







Web Scraping no Node.js: Usando Node Unblocker e CapSolver

Emma Foster
Machine Learning Engineer
26-Jan-2026
TL;Dr
- Web scraping em Node.js enfrenta desafios crescentes de detecção de bots e CAPTCHAs.
- Node Unblocker lida efetivamente com medidas básicas de anti-scraping, como bloqueio de IP e restrições geográficas, atuando como middleware de proxy.
- CapSolver é essencial para superar desafios avançados, especificamente CAPTCHAs, que o Node Unblocker não pode resolver sozinho.
- Combinar o Node Unblocker com CapSolver cria uma solução robusta e eficiente para web scraping em Node.js.
- A integração adequada dessas ferramentas garante a extração confiável de dados de sites complexos.
Introdução
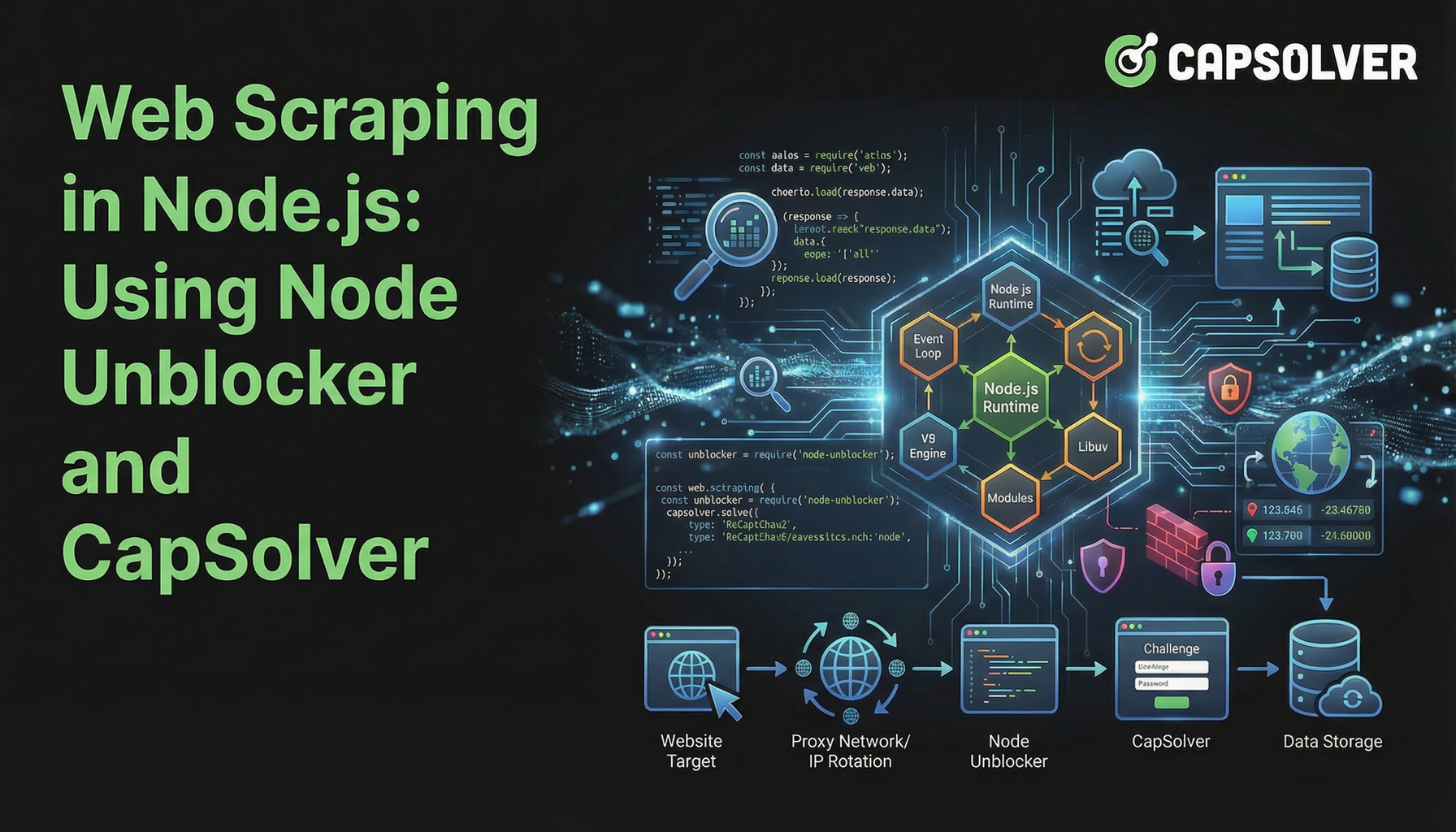
Web scraping em Node.js tornou-se uma técnica poderosa para coleta de dados, mas frequentemente enfrenta obstáculos significativos. Os sites estão cada vez mais implementando defesas avançadas para impedir o acesso automatizado, tornando a extração de dados um processo complexo. Este artigo explora como melhorar seus projetos de web scraping em Node.js combinando o Node Unblocker, um middleware de proxy versátil, com o CapSolver, um serviço especializado em resolução de CAPTCHAs. Guiaremos você através da construção de uma infraestrutura de scraping resistente que pode navegar pelas restrições comuns da web e garantir fluxo constante de dados. Este guia é para desenvolvedores que buscam métodos eficientes e confiáveis para web scraping em Node.js no ambiente online desafiador de 2026.
Compreendendo o Cenário dos Desafios de Web Scraping
Sites modernos utilizam várias técnicas para desencorajar esforços de scraping automatizados. Essas defesas variam de bloqueio de IP simples a desafios interativos complexos. Realizar web scraping em Node.js com sucesso requer compreender e abordar esses obstáculos.
Desafios comuns incluem:
- Bloqueio baseado em IP: Sites detectam e bloqueiam solicitações originadas de endereços IP suspeitos, frequentemente associados a centros de dados ou atividades conhecidas de scraping.
- Limitação de taxa: Servidores restringem o número de solicitações de um único IP em um determinado período, resultando em bloqueios temporários ou erros.
- Restrições geográficas: A disponibilidade de conteúdo varia conforme a localização geográfica, impedindo o acesso a certos dados de determinadas regiões.
- CAPTCHAs: São projetados para distinguir usuários humanos de bots, apresentando enigmas visuais ou interativos que são difíceis para scripts automatizados resolver.
- Conteúdo dinâmico: Sites que renderizam conteúdo com JavaScript exigem que os scrapers executem JavaScript, adicionando complexidade.
- Gerenciamento de sessão: Manter o estado da sessão e lidar corretamente com cookies é crucial para navegar em seções autenticadas de sites.
Esses desafios destacam a necessidade de ferramentas sofisticadas além de bibliotecas básicas de solicitação HTTP ao realizar scraping sério em Node.js.
Node Unblocker: A Base para Scraping Resiliente
Node Unblocker é um middleware de código aberto em Node.js projetado para facilitar web scraping em Node.js contornando restrições comuns da web. Ele atua como um proxy, direcionando suas solicitações por meio de um servidor intermediário, ocultando assim seu endereço IP real e potencialmente contornando restrições geográficas. Sua principal força está na capacidade de modificar cabeçalhos de solicitação e resposta, lidar com cookies e gerenciar sessões, tornando-o um recurso valioso para camadas iniciais de defesa.
Principais Vantagens do Node Unblocker:
- Máscara de IP: Direciona o tráfego por meio de um proxy, ocultando o IP real do seu scraper. Isso ajuda a evitar bloqueios baseados em IP.
