







CapSolver AI-LLMアーキテクチャの実践: 適応型CAPTCHA認識システムの意思決定パイプライン構築

Sora Fujimoto
AI Solutions Architect
10-Feb-2026

CAPTCHAはますます多様化し複雑化しており、単純なテキストチャレンジからインタラクティブなパズル、動的なリスクベースのロジックにまで進化しています。今日の自動化ワークフローは、基本的な画像認識を超え、より高度な処理を必要としています。従来のOCRやスタンドアローンのCNNモデルは、進化する形式や混合された視覚的・意味的タスクに対応できなくなっています。
前回の記事「AI-LLM:リスク制御画像認識とCAPTCHA解決の未来のソリューション」では、現代のCAPTCHAシステムにおいて大規模言語モデルが重要な要素として採用される理由について考察しました。本記事では、その続きとして、CapSolverのAI-LLM意思決定パイプラインの実践的なアーキテクチャを検討します。つまり、異なるCAPTCHAタイプが適切な解決戦略にルーティングされる仕組みや、新規形式の出現に伴うシステムの適応方法についてです。
コア的な課題は、単にピクセルを認識することではなく、CAPTCHAの意図を理解し、リアルタイムで適応することです。CapSolver AI-LLMアーキテクチャは、コンピュータビジョンと高次の推論を組み合わせ、単なるパターンマッチングではなく戦略的な判断を行うように設計されています。
以下にそのアーキテクチャの概要を示します:
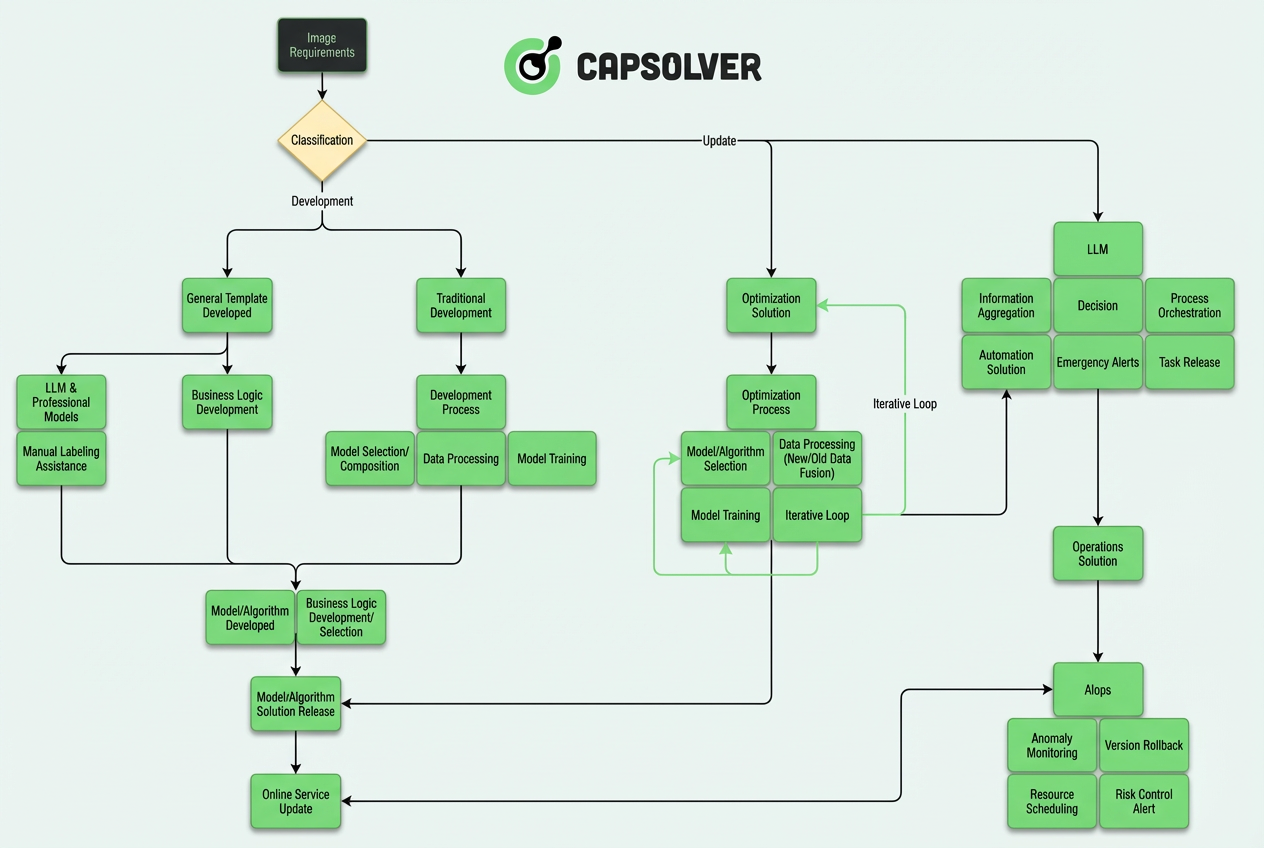
本記事では、私たちの3層構造の自律システムのエンジニアリングに焦点を当て、生の視覚的入力と意味的推論の間の橋渡しについて詳しく説明します。
業界の研究によると、2026年までに80%以上の企業が生成AIを備えたアプリケーションを本番環境で導入する予定であり、これは自動化されたAI駆動のワークフローとマルチモーダルパイプラインへの急速な移行を示しています。
コアアーキテクチャ:3層構造の自律システム
実務経験に基づくと、現代のCAPTCHA認識システムは「モデル+ルール」のモノリシックアーキテクチャから複雑なレイヤーの自律性を持つシステムへと進化しています。全体のアーキテクチャは3つのコアレイヤーに分けられます:
| レイヤー | コアモジュール | 機能的位置付け | 技術スタックの例 |
|---|---|---|---|
| アプリケーション意思決定レイヤー | LLMブレイン | 意味理解、タスクオーケストレーション、異常分析 | GPT-4/Vision、Claude 3、Qwen3、自社開発のLangChainエージェント |
| アルゴリズム実行レイヤー | CVエンジン | オブジェクト検出、軌跡シミュレーション、画像認識 | YOLO、ViT、blip、clip、dino |
| O&M保証レイヤー | AIops | モニタリング、ロールバック、リソーススケジューリング、リスク制御 | Prometheus、Kubernetes、カスタムRL戦略 |
このレイヤー構造のコアコンセプトは、LLMが「考える」役割を担い、CVモデルが「実行」を担当し、AIopsが「保証」を担うことです。
なぜLLMの介入が必要なのか?
従来のCAPTCHA認識には3つの致命的なボトルネックがあります:
