







कैपसॉल्वर कृत्रिम बुद्धिमता-एलएलएम वास्तुकला के अभ्यास में: अनुकूलित CAPTCHA पहचान प्रणाली के लिए निर्णय पाइपलाइन निर्माण

Rajinder Singh
Deep Learning Researcher
10-Feb-2026

CAPTCHA अब अधिक विविध और जटिल हो गए हैं - सरल पाठ चुनौतियों से लेकर अंतरक्रियात्मक पहेलियों और डायनामिक जोखिम-आधारित तार्किक तक, और आज के ऑटोमेशन वर्कफ़्लो में बुनियादी छवि अनुकरण से अधिक आवश्यकता होती है। पारंपरिक OCR और अकेले CNN मॉडल बदलते रूपों और मिश्रित दृश्य-अर्थविज्ञान कार्यों के साथ पीछे रह गए हैं।
हमारे पिछले लेख, "AI-LLM: जोखिम नियंत्रण छवि अनुकरण और CAPTCHA हल करने के लिए भविष्य का समाधान,” में हमने यह अन्वेषण किया कि बड़े भाषा मॉडल क्यों आधुनिक CAPTCHA प्रणालियों में एक महत्वपूर्ण घटक बन रहे हैं। इस लेख में हम उस पर आधारित हैं और CapSolver के AI-LLM निर्णय पाइपलाइन के व्यावहारिक आर्किटेक्चर की जांच करते हैं: विभिन्न CAPTCHA प्रकार कैसे सही हल की रणनीति में राउंड करते हैं और जब नए रूप उत्पन्न होते हैं तो प्रणाली कैसे अनुकूलित होती है।
मुख्य चुनौती केवल पिक्सेल की पहचान करना नहीं है, बल्कि CAPTCHA के पीछे के इरादे को समझना और वास्तविक समय में अनुकूलित करना है। कैपसॉल्वर एआई-एलएलएम आर्किटेक्चर कंप्यूटर विजन के साथ उच्च-स्तरीय तार्किक विचार को मिलाता है ताकि केवल पैटर्न मैचिंग के बजाय रणनीतिक निर्णय लिए जा सकें।
यहां उस आर्किटेक्चर का एक अवलोकन है:
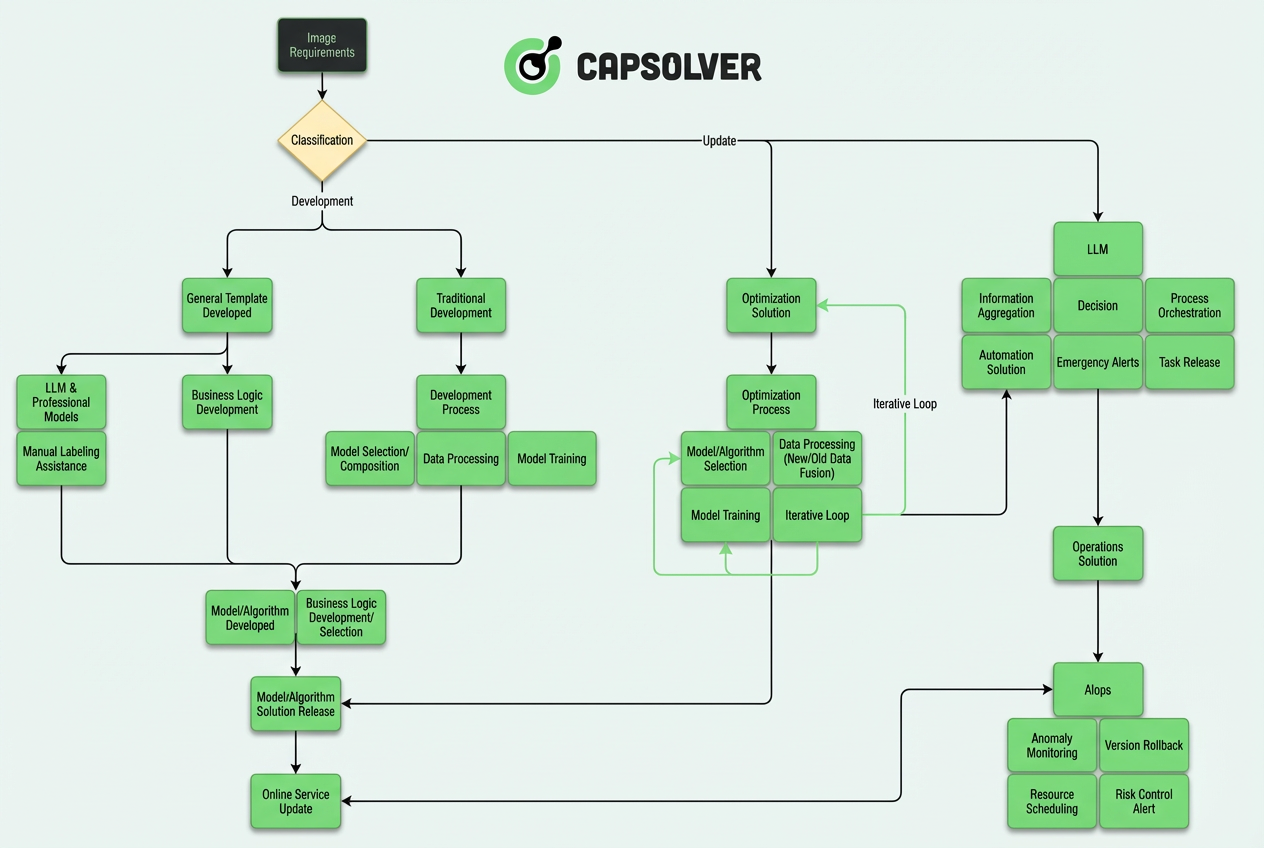
