







रस्ट वेब स्क्रैपिंग आर्किटेक्चर लिए स्केलेबल डेटा निष्कर्षण

Rajinder Singh
Deep Learning Researcher
22-Apr-2026
टीएल; डीआर
- रस्ट वेब स्क्रैपिंग को अलग-अलग स्तरों में डेटा लोड करने, पार्स करने, रेंडर करने और संग्रहीत करने के लिए अलग-अलग लेयर में विभाजित करके सबसे अच्छा काम करता है।
reqwestऔरscraperकई स्थिर लक्ष्यों को कम संसाधन लागत और स्पष्ट रखरखाव के साथ कवर करते हैं।- टोकियो के साथ एसिंक स्क्रैपिंग आईओ-बाउंड कार्यभार के लिए प्रवाह में सुधार करता है, लेकिन अभी भी दर सीमा, पुन: प्रयास और बफर नियंत्रण की आवश्यकता होती है।
- हेडलेस ब्राउज़र स्क्रैपिंग को जावास्क्रिप्ट-रेंडर किए गए पृष्ठों के लिए चयनात्मक विकल्प के रूप में उपयोग करें, बजाय डिफ़ॉल्ट पथ के।
- बॉट सुरक्षा, प्रॉक्सी घूर्णन और कैप्चा घटनाओं के साथ नीति और संगत स्वचालन डिज़ाइन के साथ निपटें।
- वास्तविक व्यावसायिक आवश्यकताओं के लिए वैध स्वचालन कार्यप्रणाली के लिए, CapSolver अपने आधिकारिक API प्रवाह का अनुसरण करके एक निर्दिष्ट विकल्प परत में फिट हो सकता है।
रस्ट वेब स्क्रैपिंग एक आर्किटेक्चर के रूप में डिज़ाइन करने पर सबसे अच्छा काम करता है, न कि एक एकल स्क्रिप्ट के रूप में। यह लेख इंजीनियरों, डेटा टीमों और तकनीकी ऑपरेटरों के लिए है जिन्हें पैमाने पर भरोसेमंद निकासी की आवश्यकता होती है। मुख्य निष्कर्ष पहले आता है: सबसे अच्छे रस्ट वेब स्क्रैपिंग प्रणाली जाली पथ को सरल रखते हैं reqwest और scraper के साथ, फिर जब लक्ष्य वास्तव में उनकी आवश्यकता करते हैं, तो एसिंक स्क्रैपिंग, हेडलेस ब्राउज़र स्क्रैपिंग, प्रॉक्सी घूर्णन और चुनौती संभालने के साथ बढ़ाएं। इस संरचना लागत कम करती है, स्थिरता में सुधार करती है और लंबे समय तक चलने वाले पाइपलाइन को अवलोकन करने में आसान बनाती है।
रस्ट वेब स्क्रैपिंग समीक्षा
रस्ट वेब स्क्रैपिंग बड़े निकासी कार्यों के लिए एक मजबूत विकल्प है क्योंकि यह स्मृति सुरक्षा के साथ भव्य प्रदर्शन के साथ जुड़ता है। ये गुण तब महत्वपूर्ण होते हैं जब एक कार्यकर्ता हजारों पृष्ठों को प्रक्रिया कर सकता है, अस्थिर मार्कअप को पार्स कर सकता है और घंटों तक सामान्यीकृत रिकॉर्ड लिख सकता है।
अधिकांश लेख शीर्ष खोज परिणामों में एक पृष्ठ लोड करने और एक सेलेक्टर पार्स करने के बारे में बताते हैं। यह सामग्री उपयोगी है, लेकिन यह आमतौर पर कठिन सवाल का उत्तर नहीं देता है। जब आपको बहुत बड़े पैमाने पर बहुत बड़े पैमाने पर भरोसेमंद निकासी की आवश्यकता होती है, तो पूर्ण रस्ट वेब स्क्रैपिंग आर्किटेक्चर कैसा दिखता है?
