







赋能企业自动化:大模型驱动的验证码识别基础设施,实现无缝业务流程与高效运营

Lucas Mitchell
Automation Engineer
27-Mar-2026

在数字化转型飞速发展的今天,验证码已从简单的“准入工具”演变为复杂的业务流程过滤器。尽管它们对安全性至关重要,却常常带来显著的摩擦,在自动化工作流中制造“效率鸿沟”。据估计,全球企业每天因验证码拦截而花费在人工处理上的时间累计高达 50 万小时,严重阻碍了关键业务操作的无缝执行。
这种人工干预导致了多重挑战:
- 高昂的运营成本: 依赖人工处理验证码,难以随着业务量的增长而有效扩展。
- 流程中断: 自动化脚本在遇到验证码时频繁中断,影响了整体业务链条的连续性。
- 隐私与技术压力: 随着隐私法规的不断收紧,传统的基于行为追踪的验证方法面临严峻挑战,亟需更透明、更高效的解决方案。
我们的愿景: 我们坚信验证码应赋能而非阻碍业务增长。通过提供尖端的 AI 自动化基础设施,实现自动化验证码识别,我们致力于帮助企业显著减少人工干预,优化运营成本,并提升核心业务流程的生态效率。
📈 一、验证技术演进:从规则驱动到智能协同
过去 25 年的验证技术发展历程,反映了安全与用户体验之间持续的平衡追求。大模型(LLM)的出现标志着一个关键的转折点,开启了智能、协同处理的新时代。
| 阶段 | 核心技术 | 处理逻辑 | 业务影响 |
|---|---|---|---|
| V1 (2000s) | 扭曲字符 | 简单 OCR 识别 | 易受基础自动化攻击,初期效率高 |
| V2 (2014s) | 图像点选 | 目标检测与分类 | 需要大量人工标注,运营成本增加 |
| V3 (2024s) | 行为分析 | 风险评分与指纹 | 面临隐私争议,难以高效自动化 |
| V4 (2026+) | LLM 协同 | 语义理解与生成 | 高可靠性、增强效率、全面自动化 |
关键洞察: 随着验证码向语义化、多模态方向发展,传统的基于规则或硬编码的解决方案已显不足。企业需要一种具备高级语义理解能力的智能基础设施,以满足其自动化需求。这正是 LLM 验证码变得不可或缺的原因。
🧠 二、LLM 赋能:自动化基础设施的核心能力
将大模型整合到验证处理生态系统中,使其不再仅仅是“破解工具”,而是驱动业务流程效率的智能引擎。
2.1 核心能力一:智能风险决策引擎
传统的自动化通常依赖僵化的 if-else 规则来处理验证码,导致系统碎片化、难以维护且易被绕过。LLM 驱动基础设施充当智能风险决策引擎,整合多种信号,实现统一、自适应和可解释的处理。
传统方法(基于规则):
python
# 传统方式
if ip_risk > 0.8 and device_new == True:
captcha_type = "hard"
elif behavior_score < 0.5:
captcha_type = "medium"
else:
captcha_type = "none"LLM 驱动方法(上下文决策):
python
# LLM 方式
context = {
"ip_reputation": "medium",
"device_fingerprint": "new_device",
"behavior_score": 0.65,
"request_frequency": "high",
"geo_location": "anomalous",
"historical_pattern": "deviation_detected"
}
