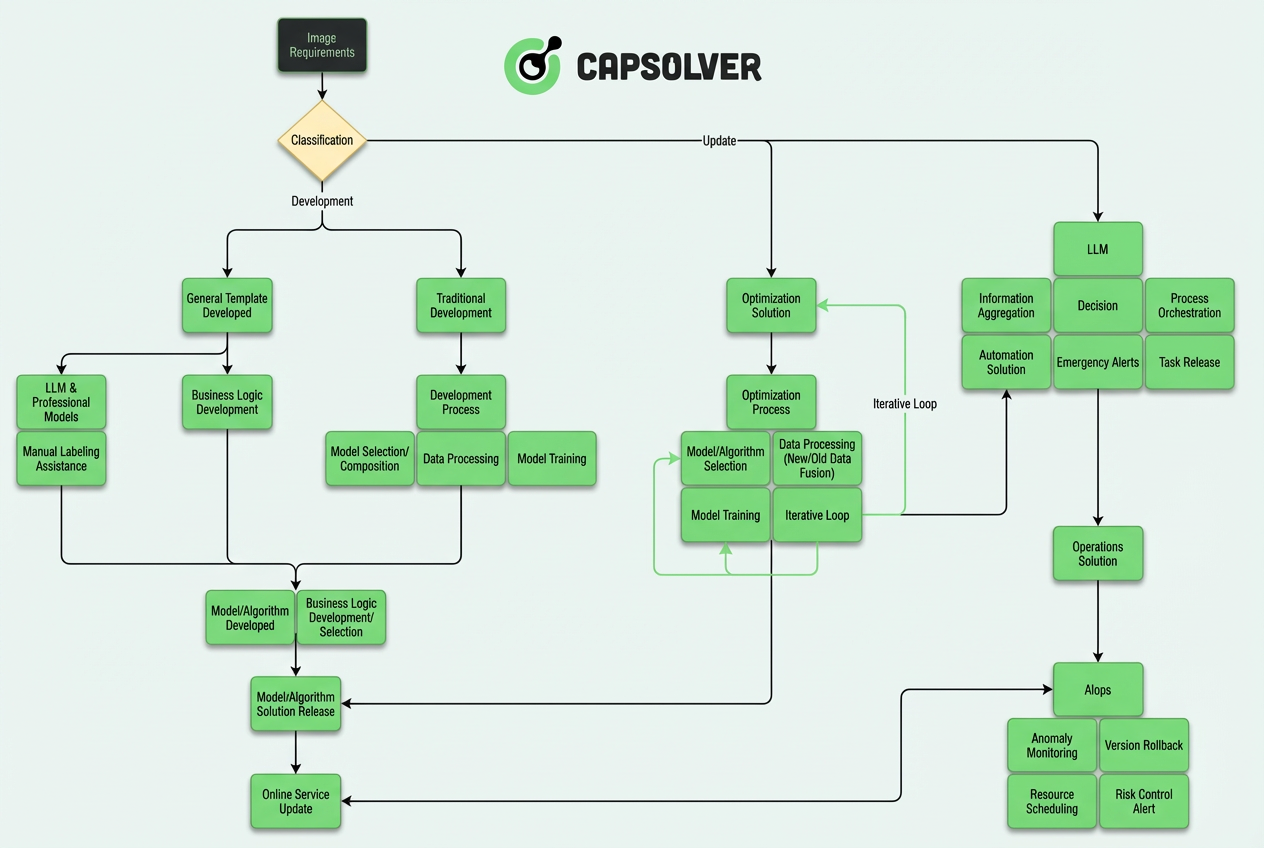
Este artículo se adentra en la ingeniería detrás de nuestro sistema autónomo de tres capas, que conecta la entrada visual cruda con el razonamiento semántico.
Según investigación de la industria, para 2026 más del 80% de las empresas habrán implementado aplicaciones habilitadas por inteligencia artificial generativa en entornos de producción, lo que resalta el rápido cambio hacia flujos de trabajo automatizados, impulsados por IA y pipelines multimodales.
