







AI स्क्रैपर के वैकल्पिक विकल्प भरोसेमंद वेब डेटा स्वचालन के लिए

Rajinder Singh
Deep Learning Researcher
27-May-2026
TL;DR
- AI स्क्रैपर विकल्पों की तुलना इस्पर्शन सटीकता, ब्राउजर नियंत्रण, API कवरेज, सुसंगतता नियंत्रण और चुनौती निपटान के बजाय इंटरफेस के आधार पर नहीं की जानी चाहिए।
- सबसे मजबूत वर्कफ़्लो आमतौर पर AI निष्कर्षण परत के साथ निश्चित रूप से ब्राउजर ऑटोमेशन, आधिकारिक API, मॉनिटरिंग और अनुमोदित लक्ष्यों के लिए नियंत्रित CAPTCHA हल करने के मार्ग के साथ जुड़ा होता है।
- ब्राउजर ऑटोमेशन डायनामिक पृष्ठों के लिए उपयोगी है, लेकिन डेटा एकत्र करने से पहले टीमों को दर सीमा, robots.txt समीक्षा, अनुमति जांच और स्पष्ट बंद की स्थिति की आवश्यकता होती है।
- CAPTCHA चुनौतियां कुछ अनुमोदित वेब स्क्रैपिंग वर्कफ़्लो में विश्वसनीयता की जांच होती हैं, और CapSolver आधिकारिक API और ब्राउजर-एक्सटेंशन मार्गों के माध्यम से टीमों की सहायता कर सकता है।
- टीमें ऐसे उपकरण चुनें जो एडिट लॉग बनाए रखते हैं, रखरखाव कार्य कम करते हैं और इंजीनियरों और ऑपरेटरों के लिए जिम्मेदार उपयोग को आसान बनाते हैं।
परिचय
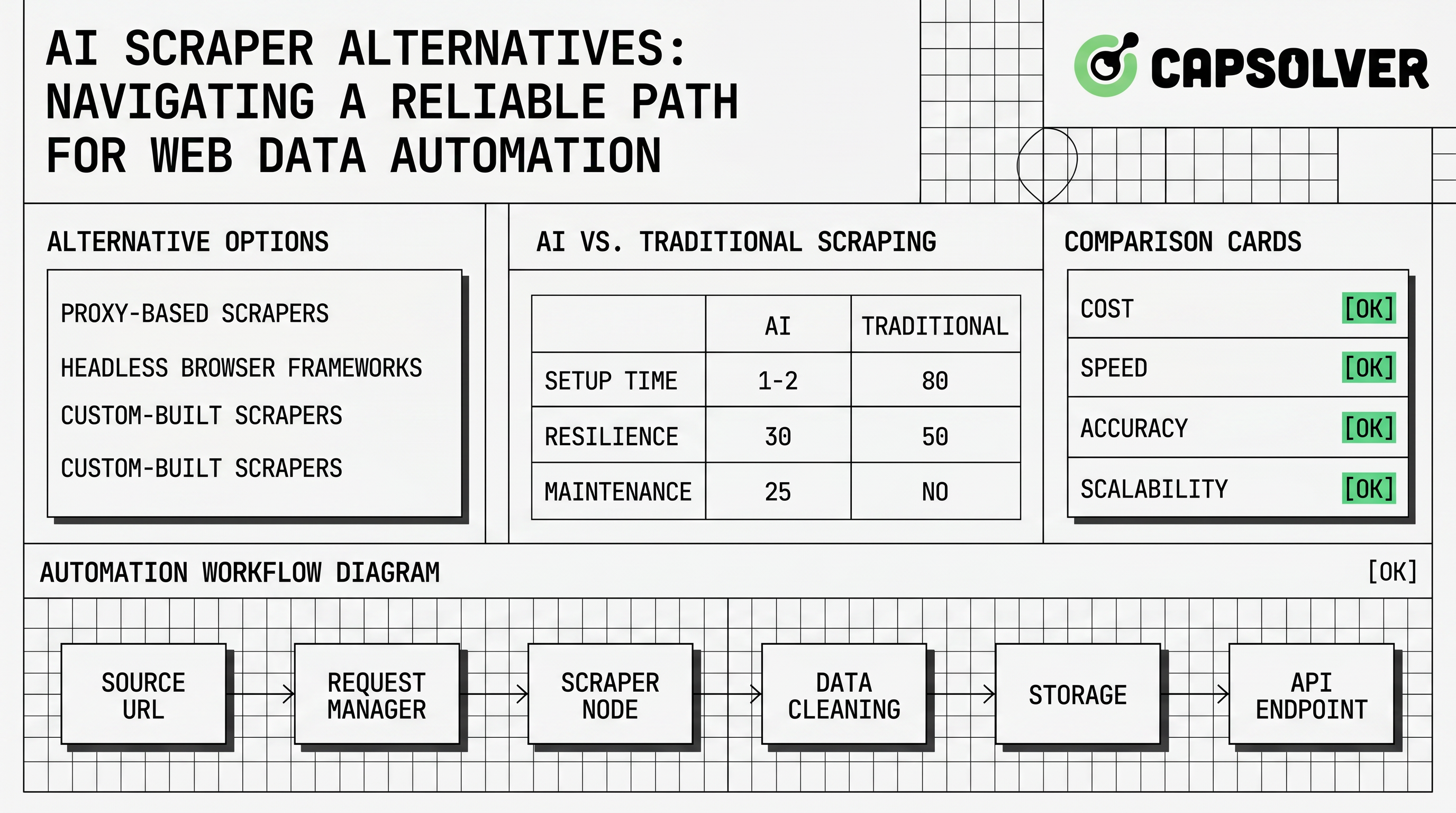
AI स्क्रैपर विकल्प अब केवल दृश्य बिना कोड उपकरण नहीं हैं। अब इनमें ब्राउजर एजेंट, निष्कर्षण API, क्रॉलर फ्रेमवर्क और मशीन लर्निंग के केवल मूल्य जोड़ते समय उपयोग किए जाने वाले हाइब्रिड वर्कफ़्लो शामिल हैं। सबसे अच्छा चयन वह है जो अनुमोदित सार्वजनिक डेटा को सटीक रूप से एकत्र करता है, वर्कफ़्लो के व्यवहार के बारे में दस्तावेज़ करता है और ट्रैफिक वैधता घटनाओं के साथ जिम्मेदारी से निपटता है। जब अनुमोदित स्वचालन को CAPTCHA या समान चुनौती तक पहुंचता है, तो CapSolver के स्क्रैपिंग के दौरान CAPTCHA हल करने का गाइड टीमों को एक नियंत्रित अपवाद मार्ग निर्धारित करने में सहायता कर सकता है, बजाय इसे पूरी रणनीति के रूप में लेने के। इस गाइड में AI-पहला, API-पहला, ब्राउजर-पहला और हाइब्रिड विकल्पों की तुलना की गई है ताकि टीमें निर्भरता से वेब डेटा स्वचालन बना सकें बिना टूटे हुए स्क्रैपिंग पैटर्न को दोहराएं।