इस लेख में हम अपने तीन-स्तरीय स्वायत्त प्रणाली के इंजीनियरिंग के बारे में डूब जाते हैं, जो क्रमशः कच्चे दृश्य इनपुट और अर्थविज्ञान तर्क के बीच एक पुल के रूप में कार्य करता है।
according to industry research, by 2026 more than 80% of enterprises will have deployed generative AI‑enabled applications in production environments — highlighting the rapid shift toward automated, AI‑driven workflows and multimodal pipelines.
कोर आर्किटेक्चर: तीन-स्तरीय स्वायत्त प्रणाली
इंजीनियरिंग अभ्यास के आधार पर, आधुनिक CAPTCHA अनुकरण प्रणालियां "मॉडल + नियम" एकल आर्किटेक्चर से जटिल परत आधारित स्वायत्त प्रणाली में विकसित हुई हैं। पूरा आर्किटेक्चर तीन मुख्य परतों में विभाजित किया जा सकता है:
| परत | कोर मॉड्यूल | कार्यात्मक स्थिति | टेक स्टैक उदाहरण |
|---|---|---|---|
| एप्लिकेशन निर्णय स्तर | LLM ब्रेन | अर्थविज्ञान समझ, कार्य ऑर्केस्ट्रेशन, असामान्य विश्लेषण | GPT-4/Vision, Claude 3, Qwen3, स्वयं विकसित LangChain एजेंट्स |
| एल्गोरिथ्म निष्पादन स्तर | CV इंजन | वस्तु डिटेक्शन, ट्रेजेक्टरी सिमुलेशन, छवि अनुकरण | YOLO, ViT, blip, clip, dino |
| ओएम गारंटी स्तर | AIops | मॉनिटरिंग, रोलबैक, संसाधन योजना, जोखिम नियंत्रण | Prometheus, Kubernetes, कस्टम RL रणनीतियां |
इस परत आधारित डिज़ाइन का मुख्य विचार: LLM "सोचने" के लिए जिम्मेदार है, CV मॉडल "निष्पादन" के लिए जिम्मेदार है, और AIops "गारंटी" के लिए जिम्मेदार है।
LLM हस्तक्षेप की आवश्यकता क्यों है?