Arquitectura principal: Sistema autónomo de tres capas
Según la práctica de ingeniería, los sistemas modernos de reconocimiento de CAPTCHA han evolucionado de una arquitectura monolítica "modelo + reglas" a un sistema complejo de autonomía por capas. La arquitectura completa se puede dividir en tres capas principales:
| Capa | Módulo principal | Posicionamiento funcional | Ejemplos de stack tecnológico |
|---|---|---|---|
| Capa de Decisión de Aplicación | Cerebro de LLM | Comprensión semántica, orquestación de tareas, análisis de anomalías | GPT-4/Vision, Claude 3, Qwen3, Agentes de LangChain propios |
| Capa de Ejecución de Algoritmos | Motor de CV | Detección de objetos, simulación de trayectoria, reconocimiento de imágenes | YOLO, ViT, blip, clip, dino |
| Capa de Aseguramiento de O&M | AIops | Monitoreo, reversión, programación de recursos, control de riesgos | Prometheus, Kubernetes, estrategias de RL personalizadas |
La idea principal de este diseño por capas es: LLM es responsable de "pensar", los modelos CV son responsables de "ejecutar" y AIops es responsable de "asegurar".
¿Por qué se necesita la intervención de LLM?
El reconocimiento tradicional de CAPTCHA enfrenta tres cuellos de botella fatales:
- Brecha semántica: Incapacidad para entender textos instructivos como "Por favor, haga clic en todas las imágenes que contienen xx" o "Toque el elemento normalmente usado con el elemento mostrado", mientras que la variedad de estos tipos de preguntas aumenta.
- Retraso en la adaptación: Cuando los sitios web objetivo actualizan la lógica de verificación, se requiere reetiquetado y entrenamiento manual (ciclos que duran varios días).
- Manejo rígido de anomalías: Al enfrentar nuevos modos de defensa (como muestras adversarias), los tipos similares cambian frecuentemente de versión, y algunos incluso aumentan de forma autónoma la probabilidad de tipos con bajos índices de éxito. Los motores antiguos carecen de capacidades autónomas de análisis para estos controles de riesgo.