क्या AI स्क्रैपर विकल्प के रूप में माना जाता है
AI स्क्रैपर विकल्प कोई भी उपकरण या आर्किटेक्चर है जो टीम को ब्रेकेबल एकल-सेलेक्टर के बजाय संरचित वेब डेटा एकत्र करने में मदद करता है। कुछ उपकरण पृष्ठों से क्षेत्रों के अनुमान के लिए भाषा मॉडल का उपयोग करते हैं। अन्य प्रबंधित रेंडरिंग, योजना बनाए रखे गए क्रॉलिंग, प्रॉक्सी रूटिंग या तैयार निष्कर्षण API प्रदान करते हैं। पारंपरिक फ्रेमवर्क भी स्थिर लक्ष्य साइट संरचना के मामले में आसानी से जांच, परीक्षण और रखरखाव के लिए अभी भी संबंधित हैं।
बाजार व्यापक है क्योंकि वेब पृष्ठ अलग-अलग होते हैं। उत्पाद कैटलॉग, नौकरी बोर्ड, यात्रा सूची और सार्वजनिक निर्देशिकाएं सभी अलग-अलग मार्कअप, पृष्ठांतरण, लेजी लोडिंग और सत्र व्यवहार प्रस्तुत करते हैं। IBM के AI स्क्रैपिंग के बारे में अवलोकन AI स्क्रैपिंग के रूप में वेबसाइट डेटा निष्कर्षण के लिए AI के उपयोग को वर्णित करता है। Scrapy दस्तावेज़ एक प्रोग्रामनीय क्रॉलर फ्रेमवर्क है जो संरचित निष्कर्षण के लिए है। गंभीर टीमें आमतौर पर दोनों अवधारणाओं की आवश्यकता होती है, क्योंकि AI मैपिंग कार्य को कम कर सकता है जबकि निश्चित कोड उत्पादन के लिए पूर्वानुमान बनाए रखता है।
| विकल्प प्रकार | सबसे अच्छा फिट | मुख्य लाभ | नियंत्रित जोखिम |
|---|---|---|---|
| AI निष्कर्षण उपकरण | बदलते लेआउट और अर्ध-संरचित पृष्ठ | तेजी से क्षेत्र मैपिंग और कम सेटअप प्रयास | आउटपुट विचलन और कम एडिट बनाए रखने की क्षमता |
| ब्राउजर ऑटोमेशन | डायनामिक एप्लिकेशन और जावास्क्रिप्ट-भारी पृष्ठ | वास्तविक-पृष्ठ निष्पादन और अंतरक्रिया समर्थन | उच्च लागत, समय विफलताएं और चुनौती घटनाएं |
