







Recopilación de Datos a Gran Escala para el Entrenamiento de GML: Resolver CAPTCHAs a Gran Escala

Sora Fujimoto
AI Solutions Architect
27-Mar-2026

TL;Dr:
- La calidad de los datos es rey: La recopilación de datos de alta calidad es la base del entrenamiento efectivo de modelos de lenguaje grandes (LLM).
- Barreras de CAPTCHA: Los sitios web modernos utilizan desafíos sofisticados que detienen la extracción automatizada de datos.
- La escalabilidad importa: La intervención manual es imposible al recopilar miles de millones de tokens para modelos de IA.
- Solución de CapSolver: Herramientas automatizadas proporcionan la velocidad y confiabilidad necesarias para la recopilación de datos a nivel empresarial.
- Eficiencia de costos: Externalizar la resolución de CAPTCHA reduce la carga de infraestructura y acelera los ciclos de desarrollo.
Introducción
Construir un modelo de lenguaje grande (LLM) competitivo requiere acceso a conjuntos de datos masivos, diversos y de alta calidad. La mayor parte de esta información reside en la web abierta, protegida por varias capas de seguridad. La recopilación de datos a esta escala presenta desafíos técnicos únicos que los métodos tradicionales de raspado no pueden superar. Los desarrolladores suelen encontrar que sus sistemas automatizados son bloqueados por complejos acertijos de verificación. Estas barreras existen para proteger la integridad del sitio, pero también obstaculizan a investigadores legítimos y desarrolladores de IA. Este artículo explora cómo escalar la recopilación de datos para el entrenamiento de LLM abordando el desafío persistente de resolver CAPTCHA a gran escala. Examinaremos la intersección entre la automatización web y la infraestructura de aprendizaje automático. Los lectores aprenderán a integrar CapSolver para mantener un flujo constante de datos de entrenamiento sin cuellos de botella manuales.
El papel de los datos web en el entrenamiento de LLM
Los modelos de lenguaje grande prosperan con la amplitud de la información disponible en Internet. Desde revistas científicas hasta discusiones en foros, cada pieza de texto contribuye a las capacidades de razonamiento del modelo. Sin embargo, el proceso de recopilar estos datos se está volviendo cada vez más difícil. Muchas fuentes de alto valor implementan límites estrictos de tasa y verificaciones. Estas medidas están diseñadas para distinguir entre usuarios humanos y scripts automatizados. Para los equipos de IA, estas verificaciones representan un punto de fricción significativo en su cadena de datos.
El volumen de datos requerido para modelos modernos es abrumador. Por ejemplo, modelos como GPT-4 se entrenan en trillones de tokens. Recopilar esta cantidad de información requiere una infraestructura de raspado altamente distribuida y resistente. Cuando un raspador encuentra un acertijo de verificación, todo el proceso puede detenerse. Este retraso no es solo una molestia menor; puede llevar a conjuntos de datos obsoletos y aumentar los costos operativos. Garantizar un flujo continuo de recopilación de datos es esencial para mantener la ventaja competitiva de un producto de IA.
Desafíos comunes en la extracción de datos a gran escala
Escalar los esfuerzos de recopilación de datos implica más que simplemente agregar más servidores. Debes navegar por un paisaje de protocolos de seguridad en evolución. La mayoría de los sitios web ahora utilizan análisis de comportamiento para detectar automatización. Cuando un script se comporta de manera predecible, se activa un CAPTCHA. Estos desafíos han evolucionado desde la simple reconocimiento de texto a tareas de clasificación de imágenes y resolución de acertijos complejos.
| Categoría de desafío | Impacto en la recopilación de datos | Estrategia de mitigación |
|---|---|---|
| Limitación de tasa de IP | Bloquea las solicitudes de centros de datos específicos. | Uso de proxies residenciales y rotación. |
| Contenido dinámico | El contenido solo se carga después de la ejecución de JavaScript. | Navegadores sin cabeza como Playwright o Puppeteer. |
| Acertijos de verificación | Detiene los flujos automatizados hasta que se resuelven. | Integración de solucionadores automatizados de CAPTCHA. |
| Fingerprinting | Identifica a los raspadores basándose en encabezados del navegador. | Aleatorización de encabezados y complementos de stealth. |
Muchos desarrolladores intentan construir sus propios solucionadores utilizando modelos de aprendizaje automático básicos. Aunque esto podría funcionar para acertijos simples, falla frente a sistemas de seguridad modernos impulsados por IA. Mantener un solucionador interno requiere actualizaciones constantes y un equipo dedicado de investigadores. Esto desvía la atención de la tarea principal de entrenamiento y refinamiento de LLM.
Por qué resolver CAPTCHA a gran escala es crítico