# LLM 输出:{"risk_level": "high", "captcha_type": "semantic_image",
# "difficulty": 0.8, "reason": "设备指纹与新 IP 地理位置冲突"}价值主张:
- ✅ 降低误杀率 (20%+): 最大限度地减少对合法用户的干扰,提升用户体验。
- ✅ 可解释决策: 为安全运营提供可审计的洞察,实现持续优化。
- 动态适应性: 自动适应不断变化的验证挑战和业务需求。
2.2 核心能力二:生成式验证引擎
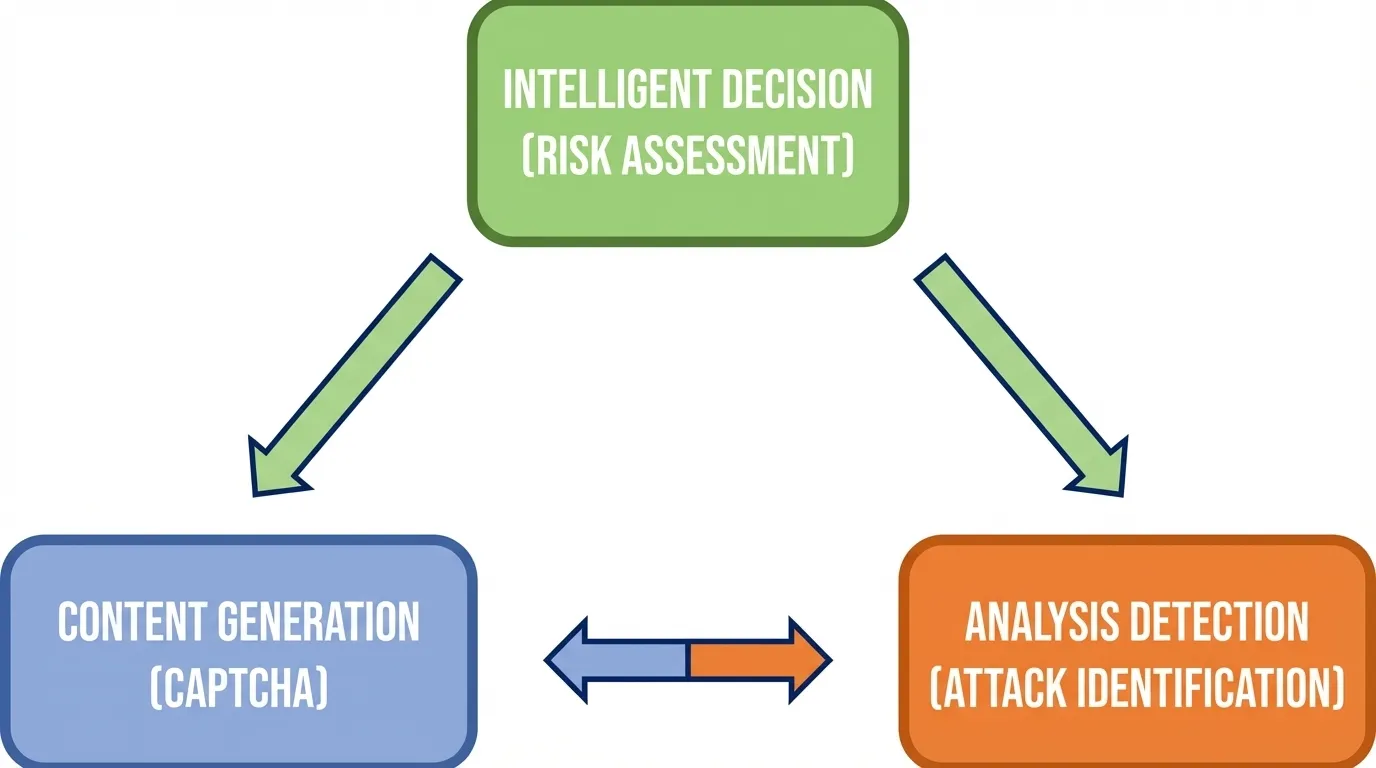
传统的验证码依赖有限的题库,使其容易被复杂的自动化系统进行离线训练和破解。利用生成式 AI,包括 Diffusion 模型,创建独特、动态的验证挑战。每个实例都是独一无二的创作,显著增加了任何预训练自动化尝试的成本与复杂性。
核心原则: 确保非授权自动化的泛化成本超过绕过验证的潜在收益。
2.3 核心能力三:深度行为序列分析
虽然传统的行为分析可能会标记简单的模式(例如,直线鼠标移动被视为机器人),但 LLM 可以执行深度行为序列分析。通过将用户操作序列向量化并通过 Transformer 模型处理,可以从过于完美的自动化脚本中辨别出微妙的人类行为细微差别。
行为序列分析流程:
这使得系统能够区分“犹豫的真实用户”和“完美的自动化脚本”,基于真实交互中固有的“人性瑕疵”。
🗺️ 三、战略优势:利用 LLM 优化自动化成本
有效自动化的本质并非绝对阻止,而是使非授权绕过在经济上不可行。LLM 扩大了这种成本不对称性,使合法自动化更高效,而非授权自动化成本高昂得令人望而却步。
成本对比:非授权自动化 vs. 智能基础设施
| 成本因素 | 非授权自动化 | 智能基础设施 |
|---|---|---|
| 数据收集 | 高 (用于训练) | 低 (行为数据采集) |
| 模型训练 | 高 (迭代训练) | 中 (生成模型部署) |
| 对抗样本生成 | 高 | 不适用 |
| 有效性寿命 | 低 (验证码很快失效) | 高 (动态策略更新) |
| 检测风险 | 高 | 低 |
| 误杀处理 | 不适用 | 中 (申诉处理) |
结论: 非授权自动化的运营成本远高于维护 LLM 驱动基础设施的可持续成本,确保了长期、稳健的自动化。
LLM 如何增强成本优化:
- 增加泛化成本: 生成式验证码创造无限视觉空间,阻止预训练模型。
- 增加推理成本: 语义验证码需要多步推理,消耗非授权尝试的大量计算资源。
- 缩短生命周期: 缩短验证码有效期,使破解方案在广泛部署前即失效。
- 数据污染: 动态混淆真实流量与蜜罐流量,污染非授权自动化的训练数据集。
🚀 四、未来展望:构建无缝、基于信任的自动化生态系统
我们设想的未来是,验证是一个无形、持续的过程,无缝集成到用户体验中。
4.1 阶段一:LLM 作为“效率副驾驶”(当前 - 近未来)
在此初始阶段,LLM 充当智能助手,提升安全运营效率,而非直接做出关键决策。它们处理复杂的验证逻辑,显著减少人工干预频率,并为人类专家提供可操作的洞察。
核心原则: LLM 充当副驾驶,增强人类专业知识以提高运营效率。
4.2 阶段二:动态生成式验证(近未来 - 中期)
此阶段将 LLM 与生成模型(如 Diffusion 模型)结合,创建无法预训练的验证码。每个验证实例都是独一无二的,确保任何成功绕过一个实例对后续尝试都没有帮助。验证从“题库抽取”模式转变为“实时创作”。
未来验证码示例:
用户访问页面 → LLM 理解页面内容 → 生成语义相关的验证问题。
- “这篇文章提到了 3 个城市,请在地图上标出它们的位置。”
这需要理解文章内容、地理知识和图像交互,使得自动化绕过成本极高,同时对人类用户来说仍然易于管理。
4.3 阶段三:持续信任引擎(中期 - 远未来)