एक उत्पादन डिज़ाइन में आमतौर पर एक HTTP फेच लेयर, एक पार्सर लेयर, जावास्क्रिप्ट पृष्ठों के लिए रेंडरिंग शाखा, एक संग्रह लेयर, और एक ऑपरेशनल लेयर (पुन: प्रयास, मीट्रिक्स और अनुरोध गति के लिए) की आवश्यकता होती है। सही क्रम भी महत्वपूर्ण है। पहले सबसे कम लागत वाले पथ के साथ शुरू करें। कच्चा HTML लोड करें। केवल आवश्यक फील्ड को पार्स करें। जब डेटा लक्ष्य के लिए आवश्यकता होती है तो हेडलेस ब्राउज़र स्क्रैपिंग के लिए बढ़ें। प्रॉक्सी घूर्णन केवल जब ट्रैफिक वितरण या क्षेत्रीय पहुंच आवश्यक होती है। कैप्चा संभालने के लिए केवल जब एक संगत स्वचालन प्रवाह के लिए वैध कारण होता है।
टीमों के लिए सीमाओं की योजना बनाने के लिए, वेब क्रॉलिंग और वेब स्क्रैपिंग स्कोप को स्पष्ट करता है, और संरचित डेटा कैसे निकालें डेटा नक्शा बनाने से पहले एक उपयोगी आंतरिक पठन है।
रस्ट स्क्रैपिंग के लिए मुख्य प per लाइब्रेरी
रस्ट वेब स्क्रैपिंग आमतौर पर तीन निर्माण ब्लॉक से शुरू होता है: reqwest, scraper, और टोकियो। आधिकारिक reqwest दस्तावेज़ के रूप में बताता है कि reqwest एक उच्च-स्तर के HTTP क्लाइंट है जिसमें एसिंक समर्थन, कुकीज़, पुनर्निर्देश, TLS और प्रॉक्सी समर्थन होता है। इसके कारण यह रस्ट वेब स्क्रैपिंग के लिए एक व्यावहारिक ट्रांसपोर्ट परत है।
आधिकारिक टोकियो एसिंक ट्यूटोरियल बताता है कि क्यों फ्यूचर्स और एक्सीक्यूटर मॉडल उच्च-समानांतरता आईओ कार्यभार के लिए फिट होते हैं। यह तब महत्वपूर्ण होता है जब रस्ट वेब स्क्रैपिंग अपना अधिकांश समय दूर के सर्वरों पर प्रतीक्षा करता है, न कि स्थानीय गणना पर सीपीयू जलाने में।
reqwest के साथ HTTP मांगें
reqwest ट्रांसपोर्ट परत में होना चाहिए। प्रत्येक कार्यकर्ता या कार्यकर्ता समूह के लिए एक एकल क्लाइंट का उपयोग करें। इससे कनेक्शन पूलिंग प्रभावी रहता ह और आपको सभी जगह शीर्षक, समय सीमा, कुकीज़ और प्रॉक्सी नीति को परिभाषित करने के लिए एक स्थान मिलता है।
rust
use reqwest::Client;
use scraper::{Html, Selector};
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
let client = Client::builder()
.user_agent("Mozilla/5.0")
.build()?;
let html = client
.get("https://example.com")
.send()
.await?
.error_for_status()?
.text()
.await?;
let document = Html::parse_document(&html);