- Contornando restrições geográficas: Usando proxies localizados em diferentes regiões, você pode acessar conteúdo restrito geograficamente.
- Gerenciamento de cabeçalhos: Permite modificar facilmente cabeçalhos HTTP, como User-Agent, Referer e Accept-Language, para imitar solicitações de navegadores legítimos.
- Gerenciamento de cookies: Gerencia automaticamente cookies, essencial para manter o estado da sessão entre várias solicitações.
- Integração de middleware: Projetado para integrar-se facilmente com frameworks populares de Node.js como Express.js, simplificando a instalação e o uso.
- Flexibilidade de código aberto: Como código aberto, oferece controle total e opções de personalização para desenvolvedores adaptarem-no às necessidades específicas de scraping.
Configurando o Node Unblocker para Web Scraping em Node.js
Integrar o Node Unblocker ao seu projeto de web scraping em Node.js é simples. Primeiro, certifique-se de que Node.js e npm estão instalados. Em seguida, você pode instalar o Node Unblocker e o Express.js:
bash
npm init -y
npm install express unblockerEm seguida, crie um arquivo index.js e configure o Node Unblocker como middleware:
javascript
const express = require("express");
const Unblocker = require("unblocker");
const app = express();
const unblocker = new Unblocker({ prefix: "/proxy/" });
app.use(unblocker);
const port = 3000;
app.listen(port).on("upgrade", unblocker.onUpgrade);
console.log(`Proxy rodando em http://localhost:${port}/proxy/`);Esta configuração básica cria um servidor de proxy local. Você pode então direcionar suas solicitações de scraping para http://localhost:3000/proxy/ seguido pela URL alvo. Para configurações mais detalhadas, consulte o repositório GitHub do Node Unblocker.
A Peça que Faltava: Resolvendo CAPTCHAs com CapSolver
Embora o Node Unblocker se destaque no tratamento de restrições de nível de rede, ele não aborda desafios como CAPTCHAs. Esses enigmas visuais ou interativos são especificamente projetados para diferenciar usuários humanos de bots. Quando seu web scraping em Node.js encontrar um CAPTCHA, o processo de scraping para.
É aí que CapSolver se torna uma ferramenta indispensável. CapSolver é um serviço especializado em resolução de CAPTCHAs que fornece uma API para resolver programaticamente diversos tipos de CAPTCHAs, incluindo reCAPTCHA v2, reCAPTCHA v3 e Cloudflare Turnstile. Integrar o CapSolver ao seu fluxo de web scraping em Node.js permite que seu scraper resolva automaticamente esses passos de verificação humana, garantindo coleta ininterrupta de dados.
Use o código
CAP26ao se inscrever no CapSolver para receber créditos extras!
Como o CapSolver Melhora o Web Scraping em Node.js:
- Resolução automática de CAPTCHAs: Resolve CAPTCHAs complexos sem intervenção manual.
- Ampla suporte a CAPTCHAs: Gerencia diversos tipos de CAPTCHAs, oferecendo uma solução abrangente.
- Integração de API: Fornece uma API simples para integração fácil em projetos existentes em Node.js.
- Confiabilidade: Oferece altas taxas de sucesso na resolução de CAPTCHAs, minimizando interrupções.
- Velocidade: Entrega soluções rápidas de CAPTCHA, mantendo a eficiência das suas operações de scraping.
Integrando o CapSolver ao Seu Scraper em Node.js
Para integrar o CapSolver, você normalmente faria uma chamada de API ao CapSolver sempre que um CAPTCHA fosse detectado. O processo envolve enviar os detalhes do CAPTCHA ao CapSolver, receber a solução e depois submeter essa solução de volta ao site alvo. Isso pode ser feito usando um cliente HTTP como Axios em sua aplicação Node.js.
