







AIスクリーパーの代替品 信頼できるウェブデータ自動化のため

Sora Fujimoto
AI Solutions Architect
27-May-2026
TL;DR
- AIスカッパーの代替手段は、インターフェースだけでなく、抽出精度、ブラウザコントロール、APIカバレッジ、コンプライアンス制御、チャレンジ処理の観点から比較されるべきです。
- 最も強力なワークフローは、AI抽出レイヤーと決定論的なクローラー、公式API、モニタリング、および承認済みターゲット向けの制御されたCAPTCHA解決経路を組み合わせたものです。
- ブラウザオートメーションは動的ページに役立ちますが、データを収集する前に、チームはレートリミット、robots.txtのレビュー、権限チェック、明確な停止条件を確保する必要があります。
- CAPTCHAチャレンジは、一部の承認済みウェブスカッピングワークフローにおける信頼性のチェックポイントであり、CapSolverはドキュメント化されたAPIとブラウザ拡張経路を通じてチームをサポートできます。
- チームは、監査ログを保持し、メンテナンス作業を減らし、エンジニアとオペレーターにとって責任ある使用を容易にするツールを選択すべきです。
イントロダクション
AIスカッパーの代替手段はもはや視覚的なノーコードツールだけではありません。現在では、ブラウザエージェント、抽出API、クローラーフレームワーク、および機械学習を価値を追加する場所でのみ使用するハイブリッドワークフローを含んでいます。最適な選択は、許可された公開データを正確に収集し、ワークフローの動作を文書化し、トラフィック検証イベントを責任を持って処理するものです。承認されたオートメーションがCAPTCHAや類似のチャレンジに達した場合、CapSolverのスカッピング中のCAPTCHA解決ガイドは、解決を全体的な戦略ではなく、制御された例外経路として定義するのに役立ちます。このガイドでは、AIファースト、APIファースト、ブラウザファースト、およびハイブリッドオプションを比較し、チームが脆弱なスカッピングパターンを繰り返すことなく信頼性のあるウェブデータオートメーションを構築できるようにします。
AIスカッパーの代替手段とは何か
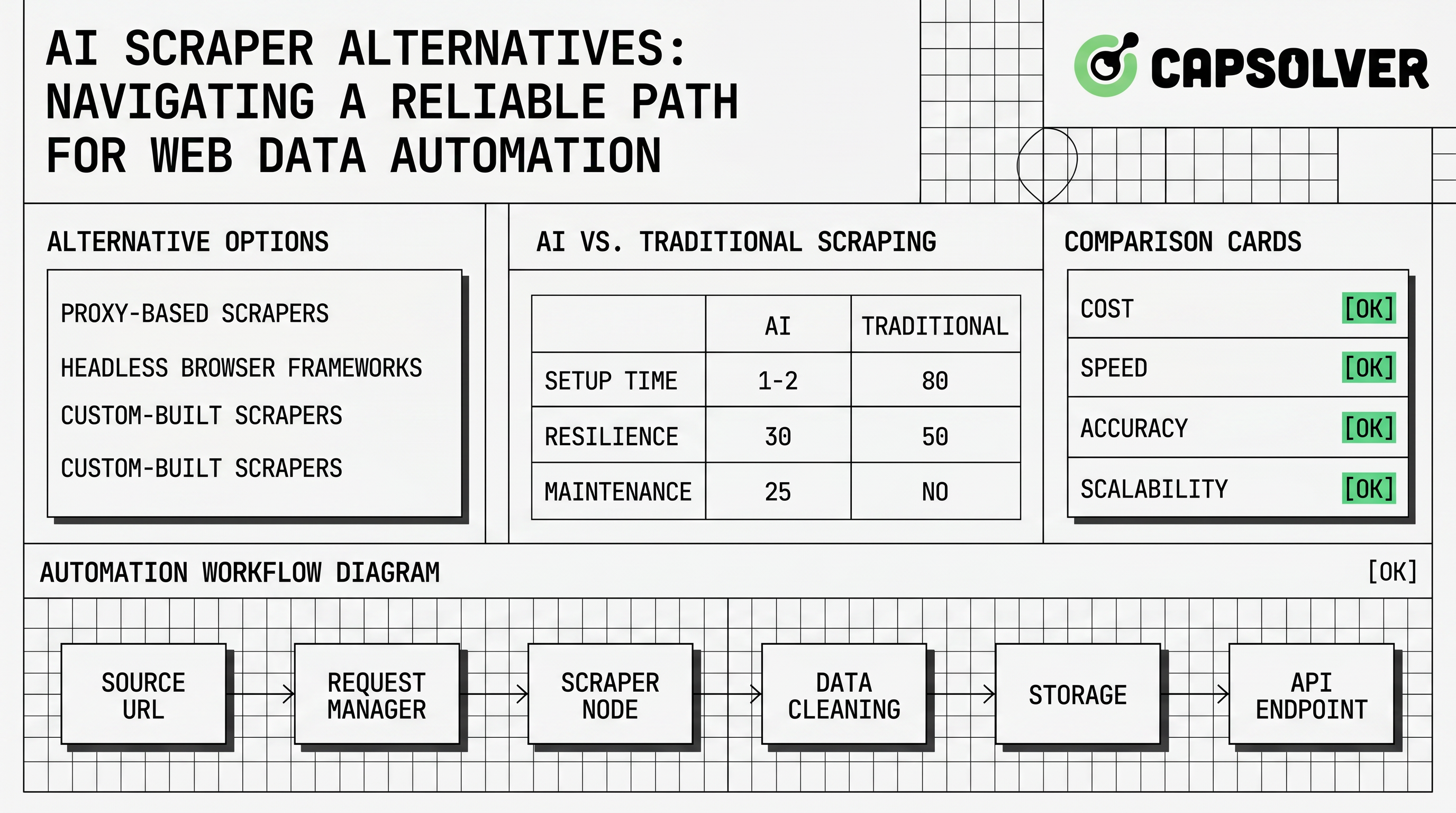
AIスカッパーの代替手段とは、一回限りのセレクターに依存せずに、構造化されたウェブデータを収集するのに役立つツールまたはアーキテクチャです。一部のツールは言語モデルを使用してページからフィールドを推測します。他のツールはマネージドレンダリング、スケジュールドクローリング、プロキシルーティング、または準備済みの抽出APIを提供します。伝統的なフレームワークも依然として関連性があり、ターゲットサイトの構造が安定している場合、決定論的なコードは監査、テスト、保守がより簡単だからです。
市場は広範囲であるため、ウェブページは多様です。製品カタログ、求人ボード、旅行リスト、および公開ディレクトリはすべて、異なるマークアップ、ページネーション、遅延ロード、セッション動作を暴露しています。IBMのAIスカッピング概要では、AIスカッピングをウェブサイトデータ抽出の自動化に使用することを説明しています。Scrapyドキュメンテーションは、構造化抽出用のプログラマブルクローラーフレームワークの反対側を示しています。真剣なチームは通常、両方の概念が必要です。AIはマッピング作業を減らすことができますが、決定論的なコードは運用を予測可能に保ちます。
| 代替タイプ | 最適な用途 | 主な利点 | 管理するリスク |
|---|---|---|---|
| AI抽出ツール | 変化するレイアウトと準構造化ページ | 早いフィールドマッピングと低いセットアップ作業 | 出力のずれと弱い監査可能性 |