let card = Selector::parse("article")?;
for node in document.select(&card) {
println!("{}", node.text().collect::<Vec<_>>().join(" "));
}
Ok(())
}इस पैटर्न रस्ट वेब स्क्रैपिंग को स्थिर पृष्ठों पर दक्ष बनाता है। यह त्रुटि संभालने को सामान्य बनाने में भी सरल बनाता है। स्थिति जांच, पुन: प्रयास बजट और संरचित लॉग्स सभी अनुरोध परत के आसपास रहते हैं, न कि पार्सर कोड में मिश्रित होते हं।
scraper के साथ HTML पार्सिंग
scraper एक पार्सर परत में होना चाहिए जो छोटा और परीक्षण योग्य रहता है। यदि आप टेम्पलेट बदलाव की उम्मीद करते हैं, तो सेलेक्टर्स को नेटवर्क लॉजिक के साथ मिलाएं। एक मजबूत पार्सर कच्चा HTML स्वीकार करता है और टाइप किए गए रिकॉर्ड, आंशिक रिकॉर्ड या स्पष्ट निकासी त्रुटि लौटाता है।
इस विभाजन का महत्व तब होता है जब सेलेक्टर विस्थापन आम होता है। वर्ग बदल जाते हैं। टेक्स्ट लक्ष्य तत्वों के बीच विशेषता अनुक्रमणिका में आ जाता है। रस्ट वेब स्क्रैपिंग में पार्सर अलगाव तब तक टेस्ट में दृश्यमान रहता है जब तक पूरे पाइपलाइन अपूर्ण डेटा लिखना शुरू नहीं करता है।
एसिंक स्क्रैपिंग आर्किटेक्चर
एसिंक स्क्रैपिंग रस्ट वेब स्क्रैपिंग के लिए बड़े पैमाने पर पैमाने पर फैलाने के मुख्य कारणों में से एक है। रनटाइम वेबसाइटों को तेजी से जवाब नहीं देता है। यह कार्यकर्ता को अधिक कुशल बनाता है जब बहुत सारे अनुरोध नेटवर्क या मूल प्रतिक्रिया पर प्रतीक्षा कर रहे होते हैं।
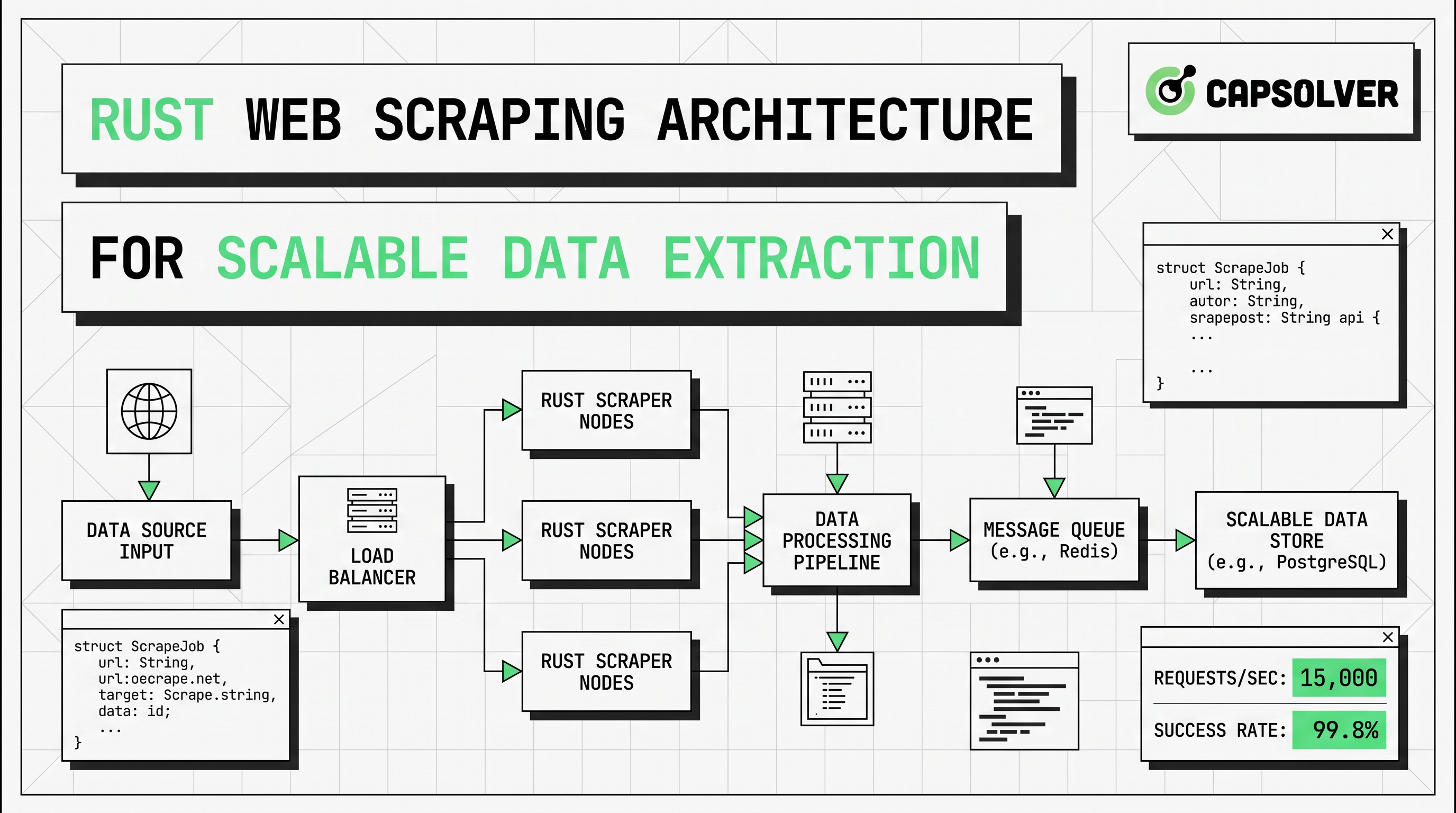
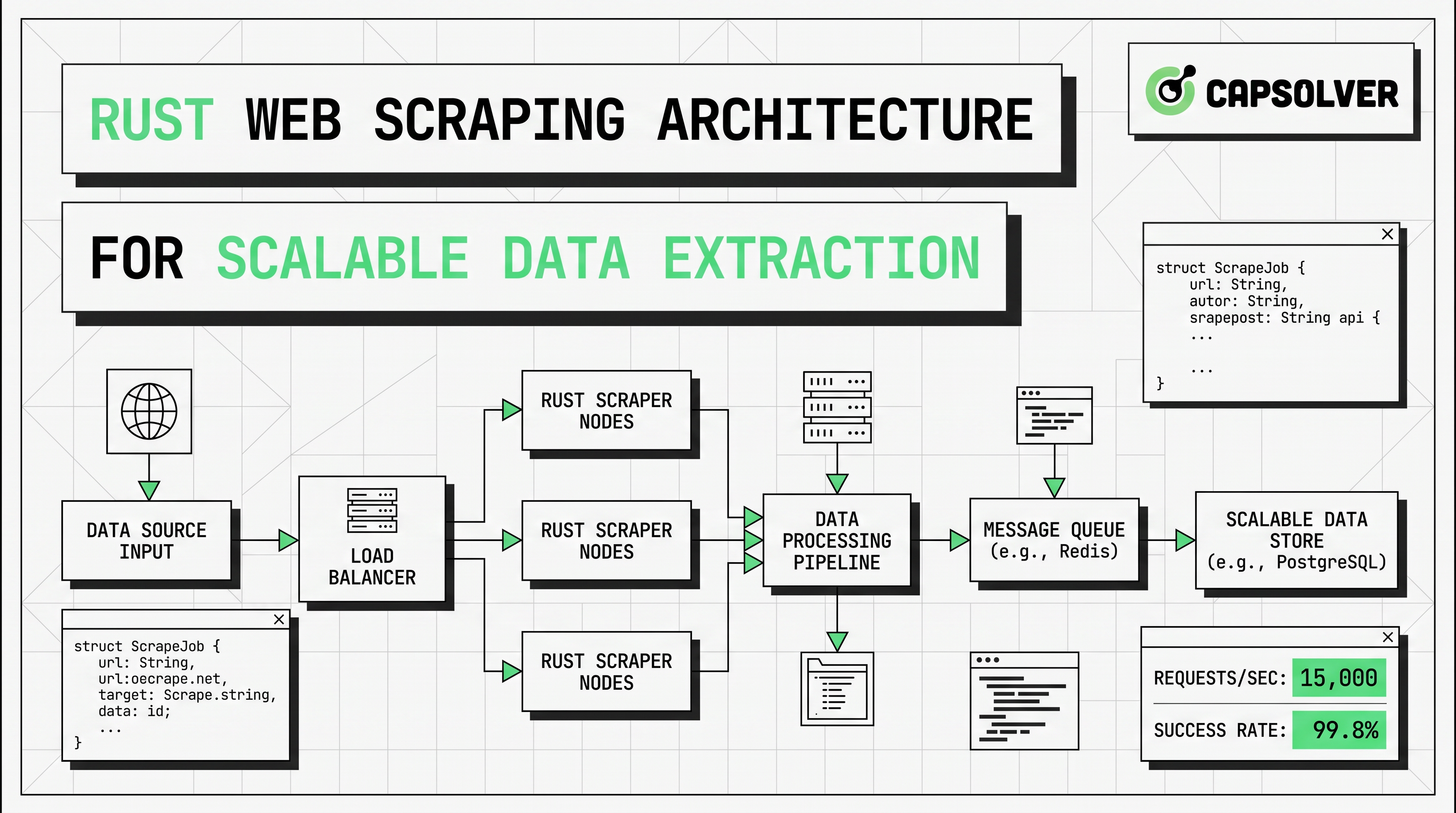
एक विस्तारित रस्ट वेब स्क्रैपिंग पाइपलाइन आमतौर पर नीचे दिए गए संरचना के साथ अनुसरण करता है।
| परत | भूमिका | रस्ट के लिए डिफ़ॉल्ट | मुख्य जोखिम |
|---|---|---|---|
| स्केड्यूलर | यूआरएल्स चुनता है और प्राथमिकता | बफर या चैनल | अस्थायी ट्रैफिक |
| फेचर | HTTP अनुरोध भेजता है | reqwest::Client |
403, 429, समय सीमा समाप्त हो गई |
| पार्सर | फील्ड निकालता है | scraper सेलेक्टर |
टेम्पलेट विस्थापन |
| रेंडरर | जावास्क्रिप्ट पृष्ठ लोड करता है | हेडलेस ब्राउज़र स्क्रैपिंग | सीपीयू और मेमोरी लागत |
| चुनौती परत | अनुमत कैप्चा घटनाओं के साथ निपटता है | कैप्सॉल्वर विकल्प | गलत कार्य प्रकार |
| संग्रह | सामान्यीकृत आउटपुट लिखता है | JSON, CSV, DB | स्कीमा असंगतता |