En el contexto del desarrollo de LLM, el tiempo es un recurso crítico. Cada hora dedicada a arreglar un raspador roto es una hora perdida en el ciclo de entrenamiento. La recopilación automatizada de datos debe ser lo suficientemente robusta como para manejar miles de solicitudes por segundo. Si tu sistema no puede manejar los desafíos de verificación automáticamente, tu potencial de escalabilidad está limitado por la intervención humana.
Los agentes de IA modernos y los raspadores necesitan una forma confiable de navegar estos obstáculos. Es aquí donde los servicios especializados se vuelven indispensables. Al utilizar un enfoque basado en API, los desarrolladores pueden transferir la complejidad de resolver CAPTCHA. Esto permite que la lógica de raspado permanezca simple y centrada en la extracción de datos. Para quienes estén interesados en la implementación técnica, entender por qué la automatización web sigue fallando en CAPTCHA es el primer paso hacia la construcción de un sistema más resiliente.
Integrar CapSolver en tu pipeline de datos de IA
CapSolver proporciona una API robusta que se integra directamente en marcos de automatización existentes. Ya sea que estés usando Python, Node.js o Go, el proceso de integración es sencillo. El servicio admite una amplia gama de desafíos, incluyendo reCAPTCHA y versiones especializadas para empresas. Esta versatilidad es vital para equipos que realizan la recopilación de datos desde fuentes globales diversas.
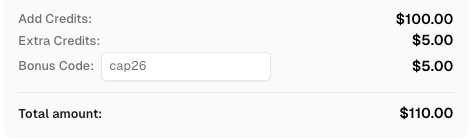
Usa el código
CAP26al registrarte en CapSolver para recibir créditos adicionales!
Cuando un raspador encuentra un desafío, envía la clave del sitio y la URL a la API de CapSolver. El servicio devuelve el token de solución, que el raspador envía al sitio web. Este proceso completo ocurre en segundos, asegurando que el flujo de datos permanezca ininterrumpido. Este nivel de automatización es lo que permite la creación de conjuntos de datos de alta calidad para el aprendizaje automático a escala industrial.
Resumen comparativo: Desarrollo interno vs. CapSolver
Elegir entre construir una solución personalizada y usar un servicio profesional es un dilema común para startups de IA. La siguiente tabla resume las diferencias clave.
| Característica | Desarrollo interno | API de CapSolver |
|---|---|---|
| Costo inicial | Alto (horas de ingeniería) | Bajo (pago por uso) |
| Mantenimiento | Se requieren actualizaciones constantes | Manejado por el proveedor |
| Tasa de éxito | Variable y a menudo baja | Alta (99,9% de disponibilidad) |
| Escalabilidad | Limitada por hardware local | Virtualmente ilimitada |
| Enfoque | Distrae de la investigación de IA | Facilita el desarrollo principal |
Para la mayoría de las organizaciones, el costo total de propiedad de un solucionador interno es significativamente más alto. Los costos ocultos de mantenimiento y datos perdidos suelen superar las tarifas de suscripción de un servicio especializado.
Implementación técnica para agentes de IA
Los agentes de IA modernos, como los construidos en LangChain o AutoGPT, a menudo necesitan navegar por la web para encontrar información en tiempo real. Estos agentes son particularmente propensos a ser bloqueados porque sus patrones de navegación son distintos. Integrar un solucionador en el conjunto de herramientas de un agente le permite completar tareas que de otro modo serían imposibles.
Por ejemplo, un agente encargado de recopilar los últimos artículos de investigación podría encontrar una pared de verificación en una biblioteca digital. Con un solucionador automatizado, el agente puede manejar la resolución de CAPTCHA y continuar su búsqueda. Esta capacidad es esencial para crear sistemas verdaderamente autónomos. Los desarrolladores pueden explorar más sobre CAPTCHA de IA para empresas de LLM para ver cómo estas tecnologías se complementan en entornos profesionales.
Calidad de los datos y filtrado después de la recopilación
Resolver el CAPTCHA es solo la primera parte del viaje. Una vez que los datos se recopilan, deben limpiarse y filtrarse. Los datos brutos de la web a menudo contienen ruido, como anuncios, menús de navegación y contenido duplicado. Para el entrenamiento de LLM, este ruido puede degradar el rendimiento del modelo.
Los equipos de IA utilizan diversas técnicas para garantizar la calidad de los datos. Esto incluye el uso de modelos más pequeños para puntuar la relevancia del texto o aplicar filtros heurísticos para eliminar fragmentos de baja calidad. El objetivo es crear un conjunto de datos que sea tanto masivo como limpio. La sinergia entre una recopilación eficiente de datos y un filtrado riguroso es lo que produce modelos de IA de alta calidad. Puedes encontrar más consejos prácticos en la guía sobre prácticas de IA y LLM.
Consideraciones éticas en la recopilación automatizada de datos
Aunque la capacidad técnica para recopilar datos es vasta, debe equilibrarse con consideraciones éticas. Respetar los archivos robots.txt y no sobrecargar sitios web pequeños son prácticas estándar. Los desarrolladores de IA deben esforzarse por ser buenos ciudadanos de la web. Esto incluye proporcionar cadenas de user-agent claras y cumplir con regulaciones de privacidad de datos como el RGPD.