पारंपरिक CAPTCHA अनुकरण तीन महान बाधाओं का सामना करता है:
- अर्थविज्ञान अंतर: "कृपया एक्सएक्स के साथ छवियों के सभी चयन करें" या "दिखाई देने वाली वस्तु के साथ आमतौर पर उपयोग की जाने वाली वस्तु को छूएं" जैसे निर्देशात्मक पाठ की समझ नहीं कर सकता है, और ऐसे प्रश्नों की विविधता बढ़ रही है।
- अनुकूलन देरी: जब लक्ष्य वेबसाइट नियंत्रण तार्किक के अपडेट करती है, तो हस्तचालित पुनर्चिह्नीकरण और प्रशिक्षण की आवश्यकता होती है (कई दिनों तक चलने वाले चक्र)।
- कठोर असामान्य नियंत्रण: नए रक्षा मोड (जैसे, विरोधी नमूने) के सामने, समान प्रकार अक्सर संस्करण बदलते हैं, और कुछ यहां तक कि कम पास दर वाले प्रकारों की संभावना बढ़ा देते हैं। पुराने इंजन के पास ऐसे जोखिम नियंत्रण के लिए स्वायत्त विश्लेषण क्षमता नहीं है।
नोट: LLM CV मॉडल को बदल नहीं देता है, बल्कि CV प्रणाली के "न्यूरल सेंटर" बन जाता है, जिससे इसे समझने और विकसित होने की क्षमता मिलती है।
निर्णय पाइपलाइन का कार्य योजना
पूरी प्रणाली अंतर्निहित प्रतिबिंब-निर्णय-निष्पादन-विकास के बंद चक्र का अनुसरण करती है, जिसे चार महत्वपूर्ण चरणों में विभाजित किया जा सकता है:
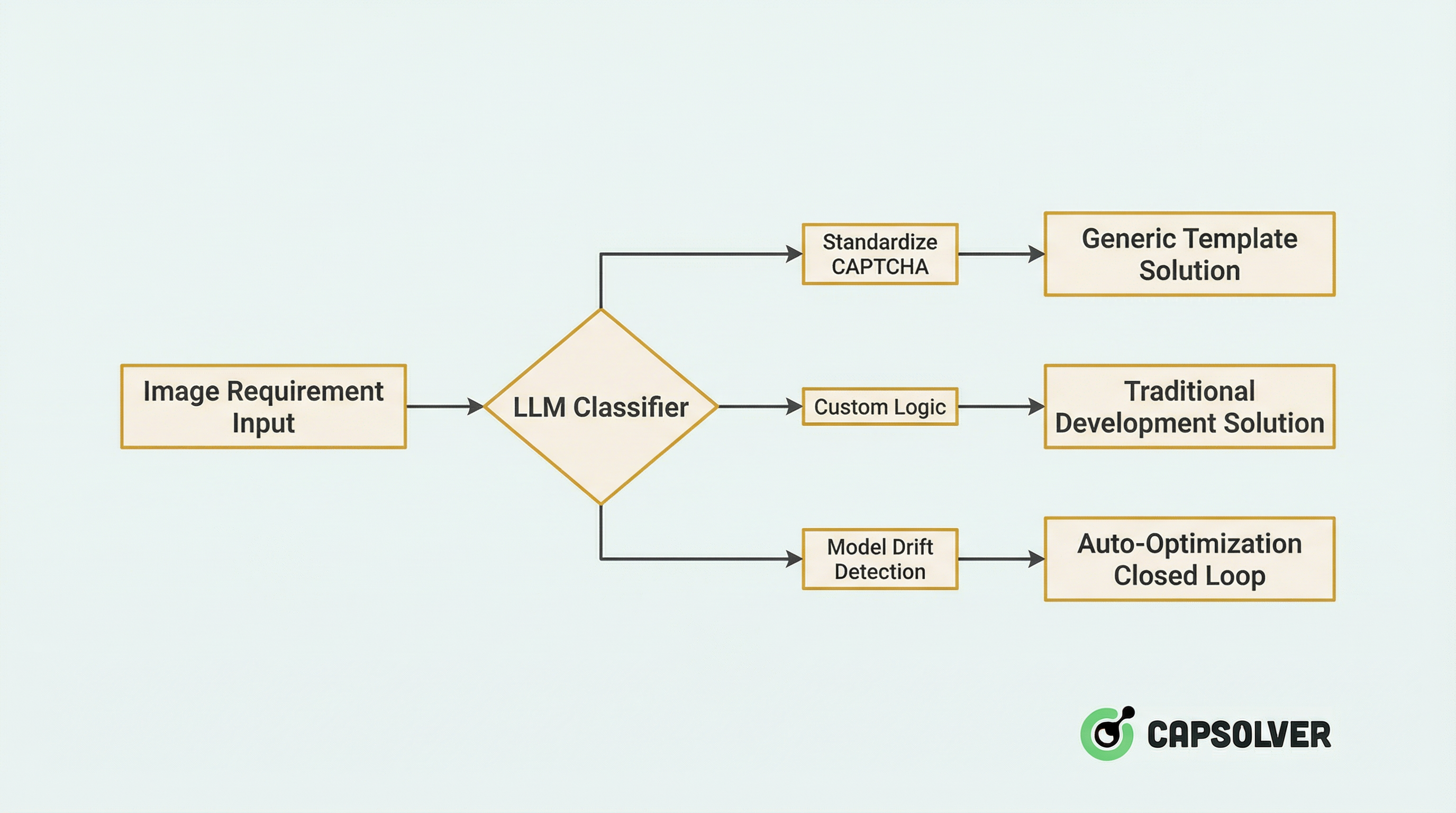
चरण 1: बुद्धिमान रूटिंग
जब एक नई छवि मांग प्रणाली में प्रवेश करती है, तो यह पहले LLM-चालित वर्गीकरण के माध्यम से बुद्धिमान रूटिंग के माध्यम से गुजरती है:
तकनीकी विवरण:
- जीरो-शॉट वर्गीकरण: LLM के दृश्य समझ क्षमता का उपयोग करके CAPTCHA प्रकार (स्लाइडर, क्लिक-सेलेक्ट, घूर्णन, ReCaptcha आदि) की पहचान करें बिना प्रशिक्षण के।