| ブラウザオートメーション | ダイナミックアプリケーションとJavaScriptが多めのページ | 実際のページ実行とインタラクションサポート | 高いコスト、タイミングの失敗、チャレンジイベント |
| スカッピングAPI | マネージドレンダリングと運用の単純さ | インフラストラクチャ作業が少ない | ベンダーの縛りとワークフロー制御が少ない |
| クローラーフレームワーク | 安定したページと繰り返しパイプライン | 強いテストとバージョン管理 | 初期のエンジニアリング作業がより多く |
| ハイブリッドスタック | 混在ターゲットを持つプロダクションチーム | フレキシビリティとガバナンスのバランス | 明確な所有権とドキュメンテーションが必要 |
AIスカッパーの代替手段はワークフローのレベルで選択されるべきです。デモで印象的なツールでも、承認の記録、サイトルールの尊重、安全なリトライ、ページの変更時に停止できない場合、失敗する可能性があります。
AIスカッパーの代替手段の評価基準
最初の基準はデータの正確性です。現代的なスカッパーは一貫したフィールドを返し、ソースURLを保持し、不確実性を可視化する必要があります。AIベースの抽出では、出力をサンプルし、人間がレビューした記録と比較し、幻覚フィールドを監視することが必要です。決定論的なクローラーでは、ユニットテスト、セレクターのモニタリング、空または変更されたページの明確な処理が求められます。
2番目の基準は責任あるアクセスです。自動化が始まる前に、チームはrobots.txt、利用規約、APIの利用可能性、レートリミット、契約上の許可をレビューする必要があります。RFC 9309 ロボット排除プロトコルでは、robots.txtを自動クライアントがアクセスルールを識別するプロトコルとして定義しています。MDN URLリファレンスは、チームがコアURLを正規化し、レコードを重複させないときに役立ちます。技術的な能力は、プライベート、機密、制限、または許可されていないデータの収集を許可するものではありません。
3番目の基準はチャレンジ処理です。一部の承認済みターゲットはCAPTCHA、Cloudflare Turnstile、または他のトラフィック検証システムを使用します。その場合、CAPTCHA解決は承認、レートリミット、ロギングの赤字、結果の検証を含む文書化された例外経路として扱われるべきです。CapSolverのCAPTCHA用語集は、ワークフローを設計する前に用語を一致させるのに役立ちます。
CAPTCHA解決がウェブデータオートメーションに適合する場所
CAPTCHA解決はAIスカッパーのアーキテクチャの中心ではありませんが、許可されたオートメーションの信頼性の高いレイヤーとなることがあります。正しいシーケンスは単純です。まず、存在する場合は公式APIまたはデータフィードを優先してください。第二に、ページが静的で許可されている場合、軽量なHTTP抽出を使用してください。第三に、レンダリングまたはインタラクションが必要な場合にのみブラウザオートメーションを使用してください。最後に、ワークフローが承認されており、ページが検証ステップを提示している場合にのみ、制御されたチャレンジ処理経路を追加してください。
このため、CapSolverはワークフローのコンポーネントとして最も適しています。CapSolverのウェブスカッピングFAQは、抽出ワークフローの文脈をチームに提供し、CapSolver Playwright統合ガイドは、チャレンジ処理がブラウザオートメーションにどのように接続できるかを示しています。目的は、すべてのスカッパーをチャレンジ解決サービスを通じて強制することではなく、例外的な経路を一貫性があり、監査可能でテストしやすくすることです。
承認されたオートメーションテストのボーナスコード
CapSolverのボーナスコードを取得する
オートメーション予算を即座に増やす!