| स्क्रैपिंग API | प्रबंधित रेंडरिंग और ऑपरेशनल सरलता | कम बुनियादी ढांचा कार्य | विक्रेता बंधन और कम वर्कफ़्लो नियंत्रण |
| क्रॉलर फ्रेमवर्क | स्थिर पृष्ठ और दोहराए जाने वाले पाइपलाइन | मजबूत परीक्षण और संस्करण नियंत्रण | अधिक इंजीनियरिंग कार्य पहले |
| हाइब्रिड स्टैक | मिश्रित लक्ष्यों वाली उत्पादन टीमें | लचीलापन और नियंत्रण के बीच संतुलन | स्पष्ट मालिकता और दस्तावेज़ की आवश्यकता होती है |
AI स्क्रैपर विकल्पों का चयन कार्यप्रवाह स्तर पर किया जाना चाहिए। एक डेमो में आकर्षक लगने वाला उपकरण अपने अनुमोदन रिकॉर्ड करने, साइट नियमों के सम्मान, सुरक्षित पुनर्प्रयास और पृष्ठ बदल जाने पर बंद करने में असमर्थ हो सकता है।
AI स्क्रैपर विकल्पों के लिए मूल्यांकन मानदंड
पहला मानदंड डेटा सटीकता है। एक आधुनिक स्क्रैपर को स्थिर क्षेत्र वापस करना चाहिए, स्रोत URL को बरकरार रखना चाहिए और अनिश्चितता को दृश्य बनाए रखना चाहिए। AI-आधारित निष्कर्षण के लिए, इसका अर्थ नमूना आउटपुट का निरीक्षण, मानव-समीक्षित रिकॉर्ड के साथ तुलना करना और अफवाह के क्षेत्रों के लिए निगरानी करना है। निश्चित क्रॉलर के लिए, इसका अर्थ यूनिट परीक्षण, सेलेक्टर निगरानी और खाली या बदले गए पृष्ठों के स्पष्ट निपटान है।
दूसरा मानदंड जिम्मेदार पहुंच है। टीमें ऑटोमेशन शुरू करने से पहले robots.txt, शर्तें, API उपलब्धता, दर सीमा और सौदा अनुमति की समीक्षा करनी चाहिए। RFC 9309 रोबोट्स अपवर्जन प्रोटोकॉल रोबोट्स.txt को एक ऑटोमेटेड क्लाइंट के लिए एक प्रोटोकॉल के रूप में परिभाषित करता है जो पहुंच नियमों की पहचान करता है, जबकि MDN URL रेफरेंस टीमों के लिए उपयोगी होता है जब वे कैनॉनिकल URL को मानकीकृत करते हैं और रिकॉर्ड को दोहराए बिना छोड़ देते हैं। तकनीकी क्षमता निजी, संवेदनशील, सीमित या अनुमति वाले डेटा के एकत्रीकरण के लिए अनुमति नहीं बनाती है।