- आत्मविश्वास मूल्यांकन: जब LLM आत्मविश्वास 0.8 से कम होता है, तो यह स्वचालित रूप से हस्तचालित समीक्षा प्रक्रिया को चालू कर देता है और नमूना आउटक्रम प्रशिक्षण सेट में शामिल कर देता है।
व्यावहारिक डेटा: प्लेटफॉर्म ने इस रूटिंग प्रणाली के साथ एकीकरण के बाद, संसाधन आवंटन दक्षता 47% बढ़ गई, और गलत वर्गीकरण दर 12% से घटकर 2.1% हो गई।
चरण 2: डुअल-ट्रैक विकास
वर्गीकरण परिणामों के आधार पर, प्रणाली दो अलग-अलग तकनीकी ट्रैक में प्रवेश करती है:
ट्रैक A: लो-कोड ट्रैक (सामान्य टेम्पलेट के माध्यम से तेज उत्तर)
मानक CAPTCHA के लिए लागू होता है जैसे reCAPTCHA:
सामान्य टेम्पलेट लाइब्रेरी
language
├── LLM पूर्व-लेबलिंग: स्वचालित बाउंडिंग बॉक्स और सामान्य लेबल बनाएं
├── पूर्व-प्रशिक्षित मॉडल: मिलियन सैंपल पर प्रशिक्षित सामान्य डिटेक्टर
└── LLM पोस्ट-प्रोसेसिंग: सामान्य सुधार (उदाहरण के लिए, 0/O, 1/l के बीच अंतर करना, डुप्लिकेट हटाना)महत्वपूर्ण नवाचार — बुद्धिमान लेबलिंग फ्लाईव्हील:
- LLM कम-शॉट शिक्षा के माध्यम से पिरोस-लेबल उत्पन्न करता है।
- हस्तचालित समीक्षा द्वारा उच्च गुणवत्ता वाले डेटा ट्रेनिंग सेट में वापस आता है।
- लेबलिंग लागत में 60% कमी आई, जबकि डेटा विविधता 3 गुना बढ़ गई।
ट्रैक B: प्रो-कोड ट्रैक (गहरा विशिष्ट विकास)
कंपनी स्तर के विशिष्ट CAPTCHA के लिए लक्षित (उदाहरण के लिए, विशिष्ट स्लाइडर एल्गोरिदम, घूर्णन कोण तार्किक):
पारंपरिक विकास पाइपलाइन
language
├── मॉडल चयन/संयोजन (डिटेक्शन + रिकग्निशन + निर्णय)
├── डेटा प्रसंस्करण: साफ करना → लेबलिंग → विरोधी नमूना जनरेशन (LLM-सहायता: सटीकता परीक्षण और नए डेटा फ़िल्टरिंग)