Nota: LLM no reemplaza a los modelos CV, sino que se convierte en el "centro nervioso" del sistema CV, otorgándole la capacidad de comprender y evolucionar.
Mecanismo de trabajo de la cadena de decisiones
El sistema completo sigue un proceso en bucle cerrado de Percepción-Decisión-Ejecución-Evolución, que se puede subdividir en cuatro etapas clave:
Etapa 1: Ruteo inteligente
Cuando una nueva solicitud de imagen entra al sistema, primero pasa a través de un clasificador impulsado por LLM para un ruteo inteligente:
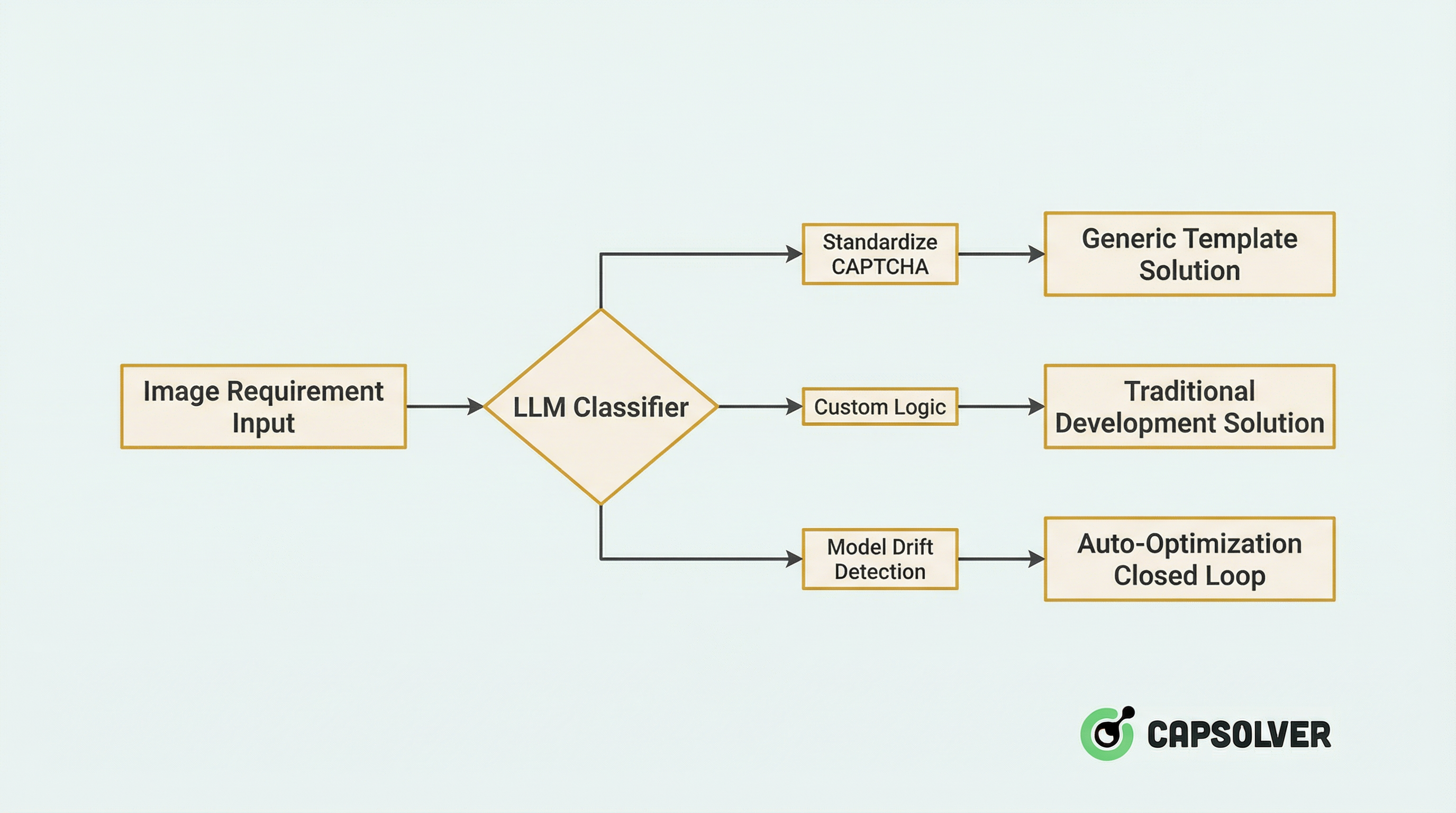
Detalles técnicos:
- Clasificación de cero shots: Utilizando las capacidades de comprensión visual de los LLM para identificar tipos de CAPTCHA (deslizante, selección por clic, rotación, ReCaptcha, etc.) sin entrenamiento.
- Evaluación de confianza: Cuando la confianza de LLM es inferior a 0.8, se activa automáticamente un proceso de revisión manual y se incorpora la muestra al conjunto de entrenamiento incremental.
Datos prácticos: Después de que la plataforma integrara este sistema de ruteo, la eficiencia de asignación de recursos aumentó en un 47%, y la tasa de malclasificación disminuyó del 12% al 2,1%.
Etapa 2: Desarrollo en dos vías
Según los resultados de la clasificación, el sistema entra en dos rutas técnicas diferentes:
Ruta A: Bajo código (Respuesta rápida mediante plantillas generales)
Aplicable a CAPTCHAs estandarizados como reCAPTCHA:
Biblioteca de plantillas universales
language
├── Pre-etiquetado por LLM: Generar automáticamente cuadros delimitadores y etiquetas semánticas
├── Modelos preentrenados: Detectores generales entrenados en millones de muestras
└── Post-procesamiento por LLM: Corrección semántica (por ejemplo, distinguir 0/O, 1/l, eliminar duplicados)Innovación clave — Rueda de etiquetado inteligente:
- LLM genera pseudoetiquetas a través de aprendizaje de pocos ejemplos.