Usar herramientas automatizadas para resolver CAPTCHA debe hacerse de manera responsable. El objetivo es facilitar la creación de tecnologías de IA beneficiosas mientras se minimiza el impacto en los sitios web objetivo. Muchos investigadores argumentan que el beneficio público de los modelos de LLM avanzados justifica la recopilación a gran escala de datos disponibles públicamente. Este debate continúa evolucionando a medida que la tecnología madura.
Tendencias futuras en la recopilación de datos para IA
El panorama de la recopilación de datos está cambiando hacia sistemas más inteligentes y adaptables. Estamos viendo el auge de la recopilación de datos multimodales, donde los modelos se entrenan con una mezcla de texto, imágenes y video. Esto aumenta la complejidad de la tarea de raspado, ya que diferentes tipos de contenido requieren estrategias de manejo distintas.
Además, a medida que los sitios web se vuelven mejores en detectar IA, las herramientas utilizadas para recopilar datos deben volverse más sofisticadas. El "juego del gato y el ratón" entre los sistemas de seguridad y las herramientas de automatización probablemente continuará. Los servicios que se mantengan al día con estas tendencias permanecerán esenciales para la industria de IA. Para una mirada más profunda al futuro, considera leer sobre la solución del futuro de IA-LLM y cómo impacta en el ecosistema más amplio.
Para mantener una ventaja competitiva, las organizaciones deben enfocarse en optimizar la infraestructura de IA a gran escala. Esto incluye asegurar que cada componente de la cadena de datos, desde la gestión de proxies hasta resolver CAPTCHA, sea lo más eficiente posible. Al aprovechar herramientas especializadas, los equipos pueden construir repositorios de datos web a gran escala que sirvan como base para futuros avances. Como se mencionó en discusiones recientes sobre escalar el almacenamiento para el entrenamiento y la inferencia de IA, la capacidad de manejar transferencias masivas de datos es tan importante como la potencia de cálculo en sí misma.
Conclusión
Escalando la recopilación de datos para el entrenamiento de LLM es un desafío fundamental para la próxima generación de IA. Al automatizar el proceso de resolver CAPTCHA a gran escala, los desarrolladores pueden garantizar que sus modelos tengan acceso a la vasta riqueza de información en Internet. CapSolver ofrece una solución confiable, de bajo costo y escalable que se integra en cualquier pipeline de datos moderno. Esto permite a los equipos de IA enfocarse en lo que hacen mejor: construir sistemas inteligentes que cambien el mundo. No dejes que los acertijos de verificación ralenticen tu innovación. Comienza a usar CapSolver hoy para optimizar tu adquisición de datos y acelerar el entrenamiento de tu modelo.
Preguntas frecuentes
1. ¿Por qué es necesario resolver CAPTCHA de forma automática para el entrenamiento de LLM?
El entrenamiento de LLM requiere trillones de puntos de datos. La intervención manual para cada acertijo de verificación haría imposible recopilar datos a la velocidad y escala necesarias.
2. ¿Afecta la calidad de los datos recopilados el uso de un solucionador?
No, el solucionador solo maneja la barrera de verificación. La calidad de los datos depende de la lógica de raspado y de los procesos de filtrado posteriores que apliques al texto bruto.
3. ¿Es difícil integrar CapSolver en un raspador de Python existente?
La integración es muy sencilla. CapSolver proporciona una API bien documentada y SDKs que permiten agregar capacidades de resolución de acertijos con solo unas pocas líneas de código.
4. ¿CapSolver puede manejar las últimas versiones de reCAPTCHA?
Sí, el servicio se actualiza constantemente para soportar las versiones más nuevas y complejas de todos los sistemas de verificación principales utilizados por sitios web de alto tráfico.
5. ¿Cuáles son los principales beneficios de usar una API en lugar de construir un solucionador personalizado?
Los principales beneficios incluyen una mayor tasa de éxito, ningún costo de mantenimiento, escalabilidad instantánea y un costo total significativamente menor en comparación con contratar un equipo de ingeniería dedicado.
Aviso de Cumplimiento: La información proporcionada en este blog es solo para fines informativos. CapSolver se compromete a cumplir con todas las leyes y regulaciones aplicables. El uso de la red de CapSolver para actividades ilegales, fraudulentas o abusivas está estrictamente prohibido y será investigado. Nuestras soluciones para la resolución de captcha mejoran la experiencia del usuario mientras garantizan un 100% de cumplimiento al ayudar a resolver las dificultades de captcha durante el rastreo de datos públicos. Fomentamos el uso responsable de nuestros servicios. Para obtener más información, visite nuestros Términos de Servicio y Política de Privacidad.
Máse