└── लगातार ट्रेनिंग: अनुक्रमिक शिक्षा और क्षेत्र अनुकूलन का समर्थन करता हैLLM की डेटा जनरेशन में भूमिका:
- छवि जनरेशन: डिफ्यूजन मॉडल
अक्सर पूछे जाने वाले प्रश्न (FAQ)
Q1: LLM जोड़ने से पहचान देरी बढ़ती है?
A: परतदार वास्तुकला डिज़ाइन के माध्यम से, वास्तविक समय पहचान मार्ग अभी भी अनुकूलित CV मॉडल द्वारा संभाला जाता है (देरी < 200ms)। LLM मुख्य रूप से ऑफलाइन विश्लेषण और रणनीति अनुकूलन के लिए जिम्मेदार है। जटिल परिस्थितियों में अर्थग्रहण की आवश्यकता होती है, किन्तु किन्हीं हल्के LLM का उपयोग किया जा सकता है जो किनारे पर स्थापित हैं (देरी < 500ms) या असिंक्रोनस प्रक्रिया के मोड का उपयोग किया जा सकता है।
Q2: LLM द्वारा संभावित गलत निर्णय कैसे संभालें?
A: एक मानव-संलग्न तंत्र के अनुमोदन के साथ: उच्च जोखिम वाले कार्य (उदाहरण के लिए, पूर्ण मॉडल वापसी, डेटा स्रोत हटाना) के लिए हस्तचालित अनुमोदन आवश्यक है। साथ ही, सभी LLM द्वारा उत्पादित अनुकूलन योजनाओं को पूर्ण डेप्लॉयमेंट से पहले A/B परीक्षण के माध्यम से परीक्षण करने वाले सैंडबॉक्स परीक्षण परिवेश की स्थापना करें।
Q3: क्या यह वास्तुकला छोटी टीमों के लिए उपयुक्त है?
A: हां। क्रमिक कार्यान्वयन की सिफारिश की जाती है: शुरू में, बादल-आधारित LLM एपीआई (उदाहरण के लिए, क्लॉड 3 हाइकू) का उपयोग करके असामान्य विश्लेषण के लिए बिना बड़े मॉडल बनाए। ओपन-सोर्स टूल्स (लैंगचेन, MLflow) का उपयोग पाइपलाइन बनाने के लिए करें। जैसे-जैसे व्यावसायिक विकास होता है, धीरे-धीरे निजी डेप्लॉयमेंट और AIops स्वचालन के आगे बढ़ें।
Q4: इसकी लागत पारंपरिक शुद्ध CV समाधानों के साथ कैसे तुलना करती है?