- Los datos de alta calidad corregidos por revisión manual regresan al conjunto de entrenamiento.
- Los costos de etiquetado se reducen en un 60%, mientras que la diversidad de datos aumenta 3 veces.
Ruta B: Pro-Code (Desarrollo profundo personalizado)
Dirigido a CAPTCHAs personalizados a nivel empresarial (por ejemplo, algoritmos de deslizamiento específicos, lógica de ángulo de rotación):
Pipeline de desarrollo tradicional
language
├── Selección/Composición de modelos (Detección + Reconocimiento + Decisión)
├── Procesamiento de datos: Limpieza → Etiquetado → Generación de muestras adversarias (LLM asistido: Pruebas de precisión y filtrado de nuevos datos)
└── Entrenamiento continuo: Soporta aprendizaje incremental y adaptación de dominioPapel de LLM en la generación de datos:
- Generación de imágenes: Usar modelos de difusión para generar imágenes de fondo diversas y objetivos.
- Generación de texto: LLM genera muestras de texto adversario (por ejemplo, fuentes distorsionadas, borrosas, imágenes pequeñas de objetos del mundo real dibujados de forma abstracta) o textos instructivos ("Por favor, haga clic en todas las imágenes que contienen xx").
- Generación y variación de reglas: Combinar texto e información para simular reglas de combinación de imágenes y mecanismos de verificación de control de riesgo en tiempo real mediante GANs.
- Mecanismo de verificación: Usar modelos relacionados con ViT para verificar y filtrar datos, mejorando la tasa de éxito de muestras positivas.
Etapa 3: Bucle de autoevolución (Núcleo del framework)
Esta es la parte más revolucionaria de la arquitectura. El sistema logra evolución autónoma a través del pipeline de AIops → Análisis por LLM → Optimización automática:
Liberación de modelo → Servicio en línea → Monitoreo de anomalías → Análisis de causa raíz por LLM → Generación de plan de optimización → Reentrenamiento automático → Liberación canaria
Seis módulos principales de decisión de LLM:
| Módulo funcional | Rol específico | Valor empresarial |
|---|---|---|
| Resumen de información | Agrega registros de errores, identifica patrones de falla (por ejemplo, "la tasa de reconocimiento disminuye en escenas nocturnas") | Transforma registros masivos en insights accionables |
| Decisión inteligente | Determina umbrales para activar actualizaciones de modelo (por ejemplo, caída de precisión >5% durante 1 hora) o alertas de actualización de control de riesgo (caída de precisión >30% instantáneamente) | Evita sobreentrenamiento, ahorra costos de GPU |
| Orquestación de procesos | Orquesta automáticamente el pipeline CI/CD desde la recolección de datos → etiquetado → entrenamiento → prueba → liberación | Reduce ciclos de iteración de días a horas |
| Soluciones automatizadas | Genera estrategias de aumento de datos (por ejemplo, combinar fondos generados por reglas con objetivos recién generados o recolectados) | Preparación de datos sin intervención manual |
| Alertas de emergencia | Identifica nuevos patrones de ataque (por ejemplo, producción masiva de muestras adversarias) y activa actualizaciones de control de riesgo | Tiempo de respuesta < 5 minutos |
| Distribución de tareas | Asigna automáticamente muestras difíciles a equipos de etiquetado con guías de etiquetado generadas por LLM | Aumenta la eficiencia de etiquetado en un 40% |
Caso real: Cuando un cliente de comercio electrónico actualizó su algoritmo de detección de brechas en el CAPTCHA deslizante, los sistemas tradicionales requerían 3-5 días de adaptación manual. El sistema basado en LLM completó la detección de anomalías, el análisis de causa raíz, la generación de datos y el ajuste fino del modelo en 30 minutos, restaurando rápidamente la precisión de reconocimiento del 34% al 96,8%.