| अवलोकन | स्वास्थ्य और गुणवत्ता की ट्रैकिंग करता है | लॉग्स, ट्रेसिंग, मीट्रिक्स | छिपे डेटा हानि |
मुख्य डिज़ाइन नियम चयनात्मक बढ़त है। प्रत्येक लक्ष्य के साथ कम लागत वाले पथ से शुरू करें। यदि लौटे गए HTML में डेटा पहले से मौजूद है, तो reqwest और scraper के साथ रहें। यदि लक्ष्य फील्ड केवल हाइड्रेशन, क्लाइंट-साइड रेंडरिंग या ब्राउज़र घटनाओं के बाद दिखाई देते हैं, तो केवल उस पृष्ठ प्रकार को हेडलेस ब्राउज़र स्क्रैपिंग के लिए रास्ता दें। यदि अनुमोदित कार्यप्रणाली में बॉट सुरक्षा या कैप्चा जांच दिखाई देती है, तो केवल उन घटनाओं को एक छोटी विकल्प परत में रास्ता दें।
इस जगह पर कई प्रणालियां बर्बाद हो जाती हैं। टीमें हर अनुरोध के लिए ब्राउज़र स्वचालन के लिए डिफ़ॉल्ट करती हैं। इससे लागत बढ़ जाती है, समानांतरता घट जाती है, और विफलताओं को वर्गीकृत करना कठिन हो जाता है। HTTP आर्काइव जावास्क्रिप्ट की स्थिति रिपोर्ट बताती है कि आधुनिक पृष्ठ जावास्क्रिप्ट पर अधिक निर्भर हैं, जहां माध्यमिक डेस्कटॉप जावास्क्रिप्ट ट्रांसफर आकार 803.3 केबी और चयनित रिपोर्ट दृश्य में 23 बाहरी स्क्रिप्ट अनुरोध हैं। इससे समझ में आता है कि कुछ लक्ष्यों के लिए रेंडरिंग की आवश्यकता होती है, लेकिन यह हर पृष्ठ के लिए ब्राउज़र के उपयोग के लिए वैधता नहीं देता है।
जावास्क्रिप्ट-रेंडर किए गए पृष्ठों का सामना कैसे करें
जब डेटा प्रारंभिक HTML प्रतिक्रिया के बाद बनाया जाता है, तो हेडलेस ब्राउज़र स्क्रैपिंग आवश्यक होता है। सामान्य संकेत खाली सर्वर HTML, जल्दी से भरे गए सामग्री, असीमित स्कॉल लिस्ट, या उपयोगकर्ता अंतरक्रिया के बाद केवल फील्ड खुलते हैं।
रस्ट वेब स्क्रैपिंग ब्राउज़र रेंडरिंग को एक अलग शाखा के रूप में लेता है, न कि सार्वभौमिक आधार के रूप में। उसे जावास्क्रिप्ट-आधारित उत्पाद ग्रिड के लिए उपयोग करें जो क्लाइंट अनुरोध के बाद भर जाते हैं, ब्राउज़र में रेंडर किए गए डैशबोर्ड, या ऐसे इंटरफ़ेस जहां महत्वपूर्ण सामग्री क्लिक और स्क्रॉल तकनीक के पीछे छिपी होती है। ब्राउज़र पूल को छोटा रखें, और इसे अपने मुख्य एसिंक HTTP कार्यकर्ता से अलग रखें।
एक व्यावहारिक निर्णय नियम सरल है। यदि डेटा कच्चे HTML में मौजूद है, तो reqwest और scraper के साथ रहें। यदि फील्ड केवल जावास्क्रिप्ट निष्पादन के बाद दिखाई देते हैं, तो उस रास्ते को हेडलेस ब्राउज़र स्क्रैपिंग में स्थानांतरित करें। यदि एक ही लक्ष्य बॉट सुरक्षा नियंत्रण के साथ लागू होता है, तो नेटवर्क नीति, ब्राउज़र व्यवहार और विकल्प आवश्यकताओं के साथ एक साथ समीक्षा करें बजाय एक-एक करके उन्हें ठीक करने के।