Por exemplo, após configurar seu proxy do Node Unblocker, sua lógica de scraping incluiria uma verificação para CAPTCHAs. Se um for encontrado, você iniciaria uma chamada ao CapSolver. Você pode encontrar exemplos detalhados e documentação sobre como integrar o CapSolver para diversos tipos de CAPTCHA em nossos artigos, como Como resolver reCAPTCHA com Node.js e Como resolver CAPTCHA Cloudflare Turnstile com NodeJS.
Comparação: Node Unblocker Sozinho vs. Node Unblocker + CapSolver
Entender os papéis distintos do Node Unblocker e do CapSolver é crucial para um web scraping eficaz em Node.js. Embora o Node Unblocker forneça capacidades básicas de proxy, o CapSolver aborda um desafio específico e avançado.
| Funcionalidade/Ferramenta | Node Unblocker Sozinho | Node Unblocker + CapSolver |
|---|---|---|
| Máscara de IP | Sim | Sim |
| Contornando restrições geográficas | Sim | Sim |
| Gerenciamento de cabeçalho/cookie | Sim | Sim |
| Resolução de CAPTCHA | Não | Sim |
| Detecção de bot (básica) | Parcial (via máscara de IP/cabeçalho) | Melhorada (resolve CAPTCHAs, reduzindo o score de bot) |
| Complexidade da instalação | Moderada | Moderada a Alta (requer integração de API do CapSolver) |
| Custo | Grátis (open-source) | Grátis (open-source) + taxas do serviço CapSolver |
| Confiabilidade para sites complexos | Limitada | Alta |
| Caso de uso ideal | Sites simples, coleta básica de dados, testes iniciais | Sites complexos com CAPTCHAs, extração de dados em larga escala, ambientes de produção |
Essa comparação mostra claramente que, para um web scraping robusto em Node.js contra defesas modernas da web, uma abordagem combinada é superior. O Node Unblocker lida com o roteamento e a evasão básica, enquanto o CapSolver fornece a inteligência para superar CAPTCHAs.
Estratégias Avançadas para Web Scraping em Node.js
Além de apenas usar o Node Unblocker e o CapSolver, várias estratégias avançadas podem melhorar ainda mais seus projetos de web scraping em Node.js. Essas técnicas focam em imitar comportamentos humanos e gerenciar recursos de forma eficiente.
- Rotação de User-Agent: Alterar regularmente o cabeçalho User-Agent ajuda a evitar detecção. Um conjunto diverso de User-Agents faz suas solicitações parecerem vir de navegadores e dispositivos diferentes. Saiba mais sobre gerenciamento de User-Agent em nosso artigo sobre Melhores User-Agent.
- Atraso e randomização de solicitações: Introduzir atrasos aleatórios entre solicitações evita que seu scraper atinja limites de taxa. Os padrões de navegação humana raramente são perfeitamente consistentes.
- Navegadores headless: Para sites que dependem fortemente de JavaScript, usar navegadores headless como Puppeteer ou Playwright é essencial. Essas ferramentas podem executar JavaScript e renderizar páginas como um navegador real. Você pode integrar o CapSolver a essas ferramentas; veja nossos guias sobre Como Integrar Puppeteer e Como Integrar Playwright.
- Rotação de proxies: Embora o Node Unblocker forneça uma camada de proxy única, alternar entre um grupo de proxies diferentes (residenciais, móveis) pode reduzir significativamente as chances de bloqueio de IP. Isso é especialmente importante para operações de web scraping em larga escala em Node.js.
- Tratamento de erros e repetições: Implementar tratamento robusto de erros com mecanismos de repetição para solicitações falhas. Isso torna seu scraper mais resistente a problemas de rede temporários ou bloqueios leves.
Combinando essas estratégias com o Node Unblocker e o CapSolver, você constrói uma solução de web scraping em Node.js altamente sofisticada e eficaz. Para mais dicas gerais sobre evitar detecção, consulte nosso artigo sobre Evitando Banimentos de IP.