CapSolverアカウントにチャージする際にボーナスコード CAP26 を使用すると、すべてのチャージで5%のボーナスが追加されます — 限度はありません。
今すぐCapSolverダッシュボードで取得してください
AIスカッパーの代替手段の実用的なアーキテクチャ
信頼性のあるアーキテクチャは、発見、抽出、検証、保存を分離します。発見は許可されたURLとスケジューリングルールを識別します。抽出は、APIコール、HTTPパーサー、ブラウザオートメーション、またはAI抽出プロンプトなどの、最も低複雑度の方法を使用します。検証はスキーマの完全性、重複レコード、タイムスタンプ、ソース証拠をチェックします。保存は、コンプライアンスチームが収集プロセスをレビューする必要がある場合に、ローカルスナップショットまたはトレースIDを保持します。
動的ページの場合、Playwrightドキュメンテーションなどのブラウザツールが制御されたレンダリングとインタラクションを提供します。クローラーパイプラインの場合、Scrapyなどのフレームワークがスケジューリング、アイテムパイプライン、ミドルウェアを提供します。チャレンジイベントの場合、チームはデバッグ中にCapSolverのブラウザ拡張ガイドを参照し、安定したワークフローをAPIファーストの統合に移動します。これにより、人間の診断が繰り返し可能なプロダクションオートメーションから分離されます。
| ワークフローレイヤー | 推奨されるコントロール | なぜ重要なのか |
|---|---|---|
| 承認レビュー | 承認されたドメインと許可されたデータクラス | 意図した範囲を超えた収集を防止します |
| 抽出 | APIを最優先に、次にHTTP、次にブラウザ、次にAI支援のパース | コストを減らし、不要な複雑さを回避します |
| チャレンジ処理 | 承認されたターゲットの文書化されたCapSolver経路 | CAPTCHAイベントが即興的な手動修正にならないようにします |
| モニタリング | スキーマチェックとページ変更アラート | 不良データがユーザーに届く前にずれを検出します |
| ロギング | 赤字処理されたタスクIDとソース証拠 | 機密値を暴露することなく監査をサポートします |
このアーキテクチャは、チームがAIを使用しない場合の判断にも役立ちます。ページに安定したマークアップと予測可能なページネーションモデルがある場合、決定論的なコードはモデル駆動の抽出器よりも信頼性が高いかもしれません。ソースがドキュメント化されたAPIを提供している場合、そのAPIは通常、スカッピングよりも優先されるべきです。
最適なオプションを選ぶ方法
ページのレイアウトが頻繁に変化し、ビジネス価値がレビューとモニタリングを正当化する場合、AIファーストのスカッパーを選びます。チームがコードを維持でき、繰り返し可能な運用動作が必要な場合、クローラーフレームワークを選びます。インフラストラクチャコストが主なボトルネックの場合、マネージドスカッピングAPIを選びます。サイトがJavaScriptに大きく依存しているか、ユーザーに似たインタラクションが必要な場合、ブラウザオートメーションを選びます。承認されたワークフローがサポートされているCAPTCHAまたはトラフィック検証チャレンジに達した場合、チームが一貫した解決経路が必要な場合、CapSolverを選びます。
セキュリティとコンプライアンスチームは早期に関与する必要があります。OWASP Automated Threats projectは、一般的な悪用される自動化パターンを説明しており、責任あるシステムが避けるべきものとして役立ちます。責任あるスカッパーは、適切なタイミングで自分自身を識別し、制限を守り、機密データを避け、認証またはページ動作が不明な場合に停止する必要があります。
結論
AIスカッパーの代替手段は、ツールだけでなく、運用モデルとして評価されるべきです。最も強力なチームは、公式API、決定論的なクローラー、ブラウザオートメーション、AI抽出、モニタリング、およびCAPTCHAチャレンジの文書化された例外経路を組み合わせます。承認されたウェブデータワークフローがアーキテクチャの一部として信頼性のあるチャレンジ処理を必要とする場合、CapSolverのコンプライアンスウェブスカッピングガイドは実用的な参考資料であり、CAPTCHA処理が責任ある自動化ガバナンスにどのように適合するかを説明しています。
FAQ
AIスカッパーの代替手段とは何ですか?