तीसरा मानदंड चुनौती निपटान है। कुछ अनुमोदित लक्ष्य CAPTCHA, Cloudflare Turnstile या अन्य ट्रैफिक वैधता प्रणाली का उपयोग करते हैं। इन मामलों में, CAPTCHA हल करना एक दस्तावेज़ किए गए अपवाद मार्ग के रूप में विचार किया जाना चाहिए जिसमें अनुमोदन, दर सीमा, लॉग रेडैक्ट करना और परिणाम वैधता शामिल है। CapSolver के CAPTCHA शब्दावली टीमों को वर्कफ़्लो डिज़ाइन करने से पहले शब्दावली के साथ समायोजित करने में मदद करता है।
CAPTCHA हल करना वेब डेटा स्वचालन में कहां फिट होता है
CAPTCHA हल करना AI स्क्रैपर आर्किटेक्चर का केंद्र नहीं है, लेकिन अनुमोदित स्वचालन के लिए आवश्यक विश्वसनीयता स्तर हो सकता है। सही क्रम सरल है। पहले, जब वे मौजूद होते हैं, तो आधिकारिक API या डेटा फीड का उपयोग करें। दूसरे, जब पृष्ठ स्थिर और अनुमति होती है, तो हल्का HTTP निष्कर्षण का उपयोग करें। तीसरे, जब रेंडरिंग या अंतरक्रिया की आवश्यकता होती है, तो केवल ब्राउजर ऑटोमेशन का उपयोग करें। अंत में, केवल जब वर्कफ़्लो अनुमोदित होता है और पृष्ठ वैधता चरण प्रस्तुत करता है, तो एक नियंत्रित चुनौती-निपटान मार्ग जोड़ें।
इस कारण से, CapSolver को एक वर्कफ़्लो घटक के रूप में सबसे अच्छा पेश किया जाता है। CapSolver के वेब स्क्रैपिंग FAQ टीमों को निष्कर्षण वर्कफ़्लो के लिए संदर्भ प्रदान करता है, जबकि CapSolver Playwright एकीकरण गाइड चुनौती निपटान के ब्राउजर ऑटोमेशन से कैसे जुड़ सकते हैं दिखाता है। लक्ष्य न केवल प्रत्येक स्क्रैपर को एक चुनौती-हल करने वाली सेवा से गुजरने के लिए बाध्य करना है। लक्ष्य एक अपवाद मार्ग को संगत, एडिट करने योग्य और आसानी से परीक्षण करने योग्य बनाना है।
अनुमोदित स्वचालन परीक्षण के लिए अतिरिक्त कोड
CapSolver अतिरिक्त कोड का उपयोग करें
अपने स्वचालन बजट को तत्काल बढ़ाएं!