- 意味的ギャップ:「xxを含む画像をすべてクリックしてください」や「表示されたアイテムと通常一緒に使用されるアイテムにタッチしてください」などの指示文を理解できないこと。このような質問の種類は増加しています。
- 適応遅延:ターゲットサイトが検証ロジックを更新した場合、手動での再ラベリングと再トレーニングが必要(数日かかるサイクル)。
- 柔軟性の欠如:新しい防御モード(例:敵対的サンプル)に直面した場合、類似の形式が頻繁にバージョンアップし、一部の形式は低通過率のタイプの確率を自動的に増加させることがあります。古いエンジンはこのようなリスク制御の自律的な分析能力がありません。
注意:LLMはCVモデルを置き換えるものではなく、CVシステムの「神経中枢」として、理解と進化の能力を提供します。
意思決定パイプラインの動作メカニズム
全体のシステムは、知覚-判断-実行-進化の閉ループプロセスに従います。これは4つの主要な段階に細分化されます。
ステージ1:インテリジェントルーティング
新しい画像リクエストがシステムに送信されると、最初にLLM駆動の分類器を経由してインテリジェントルーティングされます:
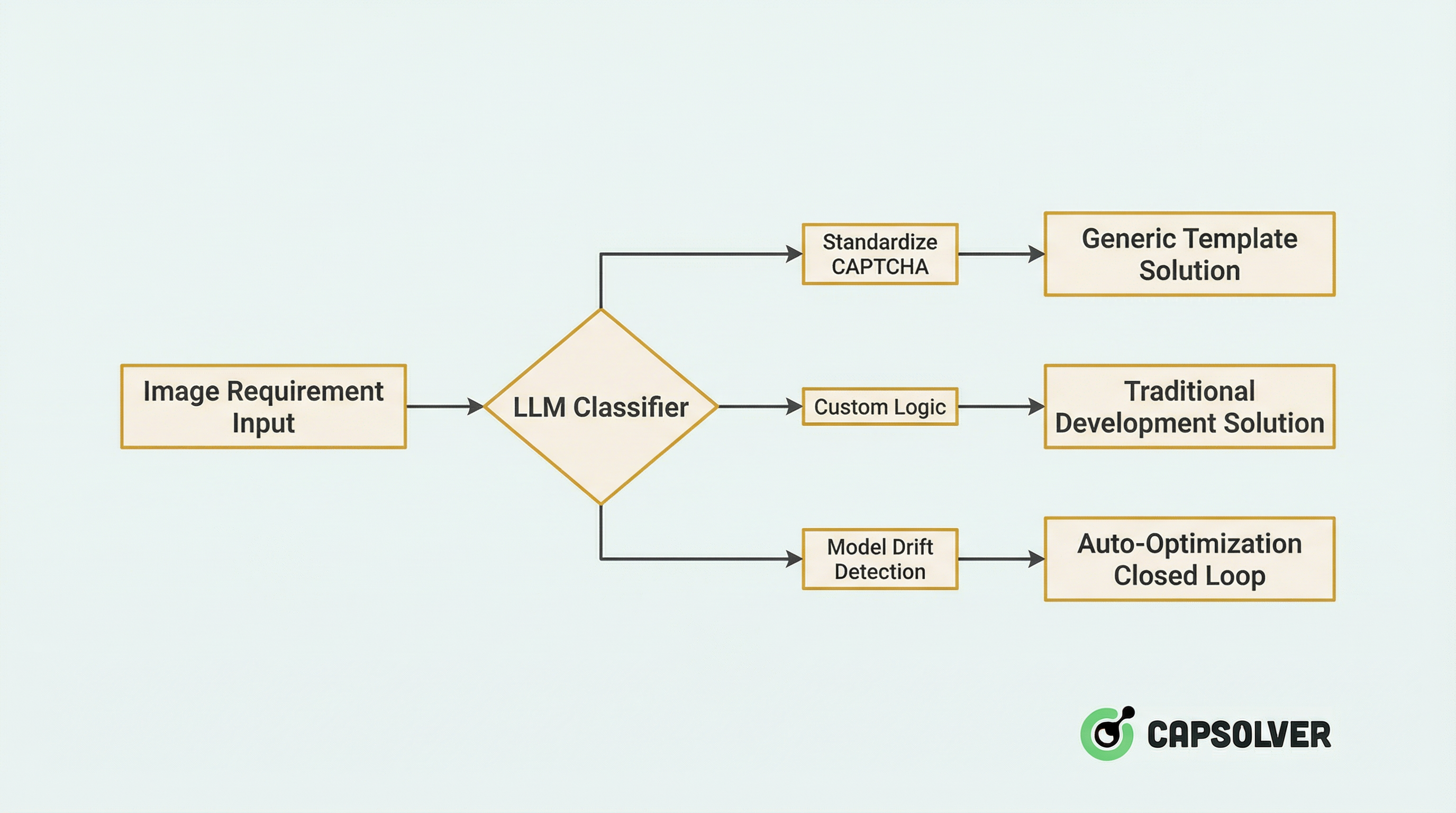
技術的詳細:
- ゼロショット分類:LLMの視覚理解能力を活用して、トレーニングなしでCAPTCHAタイプ(スライダー、クリック選択、回転、ReCaptchaなど)を識別します。
- 信頼度評価:LLMの信頼度が0.8未満の場合、自動的に手動レビュー処理をトリガーし、サンプルを増分トレーニングセットに含めます。
実践データ:プラットフォームにこのルーティングシステムを統合した後、リソース配分効率が47%向上し、誤分類率は12%から2.1%に低下しました。
ステージ2:二軌道開発
分類結果に基づいて、システムは2つの異なる技術軌道に進みます。
トラックA:ローコードトラック(汎用テンプレートによる高速応答)
再CAPTCHAなどの標準化されたCAPTCHAに適用されます:
ユニバーサルテンプレートライブラリ
language
├── LLMプリラベリング:自動的にバウンディングボックスと意味的ラベルを生成
├── 事前トレーニング済みモデル:数百万のサンプルでトレーニングされた汎用検出器
└── LLMポスト処理:意味的補正(例:0/Oや1/lの区別、重複の削除)主なイノベーション—知能ラベリングフライホイール:
- LLMはファーストショット学習を通じて擬似ラベルを生成します。
- 手動レビューで修正された高品質データがトレーニングプールに戻されます。
- ラベリングコストは60%削減され、データ多様性は3倍に増加します。
トラックB:プロコードトラック(深いカスタマイズ開発)
企業向けカスタムCAPTCHA(例:特定のスライダーアルゴリズム、回転角度ロジック)に焦点を当てています:
従来の開発パイプライン
language
├── モデル選択/構成(検出+認識+判断)
├── データ処理:クリーニング → ラベリング → 敵対的サンプル生成(LLM支援:精度テストと新データフィルタリング)
└── 持続的トレーニング:増分学習とドメイン適応をサポートLLMのデータ生成における役割:
- 画像生成:Diffusionモデルを使用して、多様な背景画像とターゲット画像を生成します。
- テキスト生成:LLMは敵対的テキストサンプル(例:歪んだフォント、ぼかし、抽象的に描かれた現実世界のオブジェクトの小さな画像)や指示文(「xxを含む画像をすべてクリックしてください」)を生成します。