最终目标是显式验证码的“消失”,取而代之的是持续的后台信任评估。用户不再感知到验证步骤,因为系统会根据实时行为信号持续评估信任。
2030 年验证体验设想:
用户打开应用 → 后台持续收集行为信号 → LLM 计算实时信任分数。
- 信任分数 > 阈值: 所有操作无缝进行。
- 信任分数 < 阈值: 某些功能静默降级。
- 信任分数 << 阈值: 触发显式验证或干预。
用户将无需点击“我不是机器人”,实现真正无缝高效的体验。
4.4 超越:开创 AI 原生验证的未来
我们还在探索更高级的概念,例如“AI 专用验证码”——旨在区分人类辅助的 AI(例如,使用 AI 助手的用户)和纯自动化脚本。随着 AI 助手的普及,这种区分对于维护公平和安全的数字交互至关重要。
⚠️ 五、伦理与负责任的 AI 实施
尽管 LLM 为效率带来了前所未有的机遇,我们仍强调负责任的 AI 实施方法,优先考虑透明度和伦理考量:
关键考量:
- 数据隐私: 确保所有数据收集和处理符合全球隐私保护标准。
- 偏见缓解: 持续监控和缓解 LLM 驱动决策中潜在的偏见,确保公平性。
- 透明度与可解释性: 提供关于 LLM 如何做出验证决策的清晰洞察,尤其是在用户遇到摩擦的情况下。
- 人机协同: 在复杂或模糊场景中保持人工监督和干预机制。
核心原则: AI 驱动决策为主,辅以基于规则的备用方案和人机协作,确保稳健和道德的运营。
💡 六、企业行动策略:立即拥抱智能自动化
为了利用 LLM 驱动自动化的力量,企业可以采取以下策略:
- 📊 评估现状: 评估现有验证系统对开源 OCR/检测模型的脆弱性,并分析误杀率、用户投诉率和自动化成功率等关键指标。
- 🧪 试点与迭代: 从低风险业务线开始试点“无缝验证”或“动态难度”解决方案。建立 A/B 测试框架,量化新策略的影响。
- 📚 保持领先: 关注生成式 AI(例如 Diffusion 模型)和多模态 LLM 在验证和自动化领域的进展。参与行业安全会议(例如 BlackHat、DEF CON、RSA)以保持信息灵通。
- 🗄️ 数据中心方法: 开始构建高质量的“人机行为差异”数据集。探索联邦学习,在保护隐私的同时实现协作数据智能。
- 👥 跨职能协作: 培养由 AI 工程师、安全研究员、产品经理和专家组成的团队。定期进行内部红队演练,并建立知识共享机制。
🎯 结语:验证的未来是无缝效率
验证码 25 年的历史揭示了一个循环:AI 创造 → 为防御 AI 设计验证码 → AI 绕过验证码 → 验证码升级,令人类沮丧 → 人类免费为 AI 训练 → AI 变得更强大……然而,LLM 的出现提供了一个范式转变。
借助智能的 AI 自动化基础设施,验证不再仅仅是一个障碍。它转变为一个**“信任膜”**,无缝地包裹着业务运营,静默感知风险,动态调整强度,并在安全与用户体验之间取得最佳平衡。
验证终极形式是**“无缝效率”**。这并非安全需求的消失,而是验证的无形集成。我们的目标是确保 90% 的合法用户永远不会感知到验证步骤,而 100% 的非授权自动化则面临经济上不可持续的成本。
作为全球领先的自动化验证码识别解决方案提供商,我们致力于通过技术创新消除业务流程中的摩擦。我们旨在构建一个更智能、更高效的自动化生态系统,赋能企业专注于核心业务增长,摆脱验证码的困扰。
提升您的业务效率。从今天开始。
合规声明: 本博客提供的信息仅供参考。CapSolver 致力于遵守所有适用的法律和法规。严禁以非法、欺诈或滥用活动使用 CapSolver 网络,任何此类行为将受到调查。我们的验证码解决方案在确保 100% 合规的同时,帮助解决公共数据爬取过程中的验证码难题。我们鼓励负责任地使用我们的服务。如需更多信息,请访问我们的服务条款和隐私政策。
更多