Conclusão
O web scraping eficaz em Node.js em 2026 exige uma abordagem multifacetada para superar defesas da web cada vez mais complexas. O Node Unblocker fornece uma base robusta e de código aberto para gerenciar conexões de proxy, mascarar IPs e lidar com intricidades básicas de HTTP. No entanto, para os obstáculos mais desafiadores, particularmente CAPTCHAs, um serviço especializado como o CapSolver é indispensável. A sinergia entre o Node Unblocker e CapSolver cria uma infraestrutura de scraping poderosa e confiável, permitindo que desenvolvedores extraiam dados de forma consistente e eficiente.
Ao integrar essas ferramentas e adotar estratégias avançadas de scraping, você pode construir aplicações de web scraping em Node.js resistentes que suportem mecanismos modernos de detecção de bots. Equipar seus projetos com a combinação certa de ferramentas garante que seus esforços de coleta de dados sejam bem-sucedidos e sustentáveis.
Perguntas Frequentes (FAQ)
Q: Para que serve o Node Unblocker no scraping?
A: O Node Unblocker é principalmente usado como middleware de proxy no web scraping em Node.js para mascarar o IP do scraper, contornar restrições geográficas e gerenciar cabeçalhos HTTP e cookies. Ele ajuda a contornar medidas básicas de anti-scraping e a tornar as solicitações parecerem mais legítimas.
Q: O Node Unblocker pode resolver CAPTCHAs?
A: Não, o Node Unblocker por si só não pode resolver CAPTCHAs. Sua funcionalidade está focada em proxy de nível de rede e modificação de solicitações. Para resolver CAPTCHAs encontrados durante o web scraping em Node.js, você precisa integrar um serviço especializado de resolução de CAPTCHA, como o CapSolver.
Q: Por que usar o CapSolver com o Node Unblocker?
A: Você deve usar o CapSolver com o Node Unblocker para criar uma solução completa de web scraping em Node.js. O Node Unblocker lida com máscara de IP e evasão básica, enquanto o CapSolver fornece a capacidade crucial de resolver CAPTCHAs automaticamente, que são um obstáculo comum para scrapers automatizados em sites protegidos.
Q: Existem alternativas ao Node Unblocker para gerenciamento de proxy?
A: Sim, existem várias alternativas para gerenciamento de proxy no web scraping em Node.js, incluindo scripts de rotação de proxy personalizados, serviços comerciais de proxy ou outras bibliotecas de código aberto. No entanto, o Node Unblocker oferece uma abordagem conveniente de middleware para aplicações em Express.js.
Q: Quais são as considerações legais para web scraping?
A: As considerações legais para web scraping em Node.js incluem respeitar os arquivos robots.txt, seguir os termos de serviço do site e cumprir regulamentações de proteção de dados como GDPR ou CCPA. Sempre certifique-se de que suas atividades de scraping sejam éticas e legais.
Declaração de Conformidade: As informações fornecidas neste blog são apenas para fins informativos. A CapSolver está comprometida em cumprir todas as leis e regulamentos aplicáveis. O uso da rede CapSolver para atividades ilegais, fraudulentas ou abusivas é estritamente proibido e será investigado. Nossas soluções de resolução de captcha melhoram a experiência do usuário enquanto garantem 100% de conformidade ao ajudar a resolver dificuldades de captcha durante a coleta de dados públicos. Incentivamos o uso responsável de nossos serviços. Para mais informações, visite nossos Termos de Serviço e Política de Privacidade.
Mais
Arquitetura de Web Scraping em Rust para Extração de Dados Escalável
Aprenda arquitetura de raspagem web escalável em Rust com reqwest, scraper, raspagem assíncrona, raspagem de navegador headless, rotação de proxies e tratamento de CAPTCHA compatível.