- ルール生成と変化:テキストと情報を組み合わせて、GANを介してリアルタイムで画像組み合わせルールやリスク制御検証メカニズムをシミュレートします。
- 検証メカニズム:ViT関連モデルを使用してデータを検証・フィルタリングし、ポジティブサンプルのヒット率を向上させます。
ステージ3:自己進化ループ(フレームワークのコア)
これはアーキテクチャで最も革命的な部分です。AIops → LLM分析 → 自動最適化のパイプラインを通じて、システムは自律的な進化を実現します。
モデルリリース → オンラインサービス → 異常モニタリング → LLM根本原因分析 → 最適化計画の生成 → 自動再トレーニング → キャニーリリース
LLMの6つの主要な判断モジュール:
| 機能モジュール | 具体的な役割 | 事業価値 |
|---|---|---|
| 情報要約 | エラーログを集約し、失敗パターンを特定(例:「夜間のシーンで認識率が低下」) | 大量のログを行動可能なインサイトに変換 |
| 知的判断 | モデル更新のトリガー閾値(例:1時間以上で認識率が5%以上低下)やリスク制御更新のアラート(認識率が即座に30%以上低下)を決定 | 過学習を回避し、GPUコストを節約 |
| プロセスオーケストレーション | データ収集 → ラベリング → トレーニング → テスト → リリースのCI/CDパイプラインを自動的にオーケストレーション | モデルのイテレーションサイクルを数日から数時間に短縮 |
| 自動解決策 | データ拡張戦略を生成(例:ルール生成された背景と新規に生成または収集されたターゲットの結合) | 手動介入なしのデータ準備 |
| 緊急アラート | 新しい攻撃パターン(例:敵対的サンプルの大量生産)を識別し、リスク制御の更新をトリガー | 応答時間は5分未満 |
| タスク配分 | LLM生成のラベリングガイドラインに基づいて、困難なサンプルをラベリングチームに自動的に割り当て | ラベリング効率が40%向上 |
実際の事例:eコマースのクライアントがスライダーCAPTCHAのギャップ検出アルゴリズムを更新した際、従来のシステムでは手動での適応に3〜5日かかりました。LLMベースの閉ループシステムは、異常検出、根本原因分析、データ生成、モデルの微調整を30分以内で完了し、初期の認識率34%から96.8%まで迅速に回復させました。
ステージ4:マルチモーダル実行(ビジネス拡張)
CAPTCHA認識はもはや純粋な画像タスクではなく、視覚、意味、行動を統合した包括的な意思決定プロセスです。新規形式への拡張には時間とコストの制限がなくなりました。
| CAPTCHAタイプ | 視覚的解決 | LLM強化ポイント |
|---|---|---|
| スライダーCAPTCHA | ギャップ検出(YOLO)+画像比較+軌跡シミュレーション | LLMはギャップのテクスチャ特徴を分析し、人間のようなスライド軌跡を生成(ボットとして識別される定常速度の線形運動を回避) |
| クリック選択CAPTCHA | オブジェクト検出+座標位置決め | LLMは意味的指示文(例:「表示されたアイテムと通常一緒に使用されるアイテムにタッチしてください」)を理解し、曖昧な状況での文脈的推論を実現 |
| 回転CAPTCHA | 角度回帰予測 | LLMは視覚的整列基準を判断し、部分的な遮蔽状況を処理 |
| ReCaptcha v3 | 行動バイオメトリック分析 | LLMはマウスの軌跡、クリック間隔、ページスクロールパターンを統合し、人間とボットの判断を実現 |
AIops:自律システムの免疫システム