संबंधित आंतरिक पठन के लिए, विकासकर्ता के लिए ब्राउज़र स्वचालन और हेडलेस ब्राउज़र में कैप्चा हल करना स्वचालित करें इस लेयर आकार में बिना किसी अस्पष्टता के फिट होते हैं।
कैप्चा और स्क्रैपिंग सीमाएं
रस्ट वेब स्क्रैपिंग हमेशा सीमाओं के साथ होता है। कुछ तकनीकी हैं। अन्य कानूनी या ऑपरेशनल हैं। तकनीकी पक्ष में IP प्रतिष्ठा, सत्र प्रबंधन, ब्राउज़र फिंगरप्रिंट जांच, छिपे एपीआई और बॉट सुरक्षा के बारे में शामिल हैं। ऑपरेशनल पक्ष में अनुरोध गति, त्रुटि बजट और लक्ष्य साइट पर ट्रैफिक प्रभाव शामिल हैं।
इसलिए, संगतता को आर्किटेक्चर में बनाया जाना आवश्यक है। गूगल सर्च सेंटर रोबोट्स.txt गाइड बताता है कि रोबोट्स.txt मुख्य रूप से क्रॉलर ट्रैफिक को प्रबंधित करने के लिए उपयोग किया जाता है और साइटों के अत्यधिक भार को बचाने के लिए। यह बिंदु रस्ट वेब स्क्रैपिंग के लिए महत्वपूर्ण है क्योंकि एक अच्छी तरह से डिज़ाइन की गई प्रणाली केवल डेटा निकालने की कोशिश करती है। यह भी भार को नियंत्रित करने, अवांछित अनुरोध कम करने और संग्रह व्यवहार को तार्किक बनाए रखने की कोशिश करता है।
जब वैध स्वचालन प्रवाह कैप्चा चरण के सामना करते हैं, तो CapSolver एक निर्दिष्ट विकल्प सेवा के रूप में संबंधित है। सबसे सुरक्षित दृष्टिकोण आधिकारिक दस्तावेज़ का अनुसरण करना है, न कि कस्टम अनुरोध फॉर्मेट बनाना। CapSolver createTask दस्तावेज़ नीचे दिए गए मानक अनुरोध बॉडी पैटर्न दिखाता है।
json
POST https://api.capsolver.com/createTask
Host: api.capsolver.com
Content-Type: application/json
{
"clientKey":"YOUR_API_KEY",
"appId": "APP_ID",
"task": {
"type":"ImageToTextTask",
"body":"BASE64 छवि"
}
}आधिकारिक प्रवाह समान एसिंक्रोनस टास्क के लिए taskId लौटाता है, जिसे फिर getTaskResult के माध्यम से जांचा जाना चाहिए। एक विस्तारित रस्ट वेब स्क्रैपिंग प्रणाली में, इस चुनौती तकनीक को मानक अनुरोध और पार्स के पथ से बाहर रखा जाना चाहिए ताकि सामान्य अनुरोध तेज और निरीक्षण के लिए आसान रहे।
CapSolver बोनस कोड के साथ अपना बोनस प्राप्त करें
अपने स्वचालन बजट को तुरंत बढ़ाएं!