Etapa 4: Ejecución multimodal (Expansión del negocio)
El reconocimiento de CAPTCHA ya no es una tarea puramente visual, sino un proceso integral de toma de decisiones que integra visión, semántica y comportamiento. La expansión a nuevos tipos ya no tiene limitaciones de tiempo y costo.
| Tipo de CAPTCHA | Solución visual | Punto de mejora de LLM |
|---|---|---|
| CAPTCHA deslizante | Detección de brechas (YOLO) + comparación de imágenes + simulación de trayectoria | LLM analiza características de textura de brecha para generar trayectorias de deslizamiento humanas (evitando movimiento lineal a velocidad constante identificado como bots) |
| CAPTCHA de selección por clic | Detección de objetos + posicionamiento de coordenadas | LLM entiende instrucciones semánticas (por ejemplo, "Toque el elemento normalmente usado con el elemento mostrado"), realizando razonamiento contextual en escenarios ambigüos |
| CAPTCHA de rotación | Predicción de regresión de ángulo | LLM ayuda a juzgar estándares de alineación visual y manejar escenarios de ocultación parcial |
| ReCaptcha v3 | Análisis de biometría de comportamiento | LLM sintetiza trayectorias del mouse, intervalos de clics y patrones de desplazamiento de página para juzgar entre humano y bot |
AIops: El sistema inmunológico de sistemas autónomos
Sin un aseguramiento de O&M confiable, incluso la mejor cadena de decisiones no puede implementarse en producción. La capa AIops garantiza la estabilidad del sistema mediante cuatro capacidades principales:
1. Detección de anomalías
- Monitoreo de desviación de modelos: Comparación en tiempo real de la distribución de datos de entrada vs. la distribución del conjunto de entrenamiento (prueba de KS), alertando cuando la desviación exceda los umbrales.
- Seguimiento de decaimiento del rendimiento: Monitoreo de métricas tridimensionales de tasa de éxito, latencia de respuesta y utilización de GPU.
2. Reversión inteligente
Cuando una nueva versión de modelo funciona de manera anormal, el sistema no solo se revierte automáticamente a una versión estable, sino que también genera un informe de diagnóstico de fallos mediante análisis de LLM, señalando causas posibles (por ejemplo, "sobreexposición debido a alta proporción de imágenes nocturnas en nuevas muestras").
3. Programación de recursos elásticos
Escalabilidad automática basada en predicción de tráfico:
- Períodos pico (por ejemplo, Viernes Negro): Escalabilidad automática a 50 instancias de GPU.
- Períodos de baja demanda: Escalabilidad a 5 instancias, migrando datos fríos a almacenamiento de objetos.
- Ahorro de costos alcanza un 65% mientras se garantiza una disponibilidad del 99,99%.
4. Control de riesgos y defensa contra muestras adversarias
- Detección de muestras adversarias: Identificar imágenes de CAPTCHA con perturbaciones adversarias (ataques FGSM, PGD).
- Control de riesgos de comportamiento: Monitorear patrones de solicitud anómalos (por ejemplo, solicitudes de alta frecuencia desde una sola IP), activando automáticamente verificación humano-máquina o bloqueo de IP.
Ruta de implementación: De POC a producción
Las recomendaciones de implementación basadas en esta arquitectura se dividen en cuatro fases:
| Fase | Duración | Hitos clave | Métricas de éxito |
|---|---|---|---|
| Fase 1: Infraestructura | 1-2 meses | Construir base de monitoreo de AIops, lograr observabilidad integral | MTTR (Tiempo Medio de Reparación) < 15 minutos |
| Fase 2: Integración | 2-3 meses | Integrar LLM en análisis de errores, lograr informes de diagnóstico automatizados | Reducción del 70% en carga de trabajo de análisis manual |
| Fase 3: Automatización | 3-4 meses | Construir pipeline de entrenamiento totalmente automatizado (AutoML + LLM) | Ciclo de iteración de modelo < 4 horas |
| Fase 4: Autonomía | 6-12 meses | Lograr bucle de optimización autónoma impulsada por LLM | Frecuencia de intervención manual < 1 vez/semana |
Desafíos y estrategias de mitigación
Desafío 1: Decisiones incorrectas causadas por alucinaciones de LLM
Soluciones:
- Adoptar arquitectura RAG (Generación Aumentada por Recuperación), anclando las bases de decisión en una biblioteca de casos históricos reales.