信頼性あるO&M保証がなければ、最もスマートな意思決定パイプラインも本番環境に導入できません。AIopsレイヤーは4つのコア機能を通じてシステムの安定性を確保します。
1. 異常検出
- モデルドリフトモニタリング:入力データの分布とトレーニングデータの分布をリアルタイムで比較(KS検定)、ドリフトがしきい値を超えるとアラートを発します。
- パフォーマンス低下追跡:成功確率、応答遅延、GPU利用率の3次元メトリクスをモニタリングします。
2. スマートロールバック
新しいモデルバージョンが異常を示した場合、システムは安定したバージョンに自動的にロールバックするだけでなく、LLM分析を通じて障害診断レポートを生成し、原因の可能性を指摘します(例:「新しいサンプルに夜間画像の割合が高いため過学習が発生」)。
3. 弾性リソーススケジューリング
トラフィック予測に基づく自動スケーリング:
- ピークタイム(例:ブラックフライデー):自動的に50GPUインスタンスにスケールアップします。
- ピーク外の時間:5インスタンスにスケールダウンし、コールドデータをオブジェクトストレージに移行します。
- コスト削減は65%に達し、99.99%の可用性を確保します。
4. リスク制御と敵対的防御
- 敵対的サンプル検出:FGSM、PGD攻撃などの敵対的摂動を含むCAPTCHA画像を識別します。
- 行動リスク制御:異常なリクエストパターン(例:単一IPからの高頻度リクエスト)をモニタリングし、人機検証またはIPブロックを自動的にトリガーします。
実装経路:POCから本番への道
このアーキテクチャに基づく実装の推奨は4段階に分けられます:
| 段階 | 持続期間 | 主要なマイルストーン | 成功指標 |
|---|---|---|---|
| 段階1:インフラストラクチャ | 1〜2ヶ月 | AIopsモニタリングのベースライン構築、全リンクの観測性を実現 | MTTR(平均修復時間)<15分 |
| 段階2:統合 | 2〜3ヶ月 | LLMをエラー分析に統合し、自動診断レポートを実現 | 手動分析作業量が70%削減 |
| 段階3:自動化 | 3〜4ヶ月 | 完全な自動トレーニングパイプラインの構築(AutoML+LLM) | モデルイテレーションサイクル<4時間 |
| 段階4:自律性 | 6〜12ヶ月 | LLM駆動の自律的最適化ループを実現 | 手動介入頻度<1回/週 |
課題と対応戦略
課題1:LLMの幻覚による誤判断
対応策:
- RAG(Retrieval-Augmented Generation)アーキテクチャを採用し、決定の基盤を実際の過去ケースのライブラリに固定します。
- 手動承認ノードを設置:モデルロールバックやデータ削除などの高リスク操作は、手動確認が必要です。
課題2:コストの暴走
GPT-4Vの画像分析コストは、従来のCVモデルの50〜100倍です。
対応策:
- レイヤー処理:単純なシナリオでは軽量CVモデル(blip、clip、dinoなど)を使用し、困難なサンプルのみLLMに送信します。
- トークン予算管理:リクエストごとの最大トークン数を設定し、異常入力によるコストの急騰を回避します。
課題3:レイテンシーに敏感なシナリオ
CAPTCHA認識は通常、2秒未満の応答が必要です。
対応策:
- 非同期分析:LLMの最適化提案はリアルタイム認識経路をブロックしない非同期プロセスで生成されます。
- エッジ展開:エッジノードに軽量LLM(例:Qwen3-8b、Llama-3-8B)を展開し、処理時間は500ms未満に保たれます。