CapSolver खाता में अतिरिक्त 5% बोनस प्रत्येक भरोसा के साथ CAP26 बोनस कोड का उपयोग करें — कोई सीमा नहीं।
अपने CapSolver डैशबोर्ड में अब बोनस कोड का उपयोग करें
बड़े पैमाने पर डेटा संग्रह के लिए रस्ट स्क्रैपर्स के पैमाने को बढ़ाएं
रस्ट वेब स्क्रैपिंग के पैमाने को बढ़ाना अक्सर कोड की मात्रा के बजाय नियंत्रण पर निर्भर करता है। आर्किटेक्चर को प्रति-डोमेन समानांतरता, पुन: प्रयास के ऊपरी सीमा, समय सीमा बजट और आउटपुट सत्यापन के लिए बाध्य करना चाहिए। इन नियंत्रणों के बिना, तेज कार्यकर्ता केवल तेज विफलता बनाते हैं।
प्रॉक्सी घूर्णन ट्रांसपोर्ट परत में होना चाहिए, न कि पार्सर परत में। जब अनुरोधों को दर्जे बराबर बर्बरता के लिए आईपी पतों पर वितरित करना आवश्यक होता है, तो इसका उपयोग करें। जियो एक्सेस या कार्यभार अलगाव। नीति विशिष्ट रखें। डोमेन, अंतर्निहित बिंदु श्रेणी या कार्यभार प्रकार के आधार पर घूर्णन करें। अस्पष्ट प्रॉक्सी घूर्णन बर्ताव के अवधि को बर्बाद कर देता है और डीबगिंग में शोर जोड़ता है।
यह आंतरिक समर्थन संसाधनों के उपयोगी होता है। सर्वोत्तम प्रॉक्सी सेवाएं नेटवर्क रणनीति के मूल्यांकन में सहायता कर सकते हैं, जबकि वेब स्क्रैपिंग कानूनी संग्रह आकार बढ़ाने से पहले एक उपयोगी आंतरिक जांच है।
सबसे मजबूत रस्ट वेब स्क्रैपिंग प्रणालियां सीधे निकासी गुणवत्ता को मापती हैं। असफलता दर, खाली-फील्ड दर, सेलेक्टर विस्थापन, रेंडर अनुपात, माध्यमिक अनुरोध लैटेंसी और प्रत्येक सफल रिकॉर्ड की लागत की निगरानी करें। इन मीट्रिक्स दिखाते हैं कि क्या एक सरल HTML पथ अभी भी पर्याप्त है या जब हेडलेस ब्राउज़र स्क्रैपिंग, प्रॉक्सी घूर्णन या चुनौती संभालने की लागत बढ़ रही है।
तुलना सारांश
| दृष्टिकोण | सबसे अच्छा उपयोग केस | लागत प्रोफ़ाइल | विश्वसनीयता प्रोफ़ाइल | टिप्पणियां |
|---|---|---|---|---|
reqwest + scraper |
स्थिर या हल्का गतिशील पृष्ठ | कम | स्थिर सेलेक्टर के साथ उच्च | रस्ट वेब स्क्रैपिंग के लिए सबसे अच्छा डिफ़ॉल्ट |
| टोकियो कार्यकर्ता के साथ एसिंक स्क्रैपिंग | बहुत सारे आईओ-बाउंड यूआरएल | कम से कम मध्यम | दर सीमा के साथ उच्च | प्रवाह में सुधार करता है, पार्सर गुणवत्ता नहीं |
| हेडलेस ब्राउज़र स्क्रैपिंग | जावास्क्रिप्ट-रेंडर किए गए पृष्ठ | उच्च | मध्यम | छोटे पूल में अलग करें |