AIスカッパーの代替手段は、AI抽出ツール、ブラウザオートメーション、スカッピングAPI、クローラーフレームワーク、およびハイブリッドシステムを含む、ウェブデータ抽出のためのツールまたはアーキテクチャです。
チームがスカッピングでブラウザオートメーションを使用すべきタイミングはいつですか?
許可されたターゲットページがJavaScriptのレンダリング、ユーザーに似たインタラクション、または単純なHTTPリクエストでは信頼性が保証されていないポストロードデータ抽出を必要とする場合に使用してください。
すべてのAIスカッパーにCAPTCHA解決が必要ですか?
いいえ。CAPTCHA解決は、承認されたワークフローがサポートされているチャレンジに遭遇した場合にのみ関係があります。多くのウェブスカッピングタスクでは、公式API、静的抽出、またはデータパートナーシップを使用すべきです。
CapSolverはAIスカッパーの代替手段をどのようにサポートできますか?
CapSolverは、QA、モニタリング、およびブラウザオートメーションで、文書化されたAPIまたはブラウザ拡張経路を通じて承認されたワークフローをサポートできます。
最も安全な開始方法は何ですか?
権限レビュー、robots.txtレビュー、および小さなパイロットから始めます。その後、API、クローラー、ブラウザ、およびAI抽出オプションを比較し、明確に正当化された場所でCAPTCHAチャレンジ処理を追加します。
コンプライアンス免責事項: このブログで提供される情報は、情報提供のみを目的としています。CapSolverは、すべての適用される法律および規制の遵守に努めています。CapSolverネットワークの不法、詐欺、または悪用の目的での使用は厳格に禁止され、調査されます。私たちのキャプチャ解決ソリューションは、公共データのクローリング中にキャプチャの問題を解決する際に100%のコンプライアンスを確保しながら、ユーザーエクスペリエンスを向上させます。私たちは、サービスの責任ある使用を奨励します。詳細については、サービス利用規約およびプライバシーポリシーをご覧ください。
もっと見る
採用自動化とCAPTCHAの解決: 2026年版の検証ガイド – 採用スタック全体にわたる
採用自動化は求人掲載、候補者の確保、および選考をカバーし、各段階でCAPTCHAに遭遇する可能性があります。検証の煩雑さが発生する場所、プラットフォームがそれをトリガーする理由、およびコードを使用してコンプライアンスに沿って解決する方法を確認してください。
Sora Fujimoto
10-Jun-2026
なぜブラウザ使用エージェントが常にブロックされるのか
ブラウザのユーザーエージェントは、ネットワーク、ブラウザ、および行動レイヤーでトラフィックが自動化されているとブロックされ続けます。自動化を維持するための4つの本当の原因と修正方法を学びましょう。
Sora Fujimoto
04-Jun-2026
Puppeteerがボットとして検出されましたか? 修正方法は?
Puppeteerがボットと検出される?その修正方法は一般的な質問です。多くのオートメーションプロジェクトは動作するローカルスクリプトから始まり、その後リアルなウェブサイトで失敗するからです。問題はたいてい1つの設定に起因するわけではありません。ウェブサイトはしばしばブラウザのプロパティ、リクエストの履歴...
Sora Fujimoto
04-Jun-2026

なぜ私のPlaywrightボットが検出されるのですか?
なぜ私のPlaywrightボットが検出されるのでしょうか?簡潔な答えは、目的のウェブサイトがPlaywrightだけを判断しているわけではないということです。それは、ブラウザの状態、JavaScriptで表示可能なプロパティ、TLSおよびネットワークの動作、セッションの履歴...などを含む完全なトラフィックプロファイルを評価しています。
Sora Fujimoto
04-Jun-2026
AIスクリーパーの代替品 信頼できるウェブデータ自動化のため
CapSolverで、コンプライアンスに準拠したデータ抽出、ブラウザのオートメーション、APIファーストのワークフロー、CAPTCHAの対処などのAIスクリーパーの代替ソリューションを比較してください。
Sora Fujimoto
27-May-2026