結論:ツールからパートナーへの進化
CapSolverのAI-LLMアーキテクチャは、CAPTCHA認識分野における静的ツールから動的エージェントへのパラダイムシフトを示しています。その価値は認識精度の向上だけでなく、自己進化する技術エコシステムの構築にあります:
- 迅速な応答:汎用テンプレートにより、数分単位の適応が可能。
- 深いカスタマイズ:従来の開発が複雑なビジネスロジックをサポート。
- 継続的な進化:LLM駆動の閉ループにより、システムが最新の状態を維持。
"未来のAIシステムは人間によってメンテナンスされるのではなく、人間と協働し自律的に成長するデジタルパートナーとなるでしょう。"
マルチモーダル大規模モデル(例:GPT-4o、Gemini 1.5 Pro)の継続的な進化に伴い、CAPTCHA認識が単なる技術的対立ではなく、AIシステム間の効率的で安全かつ信頼性のある自動化された交渉プロセスとなることを期待できます。
今すぐ試してみましょう!CapSolverで登録する際、コード
CAP26を使用してボーナスクレジットを取得してください!
よくある質問 (FAQ)
Q1: LLMを追加すると認識遅延が増加しますか?
A: 階層的なアーキテクチャ設計により、リアルタイム認識パスは最適化されたCVモデルで処理されます(遅延 < 200ms)。LLMは主にオフライン分析と戦略最適化を担当します。セマンティック理解が必要な複雑なシナリオでは、エッジに配置された軽量LLM(遅延 < 500ms)または非同期処理モードを使用できます。
Q2: LLMによる誤った判断をどう対処しますか?
A: 人間を介在させるメカニズムを実装します:高リスク操作(例:全モデルロールバック、データソース削除)は手動承認が必要です。同時に、すべてのLLM生成最適化プランが本番展開前にA/Bテストで検証されるサンドボックステスト環境を構築します。
Q3: このアーキテクチャは小規模チームに適していますか?
A: はい。段階的な実装を推奨します:初期段階では、大規模モデルを構築せずに、クラウドベースのLLM API(例:Claude 3 Haiku)を異常分析に使用してください。オープンソースツール(LangChain、MLflow)を使用してパイプラインを構築します。ビジネスが成長するにつれて、徐々にプライベート展開とAIopsオートメーションを導入してください。
Q4: 伝統的な純粋CVソリューションと比べてコストはどのようになりますか?
A: 初期投資は約30〜40%増加します(主にLLM API呼び出しとエンジニアリング変換に要する費用)。しかし、自動化による手動O&Mコストの削減は通常、3〜6か月以内に追加投資を相殺します。長期的には、モデルの反復効率の向上と高い自動化率により、トータルコストオブオーナーシップ(TCO)は50%以上削減できます。
コンプライアンス免責事項: このブログで提供される情報は、情報提供のみを目的としています。CapSolverは、すべての適用される法律および規制の遵守に努めています。CapSolverネットワークの不法、詐欺、または悪用の目的での使用は厳格に禁止され、調査されます。私たちのキャプチャ解決ソリューションは、公共データのクローリング中にキャプチャの問題を解決する際に100%のコンプライアンスを確保しながら、ユーザーエクスペリエンスを向上させます。私たちは、サービスの責任ある使用を奨励します。詳細については、サービス利用規約およびプライバシーポリシーをご覧ください。
もっと見る