Elevando la Automatización Empresarial: Infraestructura Potenciada por LLM para un Reconocimiento de CAPTCHA Sin Problemas & Eficiencia Operativa
Descubre cómo la infraestructura de automatización de IA impulsada por LLM revoluciona el reconocimiento de CAPTCHA, mejorando la eficiencia de los procesos de negocio y reduciendo la intervención manual. Optimiza tus operaciones automatizadas con soluciones avanzadas de verificación.

Adélia Cruz
30-Mar-2026

Recopilación de Datos a Gran Escala para el Entrenamiento de GML: Resolver CAPTCHAs a Gran Escala
Aprende a escalar la recopilación de datos para el entrenamiento de modelos de lenguaje grandes resolviendo CAPTCHAs a gran escala. Descubre estrategias automatizadas para construir conjuntos de datos de alta calidad para modelos de IA.
Sora Fujimoto
27-Mar-2026

Cómo resolver CAPTCHA en OpenBrowser usando CapSolver (Guía de automatización de Agente de IA)
Resolver CAPTCHA en OpenBrowser usando CapSolver. Automatizar reCAPTCHA, Turnstile y más para agentes de IA fácilmente.
Adélia Cruz
26-Mar-2026

Cómo resolver cualquier CAPTCHA en HyperBrowser usando CapSolver (Guía completa de configuración)
Resuelve cualquier CAPTCHA en HyperBrowser usando CapSolver. Automatiza reCAPTCHA, Turnstile, AWS WAF y más fácilmente.

Aloísio Vítor
26-Mar-2026

Resolver Captchas para Agentes de IA de monitoreo de precios: Una Guía Paso a Paso
Aprende a resolver eficazmente los CAPTCHAs para agentes de inteligencia artificial de monitoreo de precios con CapSolver. Este guía paso a paso garantiza la recopilación ininterrumpida de datos y una mayor visión del mercado.

Nikolai Smirnov
24-Mar-2026

Cómo resolver desafíos de CAPTCHA para agentes de inteligencia artificial: Extracción de datos con n8n, CapSolver y OpenClaw
Aprende a automatizar la resolución de CAPTCHA para agentes de inteligencia artificial usando n8n, CapSolver y OpenClaw. Construye una pipeline del lado del servidor para extraer datos de sitios web protegidos sin automatización del navegador ni pasos manuales.
Aloísio Vítor
20-Mar-2026