赋能企业自动化:大模型驱动的验证码识别基础设施,实现无缝业务流程与高效运营
探索如何利用大模型(LLM)驱动的 AI 自动化基础设施,革新验证码识别,提升业务流程效率,减少人工干预。通过先进的验证码解决方案,优化您的自动化运营。
Lucas Mitchell
27-Mar-2026

扩展大语言模型训练的数据收集:大规模解决CAPTCHAs
通过大规模解决验证码来扩展大语言模型训练的数据收集。探索用于AI模型的自动化策略,以构建高质量的数据集。

Aloísio Vítor
27-Mar-2026

如何在Vibium中无需扩展程序解决验证码(reCAPTCHA、Turnstile、AWS WAF)
学习如何使用 CapSolver API 在 Vibium 中解决 CAPTCHA。支持使用 JavaScript、Python 和 Java 的完整代码示例,无需浏览器扩展即可解决 reCAPTCHA v2/v3、Cloudflare Turnstile 和 AWS WAF。

Emma Foster
27-Mar-2026

如何在OpenBrowser中使用CapSolver解决CAPTCHA(AI代理自动化指南)
在OpenBrowser中使用CapSolver解决验证码。轻松为AI代理自动化reCAPTCHA、Turnstile等。
Emma Foster
26-Mar-2026

如何在HyperBrowser中使用CapSolver解决任何CAPTCHA(完整设置指南)
使用 CapSolver 在 HyperBrowser 中解决任何验证码。轻松自动化处理 reCAPTCHA、Turnstile、AWS WAF 等更多内容。

Ethan Collins
26-Mar-2026

解决验证码用于价格监控的人工智能代理:分步指南
学习如何使用CapSolver有效解决验证码,以用于价格监控的AI代理。本分步指南保证不间断的数据收集和增强的市场洞察力。
Ethan Collins
24-Mar-2026