企業自動化の向上:LLMを駆動とするインフラによるシームレスなCAPTCHA認識と運用効率
LLMを駆動するAIオートメーションインフラがCAPTCHA認識をどのように変革するかを発見してください。ビジネスプロセスの効率を向上させ、手動の介入を削減します。高度な検証ソリューションで自動化されたオペレーションを最適化してください。
Sora Fujimoto
30-Mar-2026

LLMトレーニングのためのデータ収集のスケーリング: CAPTCHAをスケールで解く
大規模言語モデルのトレーニングのためのデータ収集をスケールする方法を学びましょう。大規模にCAPTCHAを解くことで、AIモデル用の高品質なデータセットを構築するための自動化された戦略を発見しましょう。

Anh Tuan
27-Mar-2026

CAPTCHAを解決する方法 OpenBrowserで CapSolverを使用して (AIエージェントオートメーションガイド)
OpenBrowserでCAPTCHAを解くためにCapSolverを使用してください。AIエージェント用にreCAPTCHA、Turnstileなど簡単に自動化します。
Sora Fujimoto
26-Mar-2026

HyperBrowserで任意のCAPTCHAを解く方法: CapSolverを使用したフルセットアップガイド
HyperBrowserで任意のCAPTCHAをCapSolverで解決。reCAPTCHA、Turnstile、AWS WAFなども簡単に自動化できます。
Sora Fujimoto
26-Mar-2026

キャプチャの解決: 価格モニタリング用のAIエージェントのためのステップバイステップガイド
CapSolverを使って、価格モニタリング用AIエージェントのCAPTCHAを効果的に解く方法を学びましょう。このステップバイステップガイドは、途切れることのないデータ収集と強化された市場の洞察を保証します。
Sora Fujimoto
24-Mar-2026

NanoClawとCapSolverを使ってCAPTCHAを自動的に解く方法
CapSolverとNanoClawを使用して、reCAPTCHA、Turnstile、AWS WAF、その他のCAPTCHAを自動で解決するためのステップバイステップガイド。Claude AIエージェント、ゼロコード、および複数のブラウザに対応。

Emma Foster
20-Mar-2026