CapSolver खाता में अतिरिक्त कोड CAP26 का उपयोग करके अपने खाते के भंडार में जोड़ें ताकि प्रत्येक भंडार में 5% का अतिरिक्त बोनस मिले — कोई सीमा नहीं।
अपने CapSolver डैशबोर्ड में अब इसे देखें
AI स्क्रैपर विकल्पों के लिए व्यावहारिक आर्किटेक्चर
एक विश्वसनीय आर्किटेक्चर खोज, निष्कर्षण, मान्यता और संग्रहण के बीच अलग करता है। खोज अनुमोदित URL और योजना नियमों की पहचान करती है। निष्कर्षण निम्नतम जटिलता वाली विधि का उपयोग करता है जो काम करता है, जैसे API कॉल, HTTP पार्सर, ब्राउजर ऑटोमेशन या AI निष्कर्षण प्रॉम्प्ट। मान्यता डेटा संरचना पूर्णता, दोहराए गए रिकॉर्ड, समय टैग और स्रोत साक्ष्य की जांच करती है। संग्रहण अनुपालन टीमों के लिए कच्चे फ़ोटोशॉप या ट्रेस ID को संग्रहीत करता है जब वे संग्रह प्रक्रिया की समीक्षा करना चाहते हैं।
डायनामिक पृष्ठों के लिए, ब्राउजर टूल्स जैसे Playwright दस्तावेज़ नियंत्रित रेंडरिंग और अंतरक्रिया प्रदान करते हैं। क्रॉलर पाइपलाइन के लिए, फ्रेमवर्क जैसे Scrapy समय योजना, आइटम पाइपलाइन और मध्यवर्ती सामग्री प्रदान करते हैं। चुनौती घटनाओं के लिए, टीमें डिबगिंग के दौरान CapSolver के ब्राउजर-एक्सटेंशन गाइड का संदर्भ ले सकती हैं और फिर स्थिर वर्कफ़्लो को API-पहला एकीकरण में ले जा सकती हैं। इससे मानव निदान को दोहराए जाने वाले उत्पादन स्वचालन से अलग रखा जाता है।
| वर्कफ़्लो स्तर | सुझाए गए नियंत्रण | क्यों महत्वपूर्ण है |
|---|---|---|
| अनुमति समीक्षा | अनुमोदित डोमेन और अनुमति डेटा वर्ग | इच्छित विस्तार से बाहर एकत्रीकरण रोकता है |
| निष्कर्षण | API पहला, फिर HTTP, फिर ब्राउजर, फिर AI-सहायता पार्सिंग | लागत कम करता है और अनावश्यक जटिलता बचाता है |
| चुनौती निपटान | अनुमोदित लक्ष्यों के लिए दस्तावेज़ किया गया CapSolver मार्ग | CAPTCHA घटनाओं को असंगत हस्तचालित ठीक करने से रोकता है |
| मॉनिटरिंग | स्कीमा जांच और पृष्ठ-बदल चेतावनी | खराब डेटा उपयोगकर्ताओं तक पहुंचने से पहले विचलन का पता लगाता है |
| लॉगिंग | रेडैक्ट किए गए कार्य पहचान और स्रोत साक्ष्य | एडिट के बिना समर्थन करता है बिना संवेदनशील मूल्यों के खुलासा किए |
इस आर्किटेक्चर टीमों को बताता है कि कब AI का उपयोग न करें। यदि पृष्ठ में स्थिर मार्कअप और अपेक्षित पृष्ठांतरण मॉडल है, तो निश्चित कोड एक मॉडल-आधारित निष्कर्षण के मुकाबले अधिक विश्वसनीय हो सकता है। यदि स्रोत एक दस्तावेज़ किए गए API प्रदान करता है, तो उस API को स्क्रैपिंग से पहले आमतौर पर आगे रखा जाना चाहिए।
सबसे अच्छा विकल्प कैसे चुनें