- Establecer nodos de aprobación manual: Operaciones de alto riesgo como reversión de modelo o eliminación de datos requieren confirmación manual.
Desafío 2: Costos fuera de control
El costo de análisis de imágenes de GPT-4V es 50-100 veces mayor que el de modelos CV tradicionales.
Soluciones:
- Procesamiento por capas: Usar modelos CV ligeros (blip, clip, dino, etc.) para escenarios simples, enviando solo muestras difíciles a LLM.
- Gestión de presupuesto de tokens: Establecer tokens máximos por solicitud para evitar picos de costo debido a entradas anómalas.
Desafío 3: Escenarios sensibles a la latencia
El reconocimiento de CAPTCHA generalmente requiere una respuesta < 2 segundos.
Soluciones:
- Análisis asincrónico: Las sugerencias de optimización de LLM se generan mediante procesos asincrónicos, no bloqueando el camino de reconocimiento en tiempo real.
- Implementación en el borde: Implementar LLM ligeros (por ejemplo, Qwen3-8b, Llama-3-8B) en nodos de borde, con tiempo de procesamiento < 500ms.
Conclusión: Evolución de herramienta a socio
La arquitectura de CapSolver AI-LLM representa un cambio de paradigma en el campo de reconocimiento de CAPTCHA, pasando de herramientas estáticas a agentes dinámicos. Su valor no solo radica en mejorar la precisión de reconocimiento, sino en construir un ecosistema técnico autosuficiente:
- Respuesta más rápida: Plantillas generales logran adaptación en minutos.
- Personalización más profunda: Desarrollo tradicional soporta lógica de negocio compleja.
- Evolución continua: Bucles cerrados impulsados por LLM garantizan que el sistema se mantenga actualizado.
"Los sistemas de IA futuros no serán mantenidos por humanos, sino que serán socios digitales que colaboran con humanos y crecen de forma autónoma."
Con la continua evolución de modelos de gran escala multimodales (como GPT-4o, Gemini 1.5 Pro), tenemos razón para creer que el reconocimiento de CAPTCHA ya no será una confrontación técnica tediosa, sino un proceso de negociación automatizado eficiente, seguro y confiable entre sistemas de IA.
¡Pruebalo tú mismo! Usa el código
CAP26al registrarte en CapSolver para recibir créditos adicionales!
Preguntas frecuentes (FAQ)
Q1: ¿Aumenta la latencia de reconocimiento al agregar LLM?
A: Gracias al diseño de arquitectura en capas, la ruta de reconocimiento en tiempo real sigue siendo manejada por modelos CV optimizados (latencia < 200 ms). LLM es principalmente responsable del análisis de off-line y optimización de estrategias. Para escenarios complejos que requieren comprensión semántica, se pueden utilizar modelos LLM ligeros desplegados en el borde (latencia < 500 ms) o modos de procesamiento asíncrono.
Q2: ¿Cómo manejar decisiones incorrectas potenciales por parte de LLM?
A: Implementar un mecanismo de "Human-in-the-loop": las operaciones de alto riesgo (por ejemplo, reintegración completa del modelo, eliminación de la fuente de datos) requieren aprobación manual. Al mismo tiempo, establecer un entorno de prueba en sandbox donde todos los planes de optimización generados por LLM deban validarse mediante pruebas A/B antes del despliegue completo.
Q3: ¿Esta arquitectura es adecuada para equipos pequeños?