A: प्रारंभिक निवेश लगभग 30-40% बढ़ जाता है (मुख्य रूप से LLM एपीआई कॉल और इंजीनियरिंग परिवर्तन के लिए), लेकिन स्वचालन के माध्यम से हस्तचालित O&M लागत में कमी आमतौर पर 3-6 महीने में अतिरिक्त निवेश को बराबर कर देती है। लंबे समय में, मॉडल अपडेट की दक्षता में सुधार और अधिक स्वचालन दर के कारण, कुल स्वामित्व लागत (TCO) 50% से अधिक कम हो सकती है।
अनुपालन अस्वीकरण: इस ब्लॉग पर प्रदान की गई जानकारी केवल सूचनात्मक उद्देश्यों के लिए है। CapSolver सभी लागू कानूनों और विनियमों का पालन करने के लिए प्रतिबद्ध है। CapSolver नेटवर्क का उपयोग अवैध, धोखाधड़ी या दुरुपयोग करने वाली गतिविधियों के लिए करना सख्त वर्जित है और इसकी जांच की जाएगी। हमारे कैप्चा समाधान उपयोगकर्ता अनुभव को बेहतर बनाने के साथ-साथ सार्वजनिक डेटा क्रॉलिंग के दौरान कैप्चा कठिनाइयों को हल करने में 100% अनुपालन सुनिश्चित करते हैं। हम अपनी सेवाओं के जिम्मेदार उपयोग की प्रोत्साहना करते हैं। अधिक जानकारी के लिए, कृपया हमारी सेवा की शर्तें और गोपनीयता नीति पर जाएं।
अधिक

कॉर्पोरेट स्वचालन को उन्नत करते हुए: LLM-संचालित बुनियादी ढांचा सीमाहीन CAPTCHA पहचान एवं संचालन की कार्यक्षमता
जानें कि LLM-संचालित कृत्रिम बुद्धिमत्ता ऑटोमेशन इंफ्रास्ट्रक्चर CAPTCHA पहचान को बदल देता है, व्यवसाय प्रक्रिया की कार्यक्षमता में सुधार करता है और मैनुअल हस्तक्षेप कम करता है। उन्नत सत्यापन समाधानों के साथ अपने स्वचालित संचालन को अधिकतम करें।
Rajinder Singh
30-Mar-2026

LLM ट्रेनिंग के लिए डेटा संग्रह के पैमाने को बढ़ाना: CAPTCHAs को पैमाने पर हल करना
LLM प्रशिक्षण के लिए पैमाने पर डेटा संग्रह कैसे करें, जैसे कि CAPTCHAs को हल करके। AI मॉडल के लिए उच्च गुणवत्ता वाले डेटासेट बनाने के लिए स्वचालित रणनीतियाँ खोजें।

Emma Foster
27-Mar-2026

CAPTCHA कैसे हल करें OpenBrowser में CapSolver का उपयोग करके (AI एजेंट स्वचालन गाइड)
OpenBrowser में CapSolver के माध्यम से CAPTCHA हल करें। AI एजेंट के लिए reCAPTCHA, Turnstile आदि को स्वचालित करें आसानी से।
Rajinder Singh
26-Mar-2026

कैसे कोई भी CAPTCHA हल करें HyperBrowser में CapSolver का उपयोग करके (पूर्ण सेटअप गाइड)
हाइपरब्राउज़र में कैपसॉल्वर के उपयोग से कोई भी CAPTCHA हल करें। reCAPTCHA, Turnstile, AWS WAF आदि को स्वचालित करें और अधिक आसानी से।
Rajinder Singh
26-Mar-2026

वेबएमसीपी विरुद्ध एमसीपी: एआई एजेंट्स के लिए अंतर क्या है?
AI एजेंट्स के लिए WebMCP और MCP के मुख्य अंतरों का अन्वेषण करें, वेब ऑटोमेशन और संरचित डेटा अंतःक्रिया में उनकी भूमिकाओं को समझें। ये प्रोटोकॉल AI एजेंट क्षमताओं के भविष्य को कैसे आकार देते हैं, इसके बारे में सीखें।
Rajinder Singh
13-Mar-2026

कैप्चा हल करने का तरीका ओपनक्लॉ में – चरण-दर-चरण गाइड कैपसॉल्वर एक्सटेंशन के साथ
OpenClaw में CAPTCHA हल करने का तरीका सीखें, सुचारू AI ब्राउजर ऑटोमेशन के लिए CapSolver क्रोम एक्सटेंशन का उपयोग करें।
Rajinder Singh
06-Mar-2026