जब पृष्ठ लेआउट अक्सर बदलता है और व्यावसायिक मूल्य समीक्षा और मॉनिटरिंग के लिए व्यावहारिक होता है, तो AI-पहला स्क्रैपर चुनें। जब आपकी टीम को कोड बनाए रखने में सक्षम होना चाहिए और दोहराए जाने वाले उत्पादन व्यवहार की आवश्यकता होती है, तो क्रॉलर फ्रेमवर्क चुनें। जब बुनियादी ढांचा लागत मुख्य बाधा होती है, तो प्रबंधित स्क्रैपिंग API चुनें। जब साइट जावास्क्रिप्ट या उपयोगकर्ता-जैसी अंतरक्रिया पर अत्यधिक निर्भर होती है, तो ब्राउजर ऑटोमेशन चुनें। जब अनुमोदित वर्कफ़्लो को समर्थित CAPTCHA या ट्रैफिक वैधता चुनौती में पहुंचता है और टीम को एक संगत हल करने के मार्ग की आवश्यकता होती है, तो CapSolver चुनें।
सुरक्षा और सुसंगतता टीमें शुरू में शामिल होनी चाहिए। OWASP स्वचालित खतरों परियोजना सामान्य अत्याचारी स्वचालन पैटर्न के बारे में बताता है, जो जिम्मेदार प्रणालियों के लिए क्या बचना चाहिए इसका उपयोगी सूची बनाता है। एक जिम्मेदार स्क्रैपर उचित समय पर अपने आप को पहचानता है, सीमाओं का पालन करता है, संवेदनशील डेटा से बचता है और अनुमति या पृष्ठ व्यवहार अस्पष्ट होने पर बंद हो जाता है।
निष्कर्ष
AI स्क्रैपर विकल्पों का मूल्यांकन उपकरणों के रूप में नहीं, बल्कि ऑपरेटिंग मॉडल के रूप में किया जाना चाहिए। सबसे मजबूत टीमें आधिकारिक API, निश्चित क्रॉलर, ब्राउजर ऑटोमेशन, AI निष्कर्षण, मॉनिटरिंग और CAPTCHA चुनौतियों के लिए दस्तावेज़ किए गए अपवाद मार्ग के साथ जुड़े होते हैं। यदि आपके अनुमोदित वेब डेटा वर्कफ़्लो में इस आर्किटेक्चर के हिस्से के रूप में विश्वसनीय चुनौती निपटान की आवश्यकता है, तो CapSolver के जिम्मेदार वेब स्क्रैपिंग गाइड एक व्यावहारिक संदर्भ है क्योंकि यह CAPTCHA निपटान के बारे में जिम्मेदार स्वचालन नीति में कैसे फिट होता है, इसकी व्याख्या करता है।
अक्सर पूछे जाने वाले प्रश्न
AI स्क्रैपर विकल्प क्या हैं?
AI स्क्रैपर विकल्प वेब डेटा निष्कर्षण के लिए उपकरण या आर्किटेक्चर हैं, जिसमें AI निष्कर्षण उपकरण, ब्राउजर ऑटोमेशन, स्क्रैपिंग API, क्रॉलर फ्रेमवर्क और हाइब्रिड सिस्टम शामिल हैं।
किस स्थिति में एक टीम को स्क्रैपिंग के लिए ब्राउजर ऑटोमेशन का उपयोग करना चाहिए?
जब अनुमोदित लक्ष्य पृष्ठ जावास्क्रिप्ट रेंडरिंग, उपयोगकर्ता-जैसी अंतरक्रिया या सरल HTTP मांग द्वारा विश्वसनीय रूप से पकड़े जा सकते हैं नहीं, तो ब्राउजर ऑटोमेशन का उपयोग करें।
क्या हर AI स्क्रैपर को CAPTCHA हल करना आवश्यक है?
नहीं। CAPTCHA हल करना केवल तभी आवश्यक है जब अनुमोदित वर्कफ़्लो को समर्थित चुनौती तक पहुंचता है। बहुत सारे वेब स्क्रैपिंग कार्यों के लिए आधिकारिक API, स्थिर निष्कर्षण या डेटा साझाकरण का उपयोग करना बेहतर होता है।
CapSolver AI स्क्रैपर विकल्पों के समर्थन में कैसे मदद कर सकता है?
CapSolver अनुमोदित वर्कफ़्लो के समर्थन में CAPTCHA और ट्रैफिक वैधता चुनौतियों को दस्तावेज़ किए गए API या ब्राउजर-एक्सटेंशन मार्गों के माध्यम से हल कर सकता है, विशेष रूप से QA, मॉनिटरिंग और ब्राउजर ऑटोमेशन में।
सबसे सुरक्षित तरीका क्या है?