Adélia Cruz
22-Apr-2026

Selenium vs Puppeteer para Resolução de CAPTCHA: Comparação de Desempenho e Caso de Uso
Compare o Selenium vs Puppeteer para resolver CAPTCHA. Descubra benchmarks de desempenho, notas de estabilidade e como integrar o CapSolver para o máximo de sucesso.

Ethan Collins
08-Apr-2026

Dados como Serviço (DaaS): O que é e por que importa em 2026
Entenda Dados como Serviço (DaaS) em 2026. Descubra seus benefícios, casos de uso e como transforma os negócios com visões em tempo real e escalabilidade.
Ethan Collins
12-Feb-2026

Como corrigir erros comuns de raspagem da web em 2026
Dominar a correção de diversos erros de raspagem de web, como 400, 401, 402, 403, 429, 5xx e 1001 do Cloudflare em 2026. Aprenda estratégias avançadas para rotação de IPs, cabeçalhos e limitação de taxa adaptativa com o CapSolver.

Rajinder Singh
05-Feb-2026

Como resolver Captcha no RoxyBrowser com integração do CapSolver
Integre o CapSolver com o RoxyBrowser para automatizar tarefas do navegador e contornar o reCAPTCHA, o Turnstile e outros CAPTCHAS.
Adélia Cruz
04-Feb-2026

Como resolver Captcha no EasySpider com integração do CapSolver
EasySpider é uma ferramenta de raspagem de web e automação do navegador visual e sem código, e quando combinado com o CapSolver, pode resolver de forma confiável CAPTCHAs como reCAPTCHA v2 e Cloudflare Turnstile, permitindo a extração de dados automatizada sem interrupções em sites.
Adélia Cruz
04-Feb-2026