A: Sí. Se recomienda una implementación progresiva: inicialmente, usar solo APIs de LLM basadas en la nube (por ejemplo, Claude 3 Haiku) para análisis de anomalías sin construir grandes modelos; usar herramientas de código abierto (LangChain, MLflow) para construir pipelines. A medida que el negocio crezca, introducir gradualmente el despliegue privado y la automatización de AIops.
Q4: ¿Cómo se compara el costo con soluciones tradicionales de CV puro?
A: La inversión inicial aumenta en un 30-40% (principalmente por llamadas a la API de LLM y transformación de ingeniería), pero la reducción en costos de O&M manuales a través de automatización suele compensar la inversión adicional en 3-6 meses. A largo plazo, debido a la mayor eficiencia en la iteración de modelos y tasas de automatización más altas, el Costo Total de Propiedad (CTP) puede reducirse en más del 50%.
Aviso de Cumplimiento: La información proporcionada en este blog es solo para fines informativos. CapSolver se compromete a cumplir con todas las leyes y regulaciones aplicables. El uso de la red de CapSolver para actividades ilegales, fraudulentas o abusivas está estrictamente prohibido y será investigado. Nuestras soluciones para la resolución de captcha mejoran la experiencia del usuario mientras garantizan un 100% de cumplimiento al ayudar a resolver las dificultades de captcha durante el rastreo de datos públicos. Fomentamos el uso responsable de nuestros servicios. Para obtener más información, visite nuestros Términos de Servicio y Política de Privacidad.
Máse

Elevando la Automatización Empresarial: Infraestructura Potenciada por LLM para un Reconocimiento de CAPTCHA Sin Problemas & Eficiencia Operativa
Descubre cómo la infraestructura de automatización de IA impulsada por LLM revoluciona el reconocimiento de CAPTCHA, mejorando la eficiencia de los procesos de negocio y reduciendo la intervención manual. Optimiza tus operaciones automatizadas con soluciones avanzadas de verificación.
Adélia Cruz
30-Mar-2026

Recopilación de Datos a Gran Escala para el Entrenamiento de GML: Resolver CAPTCHAs a Gran Escala
Aprende a escalar la recopilación de datos para el entrenamiento de modelos de lenguaje grandes resolviendo CAPTCHAs a gran escala. Descubre estrategias automatizadas para construir conjuntos de datos de alta calidad para modelos de IA.

Sora Fujimoto
27-Mar-2026

Cómo resolver CAPTCHA en OpenBrowser usando CapSolver (Guía de automatización de Agente de IA)
Resolver CAPTCHA en OpenBrowser usando CapSolver. Automatizar reCAPTCHA, Turnstile y más para agentes de IA fácilmente.
Adélia Cruz
26-Mar-2026

Cómo resolver cualquier CAPTCHA en HyperBrowser usando CapSolver (Guía completa de configuración)
Resuelve cualquier CAPTCHA en HyperBrowser usando CapSolver. Automatiza reCAPTCHA, Turnstile, AWS WAF y más fácilmente.

Aloísio Vítor
26-Mar-2026

Resolver Captchas para Agentes de IA de monitoreo de precios: Una Guía Paso a Paso
Aprende a resolver eficazmente los CAPTCHAs para agentes de inteligencia artificial de monitoreo de precios con CapSolver. Este guía paso a paso garantiza la recopilación ininterrumpida de datos y una mayor visión del mercado.

Nikolai Smirnov
24-Mar-2026

Cómo resolver desafíos de CAPTCHA para agentes de inteligencia artificial: Extracción de datos con n8n, CapSolver y OpenClaw
Aprende a automatizar la resolución de CAPTCHA para agentes de inteligencia artificial usando n8n, CapSolver y OpenClaw. Construye una pipeline del lado del servidor para extraer datos de sitios web protegidos sin automatización del navegador ni pasos manuales.
Aloísio Vítor
20-Mar-2026