अनुमति समीक्षा, robots.txt समीक्षा और छोटे पायलट से शुरू करें। फिर आधिकारिक API, क्रॉलर, ब्राउजर और AI निष्कर्षण विकल्पों की तुलना करें जब आवश्यकता हो तो CAPTCHA चुनौती निपटान जोड़ें।
अनुपालन अस्वीकरण: इस ब्लॉग पर प्रदान की गई जानकारी केवल सूचनात्मक उद्देश्यों के लिए है। CapSolver सभी लागू कानूनों और विनियमों का पालन करने के लिए प्रतिबद्ध है। CapSolver नेटवर्क का उपयोग अवैध, धोखाधड़ी या दुरुपयोग करने वाली गतिविधियों के लिए करना सख्त वर्जित है और इसकी जांच की जाएगी। हमारे कैप्चा समाधान उपयोगकर्ता अनुभव को बेहतर बनाने के साथ-साथ सार्वजनिक डेटा क्रॉलिंग के दौरान कैप्चा कठिनाइयों को हल करने में 100% अनुपालन सुनिश्चित करते हैं। हम अपनी सेवाओं के जिम्मेदार उपयोग की प्रोत्साहना करते हैं। अधिक जानकारी के लिए, कृपया हमारी सेवा की शर्तें और गोपनीयता नीति पर जाएं।
अधिक
भर्ती स्वचालन और CAPTCHA हल करना: 2026 का एक गाइड सत्यापन के लिए भर्ती स्टैक के पार
भर्ती स्वचालन पोस्टिंग, स्रोत और फ़िल्टरिंग को कवर करता है, और प्रत्येक चरण में CAPTCHA हो सकता है। सत्यापन घर्षण कहाँ दिखाई देता है, क्यों प्लेटफॉर्म इसे ट्रिगर करते हैं, और कोड के साथ इसे संगत रूप से कैसे हल करें।
Rajinder Singh
10-Jun-2026
क्यों आपका ब्राउज़र उपयोगकर्ता एजेंट लगातार ब्लॉक कर दिया जा रहा है
एक ब्राउज़र उपयोगकर्ता एजेंट तब ब्लॉक कर दिया जाता है जब इसकी ट्रैफिक नेटवर्क, ब्राउज़र और व्यवहार के स्तरों पर स्वचालित दिखाई देती है। स्वचालन चलता रहे, चार वास्तविक कारणों और उनके समाधानों के बारे में जानें।
Rajinder Singh
04-Jun-2026
पुपेटीयर को बॉट के रूप में पहचाना गया? इसे कैसे ठीक करें
पुपेटीयर को बॉट के रूप में पहचाना गया? इसे कैसे ठीक करें एक सामान्य प्रश्न है क्योंकि कई ऑटोमेशन परियोजनाएं एक कार्यरत स्थानीय स्क्रिप्ट के साथ शुरू होती हैं और फिर एक वास्तविक वेबसाइट पर विफल रहती हैं। समस्या एक सेटिंग के रूप में अपेक्षाकृत दुर्लभ होती है। वेबसाइटें अक्सर ब्राउजर के गुणों का मूल्यांकन करती हैं, अनुरोध ऐतिहासिक...
Rajinder Singh
04-Jun-2026

मेरा प्लेयराइट बॉट क्यों पहचाना जा रहा है?
क्यों मेरा प्लेयराइट बॉट पहचाना जा रहा है? संक्षिप्त उत्तर यह है कि लक्ष्य वेबसाइट प्लेयराइट के साथ अकेले मूल्यांकन नहीं कर रहा है। यह एक पूर्ण ट्रैफिक प्रोफाइल का मूल्यांकन कर रहा है जो ब्राउजर स्थिति, जावास्क्रिप्ट-दृश्य संपत्तियां, टीएलएस और नेटवर्क व्यवहार, सत्र इतिहास...
Rajinder Singh
04-Jun-2026
AI स्क्रैपर के वैकल्पिक विकल्प भरोसेमंद वेब डेटा स्वचालन के लिए
कैपसॉल्वर के साथ AI स्क्रेपर विकल्प की तुलना सुसंगत डेटा निकासी, ब्राउज़र स्वचालन, एपीआई-पहला वर्कफ़्लो और कैप्चा चुनौती प्रबंधन के लिए करें।
Rajinder Singh
27-May-2026