| प्रॉक्सी घूर्णन | वितरित दर नियंत्रण और जियो एक्सेस | मध्यम | मध्यम | जब ट्रैफिक पहचान महत्वपूर्ण होती है |
| CapSolver विकल्प | स्वचालन प्रवाह में अनुमत कैप्चा घटनाएं | घटना-आधारित | मध्यम से उच्च | आधिकारिक दस्तावेज़ के साथ विकल्प अनुसार रखें |
निष्कर्ष
रस्ट वेब स्क्रैपिंग तब फैलता है जब आर्किटेक्चर चयनात्मक रहता है। reqwest और scraper के साथ तेज पथ का उपयोग करें। जब आपको नेटवर्क-बाउंड कार्य में अधिक प्रवाह की आवश्यकता होती है, तो एसिंक स्क्रैपिंग जोड़ें। जावास्क्रिप्ट पृष्ठों के लिए हेडलेस ब्राउज़र स्क्रैपिंग को चयनात्मक रूप से छोड़ दें। प्रॉक्सी घूर्णन और चुनौती संभालने को नियंत्रित विकल्प परत के रूप में रखें। इस डिज़ाइन लागत कम करता है, अवलोकन में सुधार करता है और पार्सर रखरखाव को बहुत आसान बनाता है।
यदि आपका वर्तमान पाइपलाइन हर पृष्ठ के लिए ब्राउज़र के माध्यम से ले जाता है, तो सबसे स्पष्ट सुधार आमतौर पर एक पथ विभाजन है। स्थिर लक्ष्यों को सरल HTTP में वापस ले जाएं। जावास्क्रिप्ट पृष्ठों को छोटे रेंडरिंग शाखा में रखें। चुनौती तकनीक को अलग रखें। इस बदलाव से आमतौर पर विश्वसनीयता और इकाई आर्थिकता दोनों में सुधार होता है।
एफक्यूएएस
क्या रस्ट वेब स्क्रैपिंग बड़े कार्यों के लिए पायथन के मुकाबले बेहतर है?
रस्ट वेब स्क्रैपिंग लंबे समय तक स्थिरता, समानांतरता और मेमोरी सुरक्षा के मुख्य लक्ष्यों के लिए एक मजबूत विकल्प होता है। पायथन के पास एक व्यापक स्क्रैपिंग परिदृश्य है, लेकिन रस्ट विशेष लक्ष्यों के लिए आकर्षक है जहां कार्यकर्ता दक्षता और पूर्वानुमानीय प्रदर्शन मुख्य प्राथमिकता है।
reqwest से हेडलेस ब्राउज़र स्क्रैपिंग में कब बदलें?
केवल तभी बदलें जब सर्वर HTML में आपके लिए आवश्यक फील्ड उपलब्ध नहीं हैं। यदि लक्ष्य डेटा हाइड्रेशन के बाद, क्लाइंट-साइड घटनाओं या देर से एपीआई अनुरोध के बाद दिखाई देता है, तो हेडलेस ब्राउज़र स्क्रैपिंग वैध हो जाता है।
रस्ट में एसिंक स्क्रैपिंग कैसे मदद करता है?
असिंक्रोनस स्क्रैपिंग रस्ट वेब स्क्रैपिंग को कम संसाधन खर्च के साथ बहुत सारे अपेक्षा पूर्ण कार्यों का प्रबंधन करने में मदद करता है। यह आई/ओ-बाउंड कार्य के लिए प्रवाह को बेहतर बनाता है, लेकिन अभी भी अनुमति सीमाएं, पुनः प्रयास तर्क और पार्सर परीक्षण की आवश्यकता होती है।
क्या मुझे हमेशा प्रॉक्सी रोटेशन की आवश्यकता होती है?
नहीं। बहुत सारे कार्य बिना इसके अच्छी तरह से काम करते हैं। प्रॉक्सी रोटेशन तब महत्वपूर्ण होता है जब आपके पास क्षेत्रीय पहुंच की आवश्यकता होती है, प्रति-डोमेन ट्रैफिक वितरण, या एक ही आईपी रेंज से कम घनत्व की आवश्यकता होती है।
कैपचा पृष्ठों का संपादन कैसे करें?
कैपचा प्रबंधन को संकीर्ण, दस्तावेज़ीकृत और सामान्य फेच पथ से अलग रखें। यदि एक वैध स्वचालन प्रक्रिया के लिए आवश्यक है, तो आधिकारिक कैपसॉल्वर कार्य प्रवाह का उपयोग करें और कार्यान्वयन को प्रकाशित दस्तावेज़ के साथ संगत रखें।
अनुपालन अस्वीकरण: इस ब्लॉग पर प्रदान की गई जानकारी केवल सूचनात्मक उद्देश्यों के लिए है। CapSolver सभी लागू कानूनों और विनियमों का पालन करने के लिए प्रतिबद्ध है। CapSolver नेटवर्क का उपयोग अवैध, धोखाधड़ी या दुरुपयोग करने वाली गतिविधियों के लिए करना सख्त वर्जित है और इसकी जांच की जाएगी। हमारे कैप्चा समाधान उपयोगकर्ता अनुभव को बेहतर बनाने के साथ-साथ सार्वजनिक डेटा क्रॉलिंग के दौरान कैप्चा कठिनाइयों को हल करने में 100% अनुपालन सुनिश्चित करते हैं। हम अपनी सेवाओं के जिम्मेदार उपयोग की प्रोत्साहना करते हैं। अधिक जानकारी के लिए, कृपया हमारी सेवा की शर्तें और गोपनीयता नीति पर जाएं।
अधिक
रस्ट वेब स्क्रैपिंग आर्किटेक्चर लिए स्केलेबल डेटा निष्कर्षण
Rust में वेब स्क्रैपिंग के स्केलेबल आर्किटेक्चर सीखें, reqwest, scraper, असिंक्रोनस स्क्रैपिंग, हेडलेस ब्राउज़र स्क्रैपिंग, प्रॉक्सी रोटेशन, और संगत CAPTCHA का निपटारा।
Rajinder Singh
22-Apr-2026

रॉक्सीब्राउज़र में कैप्चा हल करना कैपसॉल्वर एकीकरण के साथ
CapSolver के साथ RoxyBrowser के एकीकरण करें ताकि ब्राउज़र के कार्यों को स्वचालित किया जा सके और reCAPTCHA, Turnstile और अन्य CAPTCHAs को बायपास किया जा सके।
Rajinder Singh
04-Feb-2026

ईजीस्पाइडर में कैप्चा हल करें कैपसॉल्वर एकीकरण के साथ
ईज़ीस्पाइडर एक दृश्य, नो-कोड वेब स्क्रैपिंग और ब्राउज़र ऑटोमेशन टूल है, जबकि कैपसॉल्वर के साथ जुड़ा हुआ है, तो यह reCAPTCHA v2 और Cloudflare Turnstile जैसे CAPTCHA को विश्वसनीय रूप से हल कर सकता है, जो वेबसाइटों पर सुचारू रूप से स्वचालित डेटा निकालने की अनुमति देता है।
Rajinder Singh
04-Feb-2026

रीकैपचा वी२ कैसे हल करें रीलेवेंस एआई में कैपसॉल्वर एकीकरण के साथ
रिलेवेंस एआई उपकरण बनाएं जो reCAPTCHA v2 को CapSolver के उपयोग से हल करे। ब्राउजर ऑटोमेशन के बिना एपीआई के माध्यम से फॉर्म जमाकर स्वचालित करें।
Rajinder Singh
03-Feb-2026

2026 में IP बैन: उनके काम करने का तरीका और उन्हें पार करने के व्यावहारिक तरीके
2026 में आईपी बैन बायपास करने के तरीके सीखें हमारे विस्तृत गाइड के साथ। आधुनिक आईपी ब्लॉकिंग तकनीकों और रिजिडेंशियल प्रॉक्सी और कैप्चा सॉल्वर्स जैसे व्यावहारिक समाधानों की खोज करें।

Nikolai Smirnov
26-Jan-2026

कैप्चा कैसे हल करें ब्राउज़र4 में कैपसॉल्वर इंटीग्रेशन के साथ
उच्च बहुतायत ब्राउज़र4 स्वचालन के साथ संयोजित करें, जो बड़े पैमाने पर वेब डेटा निकास में CAPTCHA चुनौतियों का निपटारा करने के लिए CapSolver का उपयोग करता है।
Rajinder Singh
21-Jan-2026